【爬坑系列】之vxlan网络实现
linux 内核从3.7之后就内部集成了vxlan功能,所以可以使用linux内核提供的vxlan功能,经过配置创建vxlan网络。
而从Docker自Docker Engine 1.9之后,就自带overlay网络的驱动了,也才有了可以直接使用docker create network命令创建overlay类型的网络
在这里我们除了创建单纯的vxlan网络,我们可以手动模拟overlay驱动,利用namespace自己创建overlay网络,这里会遇到很多坑,但对于学习vxlan甚至是linux网络知识都很有帮助。
另外,受环境所限这里我只试验了点对点类型的vxlan网络,但对于理解vxlan往还是够用啦
大纲:
1,环境准备,
2,最基本的点对点vxlan网
3,多namespace下的点对点vxlan网
3.1入坑
3.2爬坑
3.3结论
环境准备
0,在某两家云服务供应商上买了2台计算云,centos 7,这样的环境稍显复杂,因为计算云的机器都是绑定的VIP,其自身接口的ip都是小网ip,互相不认识的小网ip......
master节点 minion节点
VIP: 188.x.x.113 ---中间网络------ 106.y.y.3
IP(eth0): 172.21.0.3 172.16.0.4
MAC(eth0): 52:54:00:6b:df:04 fa:16:3e:a8:1f:98
1,linux内核版本越高越好,如果不够,可以用如下命令进行升级
rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel install kernel-ml-devel kernel-ml -y
2, 安装必要的工具,比如
ln -s /var/run/docker/netns/ /var/run/netns
最基本的点对点vxlan网
所谓点对点网络,表示每个vtep只有一个伙伴,它只与这个伙伴建立一个隧道。
【实操】
master:
//创建一个vxlan类型的接口作为vtep,vxlan id即VNI为200,指定隧道的另一端ip为minion的VIP,建立隧道的物理接口为eth0
ip link add vxlan20 type vxlan id 200 dstport 4789 remote 106.y.y.3 dev eth0
ip addr add 10.20.1.2/24 dev vxlan20
ip link set vxlan20 up
minion:
ip link add vxlan20 type vxlan id 200 remote 188.x.x.113 dstport 4789 dev eth0 ip addr add 10.20.1.3/24 dev vxlan20 ip link set vxlan20 up
【验证】#ping 10.20.1.3 OK的,抓包也可以看到经过vxlan封装的报文
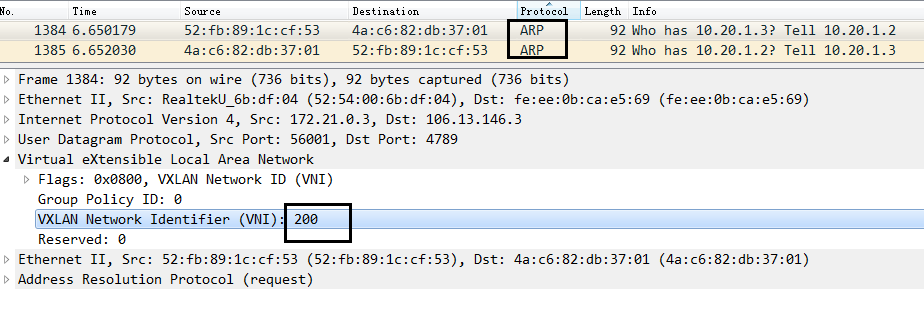

【解析】:
此种情况属于vtep之间的直接通信,arp包和icmp包都被vtep即vxlan20进行了vxlan封装。
这部分的实验是很有必要的,因为可以说明我的linux内核是支持vxlan。这很重要,因为在开始我使用的是namespace + veth pair方式搭建环境,但总是不通,查了好多资料都说是版本问题,所以我这才舍弃自己的虚拟机花钱购买了计算云,然后又是升级内核版本等等....
直到这种最简单方式的情况下发现是OK的,我才意识到,我解决问题的方向早就偏了....
多namespace下的点对点vxlan网
【配置】
master:

ip link add vxlan20 type vxlan id 100 remote 106.y.y.3 dstport 4789 dev eth0
ip link add br-vx2 type bridge //创建网桥
ip link add veth20 type veth peer name veth21 //创建一对veth pair
//br-vx网桥左手一只vxlan10接口,右手一只veth10接口,然后将网桥up起来
ip link set vxlan20 master br-vx2
ip link set vxlan20 up
ip link set dev veth20 master br-vx2
ip link set dev veth20 up
ip link set br-vx2 up
//创建一个新的namespace名叫ns100,将之前创建的veth pair中的另一端veth11,添加到该ns100中,并添加ip以及up起来
ip netns add ns200
ip link set dev veth11 netns ns200
ip netns exec ns200 ip addr add 10.20.0.20/24 dev veth21
ip netns exec ns200 ip link set dev veth21 up
ip netns exec ns200 ip link set lo up
minion:
ip link add vxlan20 type vxlan id 200 remote 188.x.x.113 dstport 4789 dev eth0
ip link add br-vx2 type bridge
ip link add veth20 type veth peer name veth21
ip link set vxlan20 master br-vx2
ip link set vxlan20 up
ip link set dev veth20 master br-vx2
ip link set dev veth20 up
ip link set br-vx2 up
ip netns add ns200
ip link set dev veth21 netns ns200
ip netns exec ns200 ip addr add 10.20.0.21/24 dev veth21
ip netns exec ns200 ip link set veth21 up
ip netns exec ns200 ip link set lo up
入坑>>>>>>>>>
【操作】:为什么不通能,为什么?
#ip netns exec ns200 ping 10.20.0.21 -c 3
PING 10.20.0.21 (10.20.0.21) 56(84) bytes of data.
--- 10.20.0.21 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2030ms
爬坑>>>>>>>>
【解析round1】:
根据目前学到的理论,我们知道数据的方向会如下图中红色箭头所示,于是我开始一步一步抓包
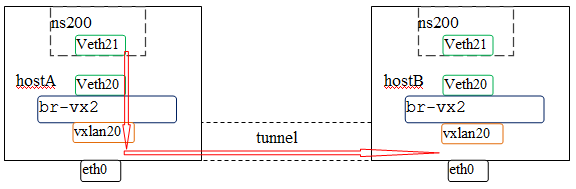
1,vxlan20接口抓包如下,arp有发出去且有收到应答,但是icmp包却有去无回

2,再次检查收发包情况,对比执行ping前后得到如下
[root@master ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-vx2 1450 341 0 0 0 0 0 0 0 BMRU
veth20 1500 998 0 0 0 278 0 0 0 BMRU
vxlan20 1450 279 0 0 0 204 0 0 0 BMRU
执行完ping操作, 即从ns200的veth21接口会发出来3个icmp包 + 1个arp包
[root@master ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-vx2 1450 346 0 0 0 0 0 0 0 BMRU
veth20 1500 1002 0 0 0 279 0 0 0 BMRU
vxlan20 1450 280 0 0 0 205 0 0 0 BMRU
解析:
veth20:接收4个包,其中3个icmp + 1个arp,发送1个arp请求
br-vx2:接收5个包 发送0个包
vxlan20:接收1个包,发送1个包,均为arp包,一个请求一个应答
水鬼子:不知道这里你有没有和我一样有个疑问,看过linux转发原理都知道,桥的一个接口接收到包之后会转发给桥上的其他接口,那么上面的发送接收到底表示什么含义呢,比如vxlan20接收的1个包是指接收来自veth20的转发,还是来自外网的应答?还有tcpdump这个工具,它到底抓的是哪个方向的数据包,他和netstat统计时打点的地方一样的么?接下来我会一步一步验证,非常繁琐,写下来只是为了给自己的记录,大家可以略过此段直接看结论。
0,预备知识:
http://ebtables.netfilter.org/br_fw_ia/br_fw_ia.html
很好的文章,看看在linu bridge中,ebtables和iptables都扮演了什么角色,这里截取核心的部分,如下图:
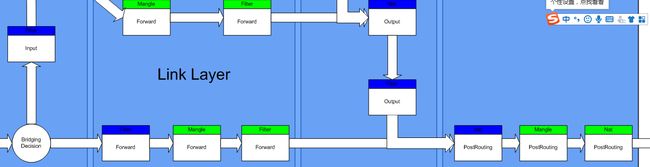
说明:
蓝色:ebtbales, 绿色:ibtables
桥上的接口收到数据后,进行bridge decision,如果目的地是给自己,上送走filter表的input链;否则桥内部洪泛,洪泛之前要走ebtables:filter的forward表,iptables:mangle表的forward表和filter表的forward表。
操作1:br-vx2接口是用来和上层协议栈交互的,掐断上报的路,看看什么结果
[root@master ~]# ebtables -L
Bridge table: filter
Bridge chain: INPUT, entries: 1, policy: ACCEPT
-j DROP //上送的数据都drop掉,即阻断上送的路
再ping,得到如下:
[root@master ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-vx2 1450 346 0 0 0 0 0 0 0 BMRU
veth20 1500 1006 0 0 0 280 0 0 0 BMRU
vxlan20 1450 281 0 0 0 206 0 0 0 BMRU
小小结1:br-vx2确实表示用于上报,这个和网桥同名的接口可以看做是通向内核协议栈的接口。
操作2:我删除ebtables中的配置,然后ping一个未知的ip,让其得不到arp应答
# ip netns exec ns200 ping 10.20.0.22 -c 3
PING 10.20.0.22 (10.20.0.22) 56(84) bytes of data.
[root@master ~]# tcpdump -i br-vx2
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on br-vx2, link-type EN10MB (Ethernet), capture size 262144 bytes
20:02:41.886373 ARP, Request who-has 10.20.0.22 tell 10.20.0.20, length 28
20:02:42.931276 ARP, Request who-has 10.20.0.22 tell 10.20.0.20, length 28
20:02:43.955364 ARP, Request who-has 10.20.0.22 tell 10.20.0.20, length 28
br-vx2 1450 349 0 0 0 0 0 0 0 BMRU
vxlan20 1450 281 0 0 0 209 0 0 0 BMRU
解析:为什么是ping -c 3的时候br-vx2 接收到5个包呢?其中3(icmp)+1(arp请求)是veth20通过桥内部转发给我的,那一个是什么?我猜测是接收过来的arp应答
为了验证这个结论,经过上述操作发现netstat的数据中,br-vx2只增加了3个(arp请求)
小小结:反向证明上面多出的1个包是arp应答。另外netstat统计时,RX-OK表示的是接口收到的数据包,这个数据包既可以是请求也可以是应答,只要是我接收到的。
小结:
结合上述实验加上我又看了linux的bridge部分的源码,以及netstat工具的源码,可以得到如下结论:
1,每一个bridge都有一个同名接口,可以将该接口看做是内核协议栈对外(网桥)的出入口。
2,netstat -i命令统计的数据是驱动层面的,将驱动中记录的数据提取出来进行显示,rx表示ingress,rx表示egress
---数据本来就在那里,我去取
3,tcpdump -i x是应用层面的,根据指令在不同模块上注册socket,数据在流动过程中发现有tcpdump的注册则deliver一份给他
4,二者的区别,netstat的统计更底层,所以当你发现netstat的统计数据和tcpdump不同的时候,就可以大概猜出来数据是在哪里被丢掉的。
【解析round2】:
在上面的例子可以看出来arp可以接收到应答,但是icmp报文为什么就不行呢?有两条线索
1,tcpdump -i vxlan20有看到请求发出来
2,netstat -i 发现,数据没有从vxlan10接口真的出去
那么数据肯定再这中间被drop掉了,然后看看这中间经历了什么,没错,就是iptables和ebtables一共经历了6个链,那好,我一个一个表查,通过向链里添加匹配条件来跟踪数据包都走到哪里。
最终,我发现原来这里给drop掉了
[root@master ~]# iptables -LFORWARD -v
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 icmp -- any any anywhere 10.20.0.21 ----这个是我后加的匹配条件,原先是没有的
开始ping
[root@master ~]# iptables -LFORWARD -v
Chain FORWARD (policy DROP 3 packets, 252 bytes) ----是的,被drop掉了
pkts bytes target prot opt in out source destination
3 252 icmp -- any any anywhere 10.20.0.21
986 82824 DOCKER-USER all -- any any anywhere anywhere
986 82824 DOCKER-ISOLATION-STAGE-1 all -- any any anywhere anywhere
0 0 ACCEPT all -- any docker0 anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- any docker0 anywhere anywhere
0 0 ACCEPT all -- docker0 !docker0 anywhere anywhere
0 0 ACCEPT all -- docker0 docker0 anywhere anywhere
0 0 ACCEPT all -- any docker_gwbridge anywhere anywhere ctstate RELATED,ESTABLISHED
0 0 DOCKER all -- any docker_gwbridge anywhere anywhere
结论>>>>>>>>
仔细看,filter表的FORWARD链,除了docker相关的链匹配上了(这两个链直接return的,这里就不展示了)但都是什么也没做,也就是说走的是缺省策略?excuse me?DROP?是的,该链的缺省策略时DROP,想死的心都有了,马上改
[root@master ~]# iptables -P FORWARD ACCEPT
[root@minion ~]# iptables -P FORWARD ACCEPT
[root@master ~]# ip netns exec ns200 ping 10.20.0.21 -c 3
PING 10.20.0.21 (10.20.0.21) 56(84) bytes of data.
64 bytes from 10.20.0.21: icmp_seq=1 ttl=64 time=16.5 ms
64 bytes from 10.20.0.21: icmp_seq=2 ttl=64 time=8.49 ms
64 bytes from 10.20.0.21: icmp_seq=3 ttl=64 time=8.43 ms
--- 10.20.0.21 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 8.438/11.156/16.534/3.802 ms
[root@master ~]#
注:频繁操作网桥,要设置如下命令,即让网桥的记忆为0,否则会因为有记忆让配置的策略暂时不生效(缺省5分钟才生效)
]# brctl setageing br-vx2 0
水鬼子:网上说在试验前要关闭防火墙,然后我就用如下命令关闭了,还关闭了selinux,但是事实证明iptables还是生效的,也许这里面又什么原理等待我去研究,但是已经管不了那么多了TOT
[root@master ~]# systemctl stop firewalld.service
[root@master ~]# systemctl disable firewalld.service
[root@master ~]# firewall-cmd --state
not running
-------------------------------end---------------------------------------------------