Python网络爬虫(五)爬取教务系统之动态验证码
目录
- 一、难点:动态密码验证登陆
- 二、爬取重交大cqjtu学生成绩
- (一)间接登录,获取html
- (二)cqjtu学生成绩From表单分析
- (三)re表达式筛选信息
- 1. 筛选id
- 2. 筛选本学期(2018-2019-1)成绩
- 三、总结
一、难点:动态密码验证登陆
解决思路:
1、获取图片,手动输入;
2、通过图像识别、电脑验证测试:爬取 带验证码登录的网站内容
(不稳定,不是本文主要讨论,采用方法一)
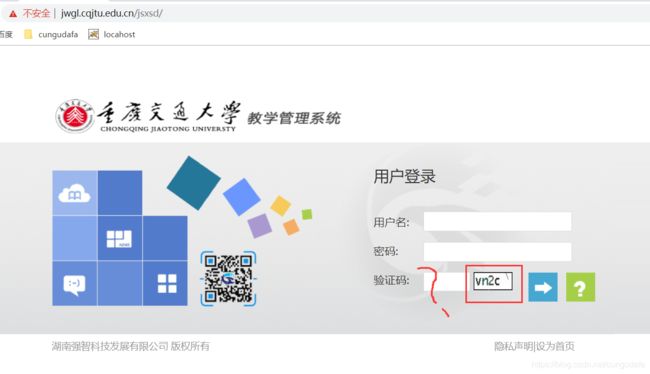
- 进入
cqjtu登陆页面:http://jwgl.cqjtu.edu.cn/jsxsd/ - 点击
F12找到我们需要的部分:用户名、密码、验证码,提交按钮
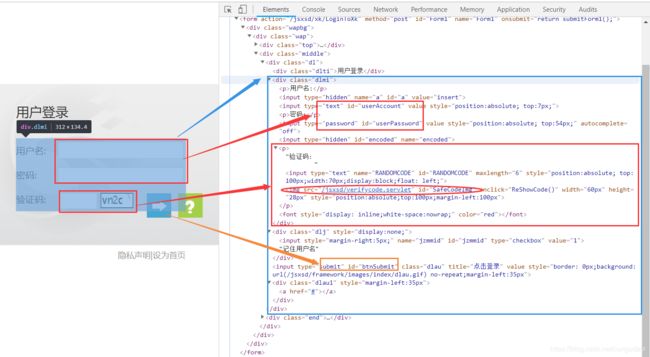
1、 通过审核元素观察到验证码的地址是:http://jwgl.cqjtu.edu.cn/jsxsd/verifycode.servlet?t=0.7383512709738249
每点击一次验证码,t=后面数字都会改变

2、 网页登陆查看post数据内容:http://jwgl.cqjtu.edu.cn/jsxsd/xk/LoginToXk

点击查看LoginToXk:(我们需要的:Request URL,Request Headers(注意:Cookie在变化),encode)
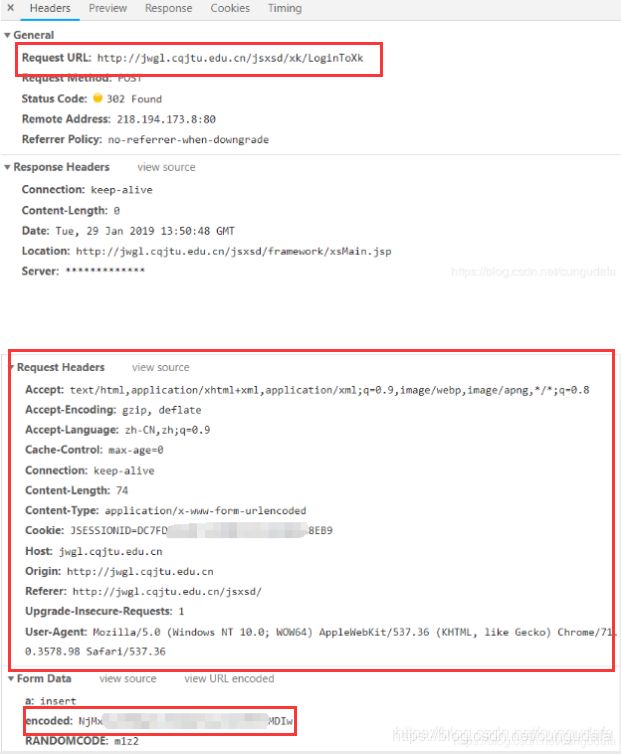
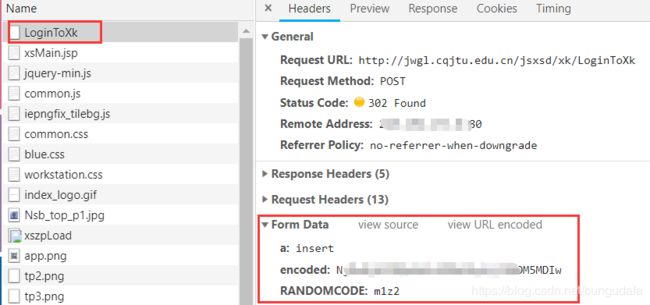
3、 获取提交的数据,找到参数,我们发现表单数据。但数据与我们平时看到的表单数据不一样。这是经过base64加密的数据。给出一个:base4破解教程,(这里是一个难点处,我们通过间接登录,简化这一步骤)
4、 模拟登陆test (获取:Cookie加密密码)
这是教学周历:(Request URL不同了,但Request Headers还是没变,这里是因为保持'Connection': 'keep-alive',因此我们就可以第一次访问时登录即可,后面不用再登录。)
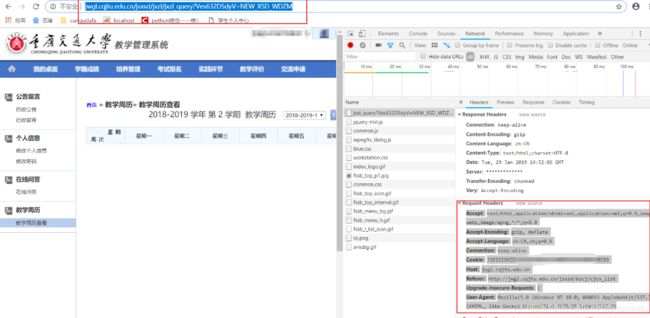
源码:(写入你访问成功后的请求Request Headers码,保持'Connection': 'keep-alive',只用换login_url就可以访问多页面了)
import requests
import base64
username = input("请输入账号:")
password = input("请输入密码:")
jiema = username + password # 解码
encodestr = str(base64.b64encode(jiema.encode('utf-8')), 'utf-8')
print(encodestr)
encoded = encodestr[0:12] + '%%%' + encodestr[12:] # 写成表单数据的格式,将账号与密码用%%%分开
print(encoded)
login_url = 'http://jwgl.cqjtu.edu.cn/jsxsd/jxzl/jxzl_query?Ves632DSdyV=NEW_XSD_WDZM'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'JSESSIONID=*****************************',#换成你成功登录密码,会刷新
'Host': 'jwgl.cqjtu.edu.cn',
'Referer': 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
data = {'encoded': encoded}
html = requests.post(url=login_url, headers=headers, data=data)
print(html.text)

这里是复制的我们网页登陆成功的*****************密码,间接登陆成功!
其实这里还是没有实现自动识别验证码,或者下载验证码图片,再手动输入;
后面补充学习一下:Python Scrapy 验证码登录处理
就可以把******************这一串破解出来啦!
二、爬取重交大cqjtu学生成绩
(一)间接登录,获取html
保存网页数据到txt文档中,进行分析
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests
xscj_url = 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'JSESSIONID=****************************',
'Host': 'jwgl.cqjtu.edu.cn',
'Referer': 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
data2 = {
'kksj': '2018-2019-1', # 选取本学期
'kcmc': '',
'kcxz': '',
'xsfs': 'all',
}
html = requests.post(url=xscj_url, headers=headers, data=data2)
try:
# 读写文件
with open(r"cjcx_list.txt", 'a+', encoding='utf-8') as f:
f.write(str(html.text)) # 记录全部评论
f.close()
print("成功")
except Exception as e:
print("失败")
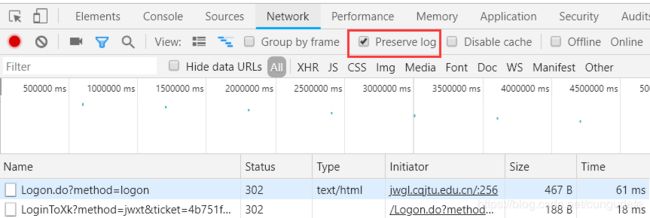
(二)cqjtu学生成绩From表单分析
(Chorme浏览器)
成绩查询url: http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list
tips:勾选
Preserve log不会刷新之前的Network请求
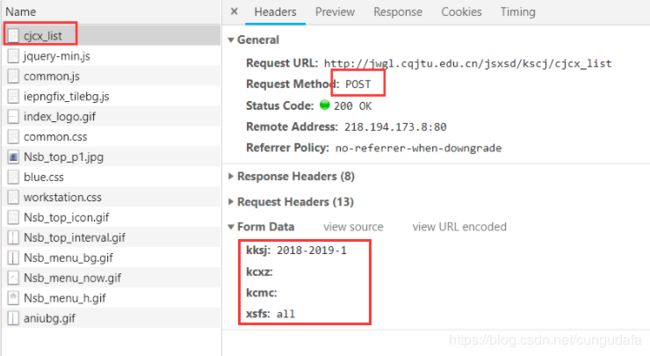
-
Get成绩url返回的Data表:
(kksj(教学时间)、kcxz(课程性质)、kcmc(课程名称)、xsfs(学生分数))
-
Get成绩结构(我们需要的内容在
... re正则表达式分析)
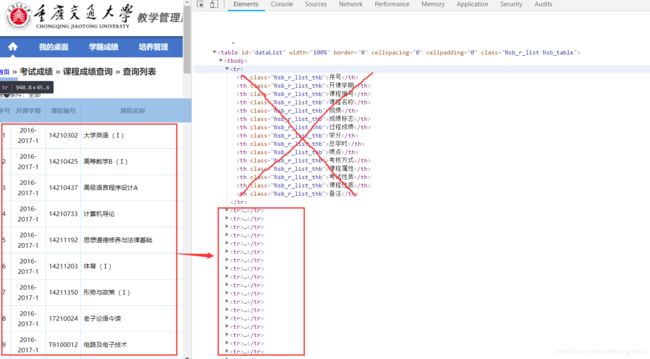

-
获取id:
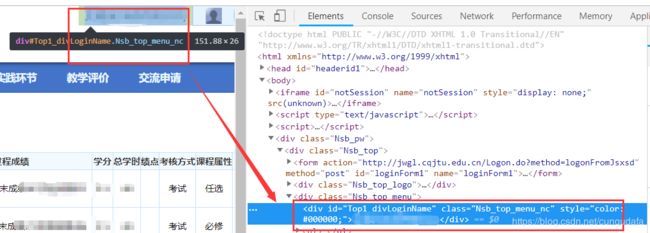
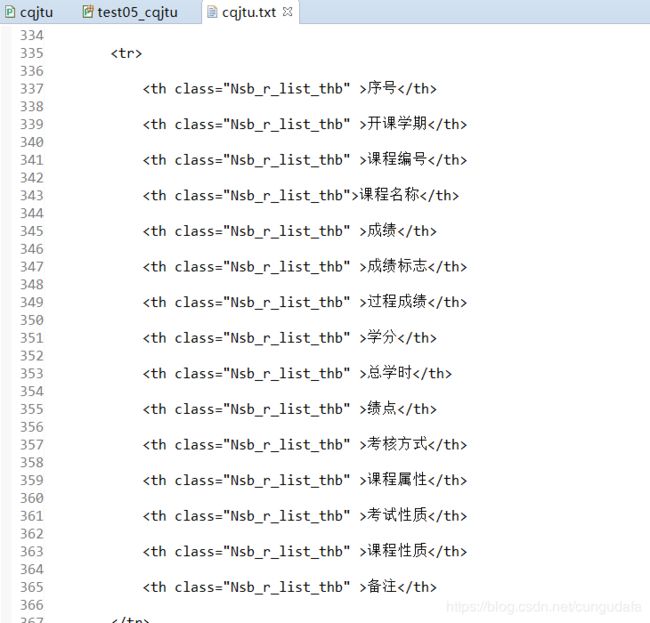
(三)re表达式筛选信息
1. 筛选id
目的:打印出姓名和学号
举例:

源码:
# -*- coding:UTF-8 -*-
import re
f = open("cqjtu.txt", "r", encoding='UTF-8') # 设置文件对象
html = f.read() # 将txt文件的所有内容读入到字符串str中
f.close() # 将文件关闭
# 匹配数据的正则表达式
nameRe = re.compile(
r'''''')
# 匹配网页对应的标题数据
name = nameRe.findall(html)
print(name)
2. 筛选本学期(2018-2019-1)成绩
目标 :计算本学期总学分,绩点
分析From表单:
总学分:成绩之和;绩点:(学分*绩点)/


1获取html:
源码:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests
xscj_url = 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'JSESSIONID=***************************',
'Host': 'jwgl.cqjtu.edu.cn',
'Referer': 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
data2 = {
'kksj': '2018-2019-1', # 选取本学期
'kcmc': '',
'kcxz': '',
'xsfs': 'all',
}
html = requests.post(url=xscj_url, headers=headers, data=data2)
try:
# 读写文件
with open(r"cjcx_list.txt", 'a+', encoding='utf-8') as f:
f.write(str(html.text)) # 记录全部评论
f.close()
print("成功")
except Exception as e:
print("失败")
查看了一下我们的教务系统,用re正则的话不好筛,不好筛(后面筛选对象是保存的txt,不过我思考了一下,原html也是可以用正则表达式处理的!)~

2滤除html标签
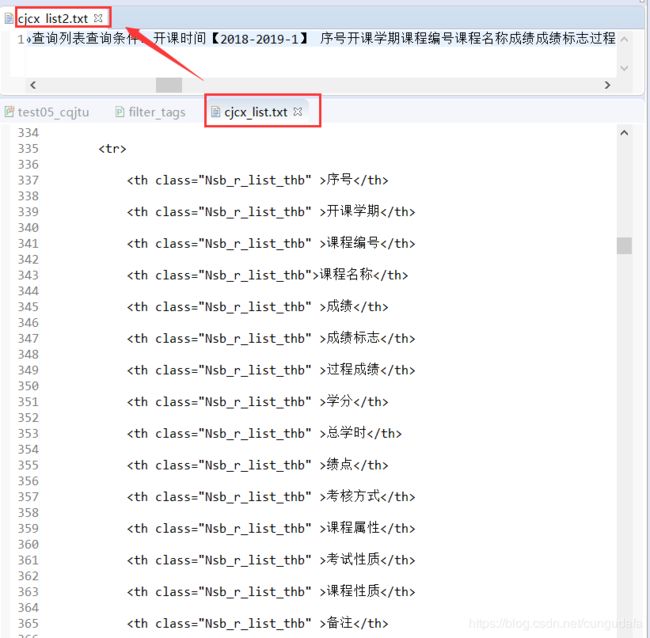
import re
# 过滤HTML中的标签
# 将HTML中标签等信息去掉
#@param htmlstr HTML字符串.
def filter_tags(htmlstr):
# 先过滤CDATA
re_cdata = re.compile('//]*//\]\]>', re.I) # 匹配CDATA
re_script = re.compile(
'<\s*script[^>]*>[^<]*<\s*/\s*script\s*>', re.I) # Script
re_style = re.compile(
'<\s*style[^>]*>[^<]*<\s*/\s*style\s*>', re.I) # style
re_br = re.compile('' ) # 处理换行
re_h = re.compile(']*>') # HTML标签
re_comment = re.compile('') # HTML注释
s = re_cdata.sub('', htmlstr) # 去掉CDATA
s = re_script.sub('', s) # 去掉SCRIPT
s = re_style.sub('', s) # 去掉style
s = re_br.sub('', s) # 将br转换为换行
s = re_h.sub('', s) # 去掉HTML 标签
s = re_comment.sub('', s) # 去掉HTML注释
# 去掉多余的空行
blank_line = re.compile('\n+')
s = blank_line.sub('', s)
blank_line_l = re.compile('\n')
s = blank_line_l.sub('', s)
blank_kon = re.compile('\t')
s = blank_kon.sub('', s)
blank_one = re.compile('\r\n')
s = blank_one.sub('', s)
blank_two = re.compile('\r')
s = blank_two.sub('', s)
blank_three = re.compile(' ')
s = blank_three.sub('', s)
s = replaceCharEntity(s) # 替换实体
return s
# 替换常用HTML字符实体.
# 使用正常的字符替换HTML中特殊的字符实体.
# 你可以添加新的实体字符到CHAR_ENTITIES中,处理更多HTML字符实体.
#@param htmlstr HTML字符串.
def replaceCharEntity(htmlstr):
CHAR_ENTITIES = {'nbsp': ' ', '160': ' ',
'lt': '<', '60': '<',
'gt': '>', '62': '>',
'amp': '&', '38': '&',
'quot': '"', '34': '"', }
re_charEntity = re.compile(r'&#?(?P\w+);' )
sz = re_charEntity.search(htmlstr)
while sz:
entity = sz.group() # entity全称,如>
key = sz.group('name') # 去除&;后entity,如>为gt
try:
htmlstr = re_charEntity.sub(CHAR_ENTITIES[key], htmlstr, 1)
sz = re_charEntity.search(htmlstr)
except KeyError:
# 以空串代替
htmlstr = re_charEntity.sub('', htmlstr, 1)
sz = re_charEntity.search(htmlstr)
return htmlstr
def repalce(s, re_exp, repl_string):
return re_exp.sub(repl_string, s)
if __name__ == '__main__':
f = open("cjcx_list.txt", "r", encoding='UTF-8') # 设置文件对象
html = f.read() # 将txt文件的所有内容读入到字符串str中
f.close() # 将文件关闭
words = filter_tags(html) # 过滤标签
try:
# 读写文件
with open(r"cjcx_list2.txt", 'a+', encoding='utf-8') as f:
f.write(words) # 记录全部评论
f.close()
print("成功")
except Exception as e:
print("失败")
3筛选专业课成绩
仔细看了一下,课程设计与专业课也没有做区分,就只是用课程编号来排列的,我们后面写正则时需要处理一下:
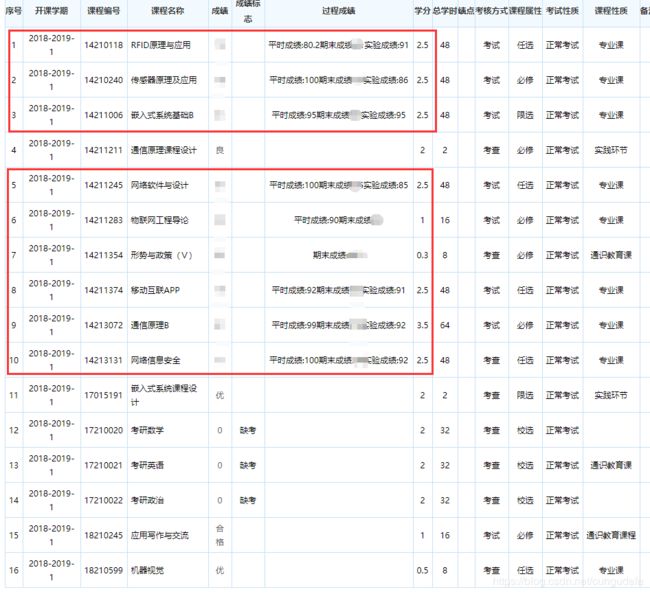
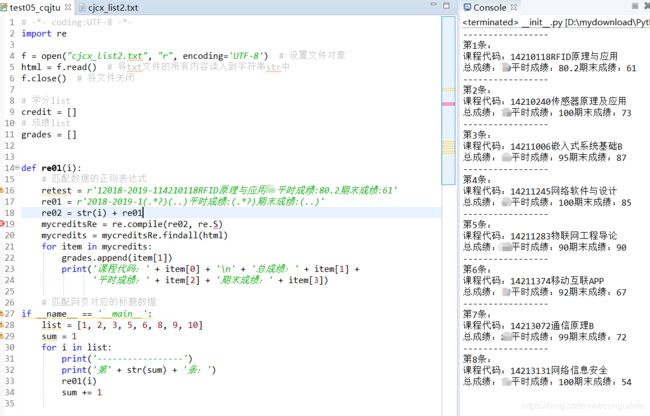
# -*- coding:UTF-8 -*-
import re
f = open("cjcx_list2.txt", "r", encoding='UTF-8') # 设置文件对象
html = f.read() # 将txt文件的所有内容读入到字符串str中
f.close() # 将文件关闭
# 学分list未实现统计
credit = []
# 成绩list
grades = []
def re01(i):
# 匹配数据的正则表达式
retest = r'12018-2019-114210118RFID原理与应用70平时成绩:80.2期末成绩:61'
re01 = r'2018-2019-1(.*?)(..)平时成绩:(.*?)期末成绩:(..)'
re02 = str(i) + re01
mycreditsRe = re.compile(re02, re.S)
mycredits = mycreditsRe.findall(html)
for item in mycredits:
grades.append(item[1])
print('课程代码:' + item[0] + '\n' + '总成绩:' + item[1] +
'平时成绩:' + item[2] + '期末成绩:' + item[3])
# 匹配网页对应的标题数据
if __name__ == '__main__':
list = [1, 2, 3, 5, 6, 8, 9, 10]
sum = 1
for i in list:
print('-----------------')
print('第' + str(sum) + '条:')
re01(i)
sum += 1
4筛选计算绩点
这里准备直接爬取网页数据!(留尾巴~)
三、总结
bs4框架爬取:bs4基本用法

源码:
import requests
import base64
import re
from bs4 import BeautifulSoup
from urllib import request
from http import cookiejar
url_grade = 'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_list'
data2 = {
'kksj': '2018-2019-1',
'kcmc': '',
'kcxz': '',
'xsfs': 'all',
}
headers = {
'Accept':
'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding':
'gzip, deflate',
'Accept-Language':
'zh-CN,zh;q=0.9',
'Cache-Control':
'max-age=0',
'Connection':
'keep-alive',
'Content-Length':
'37',
'Cookie':
'JSESSIONID=**********************',
'Content-Type':
'application/x-www-form-urlencoded',
'Host':
'jwgl.cqjtu.edu.cn',
'Referer':
'http://jwgl.cqjtu.edu.cn/jsxsd/kscj/cjcx_query',
'Upgrade-Insecure-Requests':
'1',
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36}',
}
html = requests.post(url_grade, data=data2, headers=headers)
# print(html2.text)
soup = BeautifulSoup(html.text, 'lxml') # 创建soup对象
print('******************')
info = re.findall(
"""""",
html.text)
if len(info) > 0:
name = info[0]
print(name)
print('******************')
table = soup.select("#dataList")[0]
tr = table.find_all('tr')[1:]
for i in tr:
subject = i.find_all('td', align="left")[1::2][0].text
score = i.find('a').text
print(subject + '--------------' + score)
print('******************')
附: 难点参考链接:
1、验证码登录
- 教务系统验证码处理: https://blog.csdn.net/nghuyong/article/details/51622888
- Python Scrapy 验证码登录处理:https://www.cnblogs.com/defineconst/p/6220462.html
2、re筛选
- 教务系统爬虫: https://blog.csdn.net/qq_41251963/article/details/81610058