OpenVSwitch 硬件加速浅谈
本文首发SDNLAB。
现代的虚拟化技术使得开发和部署高级网络服务变得更加简单方便。基于虚拟化的网络服务,具有多样性,低成本,易集成,易管理,低持有成本等优点。而虚拟交换机已经成为了一个高度虚拟化环境不可缺少的一部分。OpenVSwitch是所有虚机交换机中的佼佼者,广泛被各种SDN方案采用。
OpenVSwitch kernel datapath
--
OpenVSwitch是一个实现了OpenFlow的虚拟交换机,它由多个模块组成。主要有位于用户空间的ovsdb-server和ovs-vswitchd进程,和位于内核空间的OVS datapath组成。在一个SDN架构中,Controller将各种网络拓扑,网络功能转换成OVS的数据和OpenFlow规则,分别下发给ovsdb-server和ovs-vswitchd进程,OpenFlow规则可以通过ovs-ofctl dump-flows查看。
网络数据的转发,都是由位于内核空间的OVS datapath完成。用户空间和内核空间的信息是怎么同步的?对于一个网络数据流,第一个数据包到达OVS datapath,这个时候的datapath没有转发信息,并不知道怎么完成转发。接下来OVS datapath会查询位于用户空间的ovs-vswitchd进程。ovs-vswitchd进程因为有OpenFlow信息,可以根据OpenFlow规则完成match-action操作,也就是从一堆OpenFlow规则里面匹配网络数据包对应的规则,根据这些规则里的action实现转发。
这样第一个数据包就完成了转发。与此同时,ovs-vswitchd会通过netlink向OVS datapath写入一条(也有可能是多条)转发规则,这里的规则不同于OpenFlow规则,可以通过ovs-dpctl dump-flows查看。这样,同一个网络数据流的后继网络数据包到达OVS datapath时,因为已经有了转发规则,datapath就可以直接完成转发,不再需要向ovs-vswitchd查询。

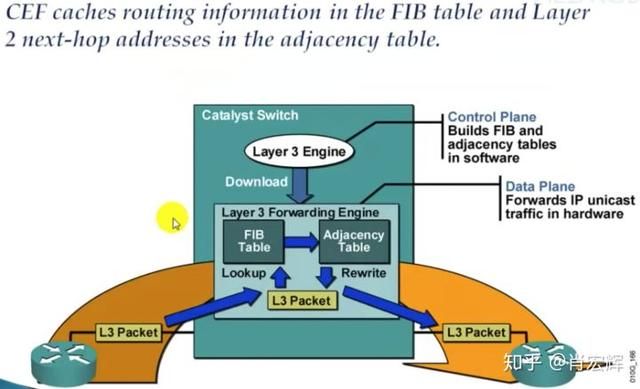
通过ovs-vswitchd查找OpenFlow实现转发的路径称为slow-path,通过OVS datapath直接转发的路径称为fast-path。OVS的设计思路就是通过slow-path和fast-path的配合使用,完成网络数据的高效转发。这种设计思想类似于传统的硬件网络设备。例如Cisco CEF架构,也是分成了两层,Control Plane存储了当前设备的全部转发信息(RIB),而Data Plane会存储实际的转发信息(FIB)。网络数据的转发在Data Plane完成,当Data Plane没有相应的FIB,会向上查询RIB进而构建FIB。
OpenVSwitch kernel datapath,实际上是在通用的硬件&软件上实现了专用网络设备的功能。优点在最开始说过了,但是这种实现也有自己的缺点。
硬件交换机因为有专门的转发硬件,可以保证任意时间都有一定的资源用于转发。但是OVS datapath在操作系统内核空间实现转发,本质上是通过操作系统内的几个进程来完成工作。操作系统会像对待其他进程一样,将CPU的部分时间片,而不是整个CPU分配给虚拟交换机,内存也需要受操作系统的管理,这就存在资源抢占的可能。所以,虚拟交换机并不能保证在需要转发网络数据的时候一定占有资源。
另一方面,因为操作系统本身的设计,需要经过硬中断,软中断,内核空间和用户空间的切换来完成网络数据的传输,通过内核进行转发使得网络数据在操作系统内的路径也很长。
所以现在的共识是,基于内核实现的虚拟交换机,会对网络性能(throughput,latency,PPS等)带来额外的损耗。这是虚拟交换机不可回避的问题。OVS kernel datapath多用于一些对网络性能要求不高的场合。
OpenVSwitch DPDK
--
DPDK(Data Plane Development Kit)本身是个独立的技术,OpenVSwitch在2012年提供了对DPDK的支持。
DPDK的思路是,绕过操作系统内核,在用户空间,通过PMD(Poll Mode Driver)直接操作网卡的接收和发送队列。在网络数据的接收端,PMD会不断的轮询网卡,从网卡上收到数据包之后,会直接通过DMA将其传输到预分配的内存中,同时更新接收队列的指针,这样应用程序很快就能感知收到数据包。DPDK绕过了大部分中断处理和操作系统的内核空间,大大缩短了网络数据在操作系统内的路径长度。
另一方面,因为PMD采用了轮询的方式与网卡交互,DPDK要独占部分CPU和内存,这样在任意时间都有一定的资源用于网络转发,避免了因为操作系统调度带来的资源抢占的问题。

因为DPDK绕过了内核空间,OVS-DPDK的datapath也存在于用户空间,采用如下图所示。对于SDN controller来说,因为连接的是ovs-vswitchd和ovsdb-server,所以感觉不到差异。

DPDK针对主机网络虚拟化的问题,提出了有效的解决方案。基于DPDK的网络方案,能大幅提升网络性能,并且已经在一些对网络性能有要求的场合使用,例如NFV。
不过,虽然DPDK在一定程度上解决了性能的问题,并且DPDK社区在不断的进行优化,但是DPDK也有其自身的问题。首先,DPDK没有集成在操作系统中,使用DPDK就需要额外的安装软件,这增加了维护成本。其次,绕过了Linux内核空间,也就是绕过了网络协议栈,这使得基于DPDK的应用更难调试和优化,因为大量的基于Linux kernel网络调试监控工具在DPDK下不可用了。第三个问题,DPDK独占了部分CPU和内存,这实际上分走了本该用来运行应用程序的资源,最直观的感受是,使用了DPDK之后,主机可以部署的虚机数变少了。
OpenVSwitch Hardware offload
--
OpenVSwitch硬件卸载是近几年才提出的方案,到目前为止并不完全成熟。
Linux TC(Traffic Control)Flower
--
要介绍OVS硬件卸载,必须要从TC说起。TC在Linux Kernel 2.2版本开始提出,并在2.4版本(2001年)完成。最初的Linux TC是为了实现QoS[1],当然TC现在仍然有QoS的功能。它在netdev设备的入方向和出方向增加了挂载点,进而控制网络流量的速度,延时,优先级等。Linux TC在整个Linux Kernel Datapath中的位置如下图所示:

随后,TC增加了Classifier-Action子系统[2],可以根据网络数据包的报头识别报文,并执行相应的Action。与其他的Classifier-Action系统,例如OpenFlow,不一样的是,TC的CA子系统并不只是提供了一种Classifier(识别器),而是提供了一个插件系统,可以接入任意的Classifier,甚至可以是用户自己定义的Classifier。
在2015年,TC的Classifier-Action子系统增加了对OpenFlow的支持[3],所有的OpenFlow规则都可以映射成TC规则。随后不久,OpenFlow Classifier又被改名为Flower Classifier。这就是TC Flower的来源。
Linux TC Flower hardware offload
--
在2011年,Linux内核增加了基于硬件QoS的支持[4]。因为TC就是Linux内实现QoS的模块,也就是说Linux增加了TC的硬件卸载功能。在2016年,Linux内核又增加了对TC Classifier硬件卸载的支持,但是这个时候只支持了u32类型的Classifier(与TC Flower并列的,但是历史更悠久的一种Classifier)。在4.9~4.14内核,Linux终于增加了对TC Flower硬件卸载的支持。也就是说OpenFlow规则有可能通过TC Flower的硬件卸载能力,在硬件(主要是网卡)中完成转发。
TC Flower硬件卸载的工作原理比较简单。当一条TC Flower规则被添加时,Linux TC会检查这条规则的挂载网卡是否支持并打开了NETIF_F_HW_TC标志位,并且是否实现了ndo_steup_tc(TC硬件卸载的挂载点)。如果都满足的话,这条TC Flower规则会传给网卡的ndo_steup_tc函数,进而下载到网卡内部[5]。
网卡的NETIF_F_HW_TC标志位可以通过ethtool来控制打开关闭:
# ethtool -K eth0 hw-tc-offload on
# ethtool -K eth0 hw-tc-offload off
同时,每条规则也可以通过标志位来控制是否进行硬件卸载。相应的标志位包括以下:
- TCA_CLS_FLAGS_SKIP_HW:只在软件(系统内核TC模块)添加规则,不在硬件添加。如果规则不能添加则报错。TCA_CLS_FLAGS_SKIP_SW:只在硬件(规则挂载的网卡)添加规则,不在软件添加。如果规则不能添加则报错。默认(不带标志位):尝试同时在硬件和软件下载规则,如果规则不能在软件添加则报错。
通过TC命令查看规则,如果规则已经卸载到硬件了,可以看到 in_hw标志位。
OVS-TC
--
OpenVSwitch在2018年增加了对TC Flower的支持,结合前面的描述,OVS的datapath现在有卸载到网卡的可能了。
前面说过,TC Flower规则现在可以下发到网卡上,相应的网卡上也会有一个虚机交换机。Mellanox称这个虚拟交换机为eSwitch。OVS初始化的时候,会向eSwitch下发一条默认的规则,如果网络包匹配不了任何其他规则,则会被这条默认规则匹配。这条规则的action就是将网络数据包送到eSwitch的管理主机,也就是说送到了位于Linux kernel的datapath上。如果这个网络数据包是首包的话,那根据前面的描述,在kernel的OVS datapath会继续上送到位于用户空间的ovs-vswitchd。因为ovs-vswitchd中有OpenFlow规则,ovs-vswitchd还是可以完成转发。不一样的地方是,ovs-vswitchd会判断当前数据流对应的规则能否offload(卸载)到网卡。如果可以的话,ovs-vswitchd会调用通过TC接口将flow规则下发至硬件。这样,同一个数据流的后继报文,可以直接在网卡的eSwitch中完成转发,根本不需要走到主机操作系统来。Datapath规则的aging(老化)也是由ovs-vswitchd轮询,最终通过TC接口完成删除。Datapath的变化如下所示。

在OVS-TC中,严格来说,现在Datapath有三个,一个是之前的OVS kernel datapath,一个是位于Kernel的TC datapath,另一个是位于网卡的TC datapath。位于kernel的TC datapath一般情况下都是空的,它只是ovs-vswitchd下发硬件TC Flower规则的一个挂载点。

使用OVS-TC方案,可以提供比DPDK更高的网络性能。因为,首先网络转发的路径根本不用进操作系统,因此变的更短了。其次,网卡,作为专用网络设备,转发性能一般要强于基于通用硬件模拟的DPDK。另一方面,网卡的TC Flower offload功能,是随着网卡驱动支持的,在运维上成本远远小于DPDK。
但是OVS-TC方案也有自己的问题。首先,它需要特定网卡支持,不难想象的是,支持这个功能的网卡会更贵,这会导致成本上升,但是考虑到不使用DPDK之后释放出来的CPU和内存资源,这方面的成本能稍微抵消。其次,OVS-TC功能还不完善,例如connection track功能还没有很好的支持。第三,这个问题类似于DPDK,因为不经过Linux kernel,相应的一些工具也不可用了,这使得监控难度更大。
最后--
本文介绍了OVS的三种datapath实现,并且着重描述了OVS-TC。三种实现中,OVS kernel最稳定,功能最全,相应的配套工具也最多,缺点就是性能较差,在对网络性能没有特殊要求的场合,OVS kernel还是首选;OVS DPDK能在一定程度上提升网络性能,并且对硬件没有依赖,但是需要占用主机的资源,并且需要有一定的维护成本;OVS-TC具有最好的网络性能,但是目前不太成熟,并且依赖特定的网卡,不过个人认为这是一个比较好的发展方向。
参考-
[1] http://tldp.org/HOWTO/Traffic-Control-HOWTO/overview.html#o-what-is
[2] https://people.netfilter.org/pablo/netdev0.1/papers/Linux-Traffic-Control-Classifier-Action-Subsystem-Architecture.pdf
[3] https://lwn.net/Articles/638585/
[4] https://lwn.net/Articles/420509/
[5] https://www.netdevconf.org/2.2/papers/horman-tcflower-talk.pdf
[6] https://netdevconf.org/1.2/papers/efraim-gerlitz-sriov-ovs-final.pdf
本文转自知乎:肖宏辉
网络/OpenStack/SDN/NFV搬运工