OpenCV学习笔记(12)-二叉决策树
我们将具体讨论二叉决策树,他们是最常用的,且实现了机器学习库中大量的功能,因此将被作为指导性的例子来讲解.二叉决策树由LeoBreiman和他的同事提出.他们称之为"分类和回归树(CART)".OpenCV实现的就是"分类回归树".算法的要点是给树的每个节点定义一个衡量标准.比如:当我们拟合一个函数的时候,我们使用真实值和预测值的差的平方和,这就是衡量标准.算法的目地是使差的平方和最小.这就是衡量标准.算法的目的是使差的平方和最小.对于分类问题,我们定义一个度量,使得当一个节点的大多数值都属于同一类时,这个度量最小.三个最常用度量是:熵(entropy),吉尼系数(Giniindex)和错分类(misclassification),这些度量都会在本节中介绍.一旦我们定义了度量,二叉树搜寻整个特征向量,搜寻哪个特征和哪个阈值可以正确分类数据或正确拟合数据(在本书中称为是数据"纯净").根据惯例,我们说特征值大于这个阈值的数据为"真",被分配到左分支;其他的点放到右分支.从二叉树的每个节点递归使用这个过程直到数据都"纯净"了,或者节点里的数据样本数达到最小值.
随后会给出节点的不纯度i(N).我们首先需要两种情况来分析:回归和分类.
回归不纯度
回归或函数拟合中,节点不纯度仅仅是节点值y和数据值x的差的平方.我们需要最小化这个等式:
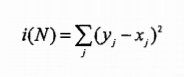
分类不纯度:
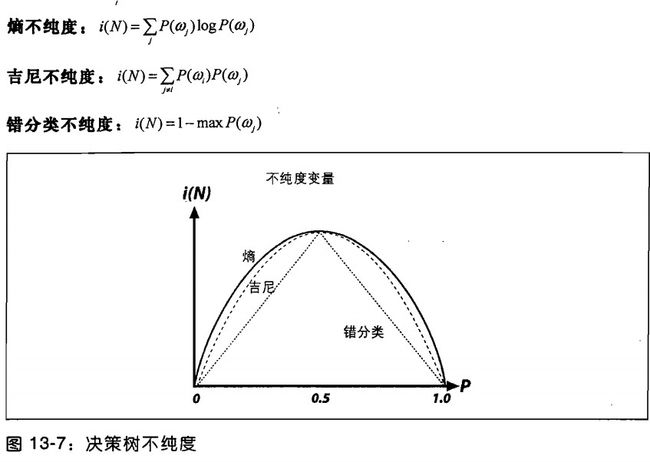
分类中,决策树经常使用熵不纯度,吉尼不纯度和错分类不纯度这三个度量中的某一个来衡量.这些方法中,我们使用P(ωj)来表示节点N中类别ωj所占的比例.不同方法中,不存度有一些细微的差别.吉尼不纯度经常用,所有的方法都努力是节点中的不纯度最小.图13-7显示了我们想要的最小化不纯度.
决策树可能是最常用的分类方法.因为他们执行简单,容易解释结果,适应不同的数据类型(包括类别数据,数据数据,未归一化的和混合数据),能够处理数据丢失,通过分裂的顺序能够给数据特征赋不同的重要性.决策树构成了其他算法的基础,比如boosting和随机数,我们会简单地介绍这些算法.
决策树的使用
下面描述怎样使用决策树.很多方法访问节点/改变分裂等.如想想要直到浙西细节,请参考用户手册.特别注意看类CvDTree{},训练类CvDTreeTrainData{},节点CvDTreeNode{}和分裂CvDTreeSplit{}.
我们用实例来介绍决策树.在路径.../opencv/samples/c下,mushroom.cpp文件对agaricuslepiota.data里的数据进行了决策树的分类.这个数据文件包含标签p和e(分别表示有毒和五毒),还有22个属性,每个属性只有一个字母.在mushroom.coo中,函数mushroom_read_database()从文件agaricuslepiota.data中读取数据.这个函数过于特殊,并不具有通用性,它只对三个数组进行了赋值:(1)浮点数组data[][],数组的行数是数据样本的数目,列数是特征的数目(这里是22),所有的特征都从类别字母转换为浮点数字;(2)单字节类型矩阵missing[][],用"true"或者"1"标识数据文件里的确实特征,缺失特征在数据文件里用问号表示,本数据的其他值为0;(3)浮点向量response[],里面包含有毒的字符"p"和五毒的字符"e"的对应浮点值.大多数情况下,可以写一个更通用的数据输入程序.现在我们讨论mushroom.cpp最主要的工作,也就是在main函数中被直接或者间接调用的部分.
训练树
为了训练树,我们首先填充树的参数结构体CvDTreeParams{};
struct CV_EXPORTS_W_MAP CvDTreeParams
{
CV_PROP_RW int max_categories;
CV_PROP_RW int max_depth;
CV_PROP_RW int min_sample_count;
CV_PROP_RW int cv_folds;
CV_PROP_RW bool use_surrogates;
CV_PROP_RW bool use_1se_rule;
CV_PROP_RW bool truncate_pruned_tree;
CV_PROP_RW float regression_accuracy;
const float* priors;
CvDTreeParams();
CvDTreeParams( int max_depth, int min_sample_count,
float regression_accuracy, bool use_surrogates,
int max_categories, int cv_folds,
bool use_1se_rule, bool truncate_pruned_tree,
const float* priors );
};在结构体中,max_categories这个值限制了特征类别取值数目,决策树会事先将这些类别聚类,使其可以测试不超过2max_categories-2中可能性.这个参数对有序的或者数字的特征没有影响,因为对于有序的或者数字的特征,算法仅仅需要找到分裂的阈值.类别个数超过max_categories的变量将自动聚类到max_categories个类别个数.这样,决策树每次测试只需要测试不多于max_categories个层.当这个参数被设置得比较小的时候,将减少计算的复杂度,但也损失了精确度.
其他参数的名称不言自明.最后一个参数priors非常重要.它设置了错分类的代价.这是说,如果第1个类别的代价是1,第2个类别的代价是10,则预测地2个类别出现一次错误则等于预测第1个类别出现10此错误.在这个程序中,我们判断有毒和无毒的蘑菇,所以我们惩罚把毒蘑菇认为无毒10于把无毒的蘑菇认为有毒.
训练决策树的方法如下,有两个函数:第一个为了直接使用决策树;第二个为了全体(用法如boosting)或森林(在随机数使用).
virtual bool train( const CvMat* trainData, int tflag,
const CvMat* responses, const CvMat* varIdx=0,
const CvMat* sampleIdx=0, const CvMat* varType=0,
const CvMat* missingDataMask=0,
CvDTreeParams params=CvDTreeParams() ); virtual bool train( CvDTreeTrainData* trainData, const CvMat* subsampleIdx );CvDTree* dtree;
CvMat* var_type;
int i, hr1 = 0, hr2 = 0, p_total = 0;
float priors[] = { 1, p_weight };
var_type = cvCreateMat( data->cols + 1, 1, CV_8U );
cvSet( var_type, cvScalarAll(CV_VAR_CATEGORICAL) ); // all the variables are categorical
dtree = new CvDTree;
dtree->train( data, CV_ROW_SAMPLE, responses, 0, 0, var_type, missing,
CvDTreeParams( 8, // max depth
10, // min sample count
0, // regression accuracy: N/A here
true, // compute surrogate split, as we have missing data
15, // max number of categories (use sub-optimal algorithm for larger numbers)
10, // the number of cross-validation folds
true, // use 1SE rule => smaller tree
true, // throw away the pruned tree branches
priors // the array of priors, the bigger p_weight, the more attention
// to the poisonous mushrooms
// (a mushroom will be judjed to be poisonous with bigger chance)
));
dtree->save("tree.xml","MyTree");
dtree->clear();
dtree->load(tree.xml","MyTree");
上面代码保存和加载了一个叫"tree.xml"的书文件.选项"MyTree"在tree.xml中标记了一个树.和机器学习中其他统计模式一样,使用save的时候并不能存储多个对象;多对象存储的时候要使用cvOpenFileStorage()和write().但是,load函数不一样,如果一个文件中存储了多个对象,它可以根据名称提取出对应的对象.
决策树的预测函数如下:
CvDTreeNode* predict( const CvMat* sample, const CvMat* missingDataMask=0,
bool preprocessedInput=false ) const;double r = dtree->prdeict(&sample,&mask)->value;
最后,我们调用vat_importance()得到初始特征的重要性,这个函数返回一个N*1的双精度(CV_64FC1)向量,向量包含每个特征的重要性,1代表最重要,0代表完全不重要.不重要的特征在二次训练中可以被排除(图13-2是变量重要性的图示)这个函数的调用如下:
const CvMat* var_importance = dtree->get_var_importance();
如....opencv/samples/c/mushroom.cpp文件所示,每个独立特征的重要性可以直接由下式访问:
double val = var_importance->data.db[i];
大多数用户只训练并使用决策树,但是高级用户或者研究人员可能想测试树节点,改变树节点或者改变分裂标准.可以参考OpenCV文档,获得.深入分析的重点是类结构CvDtree{},训练CvDTreeTrainDat{},节点结构CvDTreeNode{}和分裂结构CvDTreeSplit{}.
决策树结果
用前面的代码,我们可以从agaricus-Lepiota.data文件中学习蘑菇是有毒还是无毒.如果我们训练决策树而不经过修剪,它可以很好的学习数据,结构图如13-18所示.尽管完全的决策树可以很好地学习训练,也学习了噪声和错误.因此,它在实际数据中的效果可能并不好.这就是为什么OpenCV决策树和CART树需要包含一个附加的步骤来通过修剪树来达到复杂度和性能的平衡.其他的有些树通过在建立树的同事考虑复杂度,以把修剪融合到训练环节里面.但是在开发ML库的时候,发现先建立树再修剪(OpenCV是这样实现的)的效果胜于边建立树边修建好.
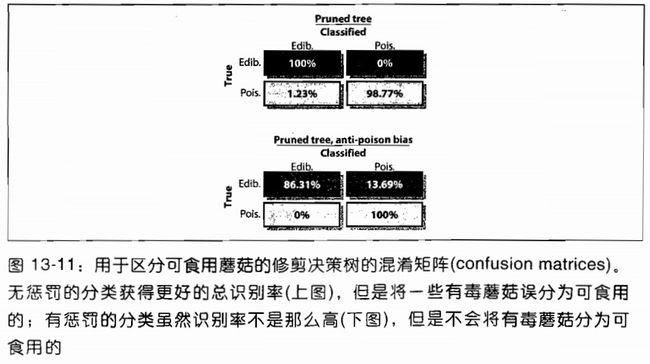
图13-9显示了一个在训练集上并不是非常好,但是在实际数据中会有更好的性能的树,因为它在过拟合和欠拟合中达到了平衡.但是这种分类器有一个缺点:尽管它在数据的总误差上获得比较好的性能,它仍有1.23%的概率将有毒的蘑菇判断为没有毒.可能我们希望得到一个性能略差,尽管会标记错很多没有毒的蘑菇,但是不会标记错有毒的蘑菇的分类器.这样的分类器可以通过故意歧视分类器或者故意歧视数据来得到.这种方法会给分类器的分类错误增加代价.在我们的例子中,我们认为错分为有毒蘑菇的代价很高,而错分无毒蘑菇的代价较小.OpenCV允许调整训练参数CvDTreeParams{}中prior来达到目的.我们也可以重复使用"坏"数据来加强prior的代价.重复使用"坏"数据暗中增加"坏"数据的权重.
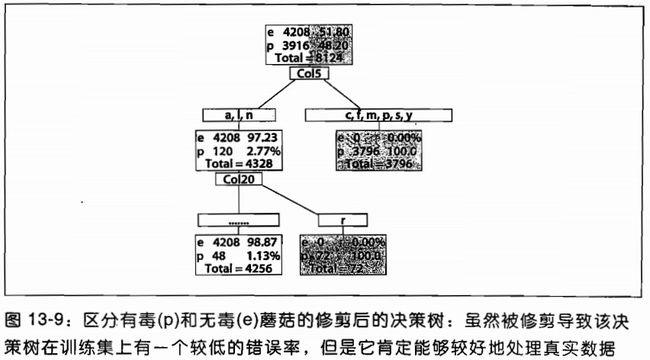
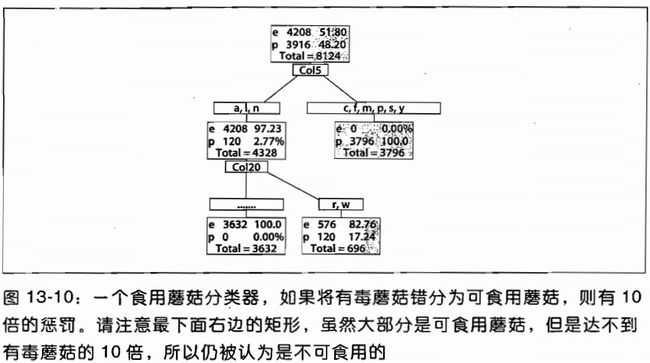
图13-10展示了一个给毒蘑菇分错了10倍权值的树.这个树以牺牲判断无毒蘑菇的准确率来使判断毒蘑菇完全正确."安全比犯错好".无偏见和有偏见的树混淆矩阵如图13-11所示.
最后我们好伦怎么利用决策树产生变量重要性,OpenCV的树分类器中包含变量重要性.变量重要性计数度量了每个变量对分类器性能的贡献.哪些特征丢弃后使性能下降越多,哪些特征就越重要.决策树可以直接通过数据的分裂来表示重要性:第一层一般会比第二层重要.分裂是重要性的有效指示,但它是以贪婪方式来实现的,即找到当前使数据最纯净的分裂.但有些时候,先做不重要的分裂会得到更好的效果,但是目前决策树不会这样做.毒蘑菇的变量重要性如图13-12所示,它包括无偏见的树和有偏见的树.可以看到变量重要性也与树的偏见有关.