KMP算法
转载地址:http://www.cppblog.com/oosky/archive/2006/07/06/9486.html
KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O(m*n);KMP匹配算法。可以证明它的时间复杂度为O(m+n).。
一. 简单匹配算法
先来看一个简单匹配算法的函数:
bool SubStringMatch(char src[], char des[], int &pos)
{
int i = 0, j = 0;
pos = -1;
while ( src[i+j] != '\0'&& des[j] != '\0')
{
if ( src[i+j] == des[j] )
j++; // 继续比较后一字符
else
{
i++; j = 0; // 重新开始新的一轮匹配
}
if ( des[j] == '\0')
{
pos = i; // 匹配成功 返回下标
return true;
}
}
return false;
}
此算法的思想是直截了当的:将主串S中某个位置i起始的子串和模式串T相比较。即从 j=0 起比较 S[i+j] 与 T[j],若相等,则在主串 S 中存在以i 为起始位置匹配成功的可能性,继续往后比较( j逐步增1 ),直至与T串中最后一个字符相等为止,否则改从S串的下一个字符起重新开始进行下一轮的"匹配",即将串T向后滑动一位,即 i 增1,而 j 退回至0,重新开始新一轮的匹配。
例如:在串S=”abcabcabdabba”中查找T=” abcabd”(我们可以假设从下标0开始):先是比较S[0]和T[0]是否相等,然后比较S[1]和T[1]是否相等…我们发现一直比较到S[5] 和T[5]才不等。如图:
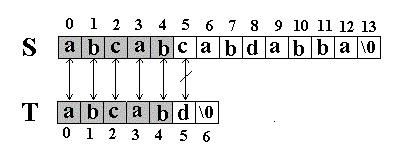
当这样一个失配发生时,T下标必须回溯到开始,S下标回溯的长度与T相同,然后S下标增1,然后再次比较。如图:
这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。如图:
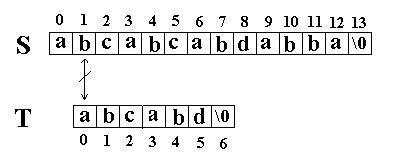
这次立刻发生了失配,T下标又回溯到开始,S下标增1,然后再次比较。如图:
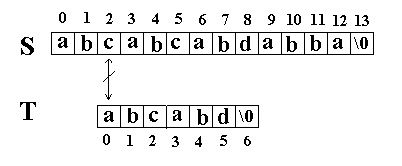
又一次发生了失配,所以T下标又回溯到开始,S下标增1,然后再次比较。这次T中的所有字符都和S中相应的字符匹配了。函数返回T在S中的起始下标3。如图:
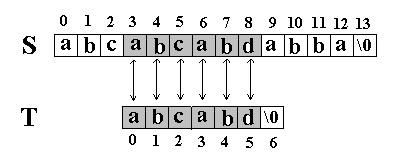
二. KMP匹配算法
还是相同的例子,在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值(next[5]=2,为什么?后面讲),直接比较S[5] 和T[2]是否相等,因为相等,S和T的下标同时增加;因为又相等,S和T的下标又同时增加。。。最终在S中找到了T。如图:

KMP匹配算法和简单匹配算法效率比较,一个极端的例子是:
在S=“AAAAAA…AAB“(100个A)中查找T=”AAAAAAAAAB”, 简单匹配算法每次都是比较到T的结尾,发现字符不同,然后T的下标回溯到开始,S的下标也要回溯相同长度后增1,继续比较。如果使用KMP匹配算法,就不必回溯.
对于一般文稿中串的匹配,简单匹配算法的时间复杂度可降为O (m+n),因此在多数的实际应用场合下被应用。
KMP算法的核心思想是利用已经得到的部分匹配信息来进行后面的匹配过程。看前面的例子。为什么T[5]==’d’的模式函数值等于2(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同,且T[5]==’d’不等于开始的两个字符之后的第三个字符(T[2]=’c’).如图:

也就是说,如果开始的两个字符之后的第三个字符也为’d’,那么,尽管T[5]==’d’的前面有2个字符和开始的两个字符相同,T[5]==’d’的模式函数值也不为2,而是为0。
前面我说:在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值,直接比较S[5] 和T[2]是否相等。。。为什么可以这样?
刚才我又说:“(next[5]=2),其实这个2表示T[5]==’d’的前面有2个字符和开始的两个字符相同”。请看图 :因为,S[4] ==T[4],S[3] ==T[3],根据next[5]=2,有T[3]==T[0],T[4] ==T[1],所以S[3]==T[0],S[4] ==T[1](两对相当于间接比较过了),因此,接下来比较S[5] 和T[2]是否相等。。。

有人可能会问:S[3]和T[0],S[4] 和T[1]是根据next[5]=2间接比较相等,那S[1]和T[0],S[2] 和T[0]之间又是怎么跳过,可以不比较呢?因为S[0]=T[0],S[1]=T[1],S[2]=T[2],而T[0] != T[1], T[1] != T[2],==> S[0] != S[1],S[1] != S[2],所以S[1] != T[0],S[2] != T[0]. 还是从理论上间接比较了。
有人疑问又来了,你分析的是不是特殊轻况啊。
假设S不变,在S中搜索T=“abaabd”呢?答:这种情况,当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=-1,意思是S[2]已经和T[0]间接比较过了,不相等,接下来去比较S[3]和T[0]吧。
假设S不变,在S中搜索T=“abbabd”呢?答:这种情况当比较到S[2]和T[2]时,发现不等,就去看next[2]的值,next[2]=0,意思是S[2]已经和T[2]比较过了,不相等,接下来去比较S[2]和T[0]吧。
假设S=”abaabcabdabba”在S中搜索T=“abaabd”呢?答:这种情况当比较到S[5]和T[5]时,发现不等,就去看next[5]的值,next[5]=2,意思是前面的比较过了,其中,S[5]的前面有两个字符和T的开始两个相等,接下来去比较S[5]和T[2]吧。
总之,有了串的next值,一切搞定。那么,怎么求串的模式函数值next[n]呢?(本文中next值、模式函数值、模式值是一个意思。)
三. 怎么求串的模式值next[n]
定义:
(1)next[0]= -1 意义:任何串的第一个字符的模式值规定为-1。
(2)next[j]= -1 意义:模式串T中下标为j的字符,如果与首字符
相同,且j的前面的1—k个字符与开头的1—k
个字符不等(或者相等但T[k]==T[j])(1≤k
如:T=”abCabCad” 则 next[6]=-1,因T[3]=T[6]
(3)next[j]=k 意义:模式串T中下标为j的字符,如果j的前面k个
字符与开头的k个字符相等,且T[j] != T[k] (1≤k
即T[0]T[1]T[2]。。。T[k-1]==
T[j-k]T[j-k+1]T[j-k+2]…T[j-1]
且T[j] != T[k].(1≤k
(4) next[j]=0 意义:除(1)(2)(3)的其他情况。
举例:
01)求T=“abcac”的模式函数的值。
next[0]= -1 根据(1)
next[1]=0 根据 (4) 因(3)有1<=k
next[2]=0 根据 (4) 因(3)有1<=k
next[3]= -1 根据 (2)
next[4]=1 根据 (3) T[0]=T[3] 且 T[1]=T[4]
即
| 下标 |
0 |
1 |
2 |
3 |
4 |
| T |
a |
b |
c |
a |
c |
| next |
-1 |
0 |
0 |
-1 |
1 |
若T=“abcab”将是这样:
| 下标 |
0 |
1 |
2 |
3 |
4 |
| T |
a |
b |
c |
a |
b |
| next |
-1 |
0 |
0 |
-1 |
0 |
为什么T[0]==T[3],还会有next[4]=0呢, 因为T[1]==T[4], 根据 (3)” 且T[j] != T[k]”被划入(4)。
02)来个复杂点的,求T=”ababcaabc” 的模式函数的值。
next[0]= -1 根据(1)
next[1]=0 根据(4)
next[2]=-1 根据 (2)
next[3]=0 根据 (3) 虽T[0]=T[2] 但T[1]=T[3] 被划入(4)
next[4]=2 根据 (3) T[0]T[1]=T[2]T[3] 且T[2] !=T[4]
next[5]=-1 根据 (2)
next[6]=1 根据 (3) T[0]=T[5] 且T[1]!=T[6]
next[7]=0 根据 (3) 虽T[0]=T[6] 但T[1]=T[7] 被划入(4)
next[8]=2 根据 (3) T[0]T[1]=T[6]T[7] 且T[2] !=T[8]
即
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
| T |
a |
b |
a |
b |
c |
a |
a |
b |
c |
| next |
-1 |
0 |
-1 |
0 |
2 |
-1 |
1 |
0 |
2 |
只要理解了next[3]=0,而不是=1,next[6]=1,而不是= -1,next[8]=2,而不是= 0,其他的好象都容易理解。
03) 来个特殊的,求 T=”abCabCad” 的模式函数的值。
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| T |
a |
b |
C |
a |
b |
C |
a |
d |
| next |
-1 |
0 |
0 |
-1 |
0 |
0 |
-1 |
4 |
next[5]= 0 根据 (3) 虽T[0]T[1]=T[3]T[4],但T[2]==T[5]
next[6]= -1 根据 (2) 虽前面有abC=abC,但T[3]==T[6]
next[7]=4 根据 (3) 前面有abCa=abCa,且 T[4]!=T[7]
若T[4]==T[7],即T=” adCadCad”,那么将是这样:next[7]=0, 而不是= 4,因为T[4]==T[7].
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| T |
a |
d |
C |
a |
d |
C |
a |
d |
| next |
-1 |
0 |
0 |
-1 |
0 |
0 |
-1 |
0 |
如果你觉得有点懂了,那么
练习:求T=”AAAAAAAAAAB” 的模式函数值,并用后面的求模式函数值函数验证。
意义:
next 函数值究竟是什么含义,前面说过一些,这里总结。
设在字符串S中查找模式串T,若S[m]!=T[n],那么,取T[n]的模式函数值next[n],
1. next[n]= -1 表示S[m]和T[0]间接比较过了,不相等,下一次比较 S[m+1] 和T[0]
2. next[n]=0 表示比较过程中产生了不相等,下一次比较 S[m] 和T[0]。
3. next[n]= k >0 但k
4. 其他值,不可能。
四. 求串T的模式值next[n]的函数
说了这么多,是不是觉得求串T的模式值next[n]很复杂呢?要叫我写个函数出来,目前来说,我宁愿去登天。好在有现成的函数,当初发明KMP算法,写出这个函数的先辈,令我佩服得六体投地。我等后生小子,理解起来,都要反复琢磨。下面是这个函数:
void get_nextval(const char *T, int next[])
{
// 求模式串T的next函数值并存入数组 next。
int j = 0, k = -1;
next[0] = -1;
while ( T[j/*+1*/] != '\0' )
{
if (k == -1 || T[j] == T[k])
{
++j; ++k;
if (T[j]!=T[k])
next[j] = k;
else
next[j] = next[k];
}// if
else
k = next[k];
}// while
////这里是我加的显示部分
// for(int i=0;i
//{
// cout<
//}
//cout<
}// get_nextval
另一种写法,也差不多。
void getNext(const char* pattern,int next[])
{
next[0]= -1;
int k=-1,j=0;
while(pattern[j] != '\0')
{
if(k!= -1 && pattern[k]!= pattern[j] )
k=next[k];
++j;++k;
if(pattern[k]== pattern[j])
next[j]=next[k];
else
next[j]=k;
}
////这里是我加的显示部分
// for(int i=0;i
//{
// cout<
//}
//cout<
}
下面是KMP模式匹配程序,各位可以用他验证。记得加入上面的函数
#include
#include
int KMP(const char *Text,const char* Pattern) //const 表示函数内部不会改变这个参数的值。
{
if( !Text||!Pattern|| Pattern[0]=='\0' || Text[0]=='\0' )//
return -1;//空指针或空串,返回-1。
int len=0;
const char * c=Pattern;
while(*c++!='\0')//移动指针比移动下标快。
{
++len;//字符串长度。
}
int *next=new int[len+1];
get_nextval(Pattern,next);//求Pattern的next函数值
int index=0,i=0,j=0;
while(Text[i]!='\0' && Pattern[j]!='\0' )
{
if(Text[i]== Pattern[j])
{
++i;// 继续比较后继字符
++j;
}
else
{
index += j-next[j];
if(next[j]!=-1)
j=next[j];// 模式串向右移动
else
{
j=0;
++i;
}
}
}//while
delete []next;
if(Pattern[j]=='\0')
return index;// 匹配成功
else
return -1;
}
int main()//abCabCad
{
char* text="bababCabCadcaabcaababcbaaaabaaacababcaabc";
char*pattern="adCadCad";
//getNext(pattern,n);
//get_nextval(pattern,n);
cout<
return 0;
}
五.其他表示模式值的方法
上面那种串的模式值表示方法是最优秀的表示方法,从串的模式值我们可以得到很多信息,以下称为第一种表示方法。第二种表示方法,虽然也定义next[0]= -1,但后面绝不会出现 -1,除了next[0],其他模式值next[j]=k(0≤k
下面给出几种方法的例子:
表一。
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
| T |
a |
b |
a |
b |
c |
a |
a |
b |
c |
| (1) next |
-1 |
0 |
-1 |
0 |
2 |
-1 |
1 |
0 |
2 |
| (2) next |
-1 |
0 |
0 |
1 |
2 |
0 |
1 |
1 |
2 |
| (3) next |
0 |
1 |
0 |
1 |
3 |
0 |
2 |
1 |
3 |
第三种表示方法,在我看来,意义不是那么明了,不再讨论。
表二。
| 下标 |
0 |
1 |
2 |
3 |
4 |
| T |
a |
b |
c |
a |
c |
| (1)next |
-1 |
0 |
0 |
-1 |
1 |
| (2)next |
-1 |
0 |
0 |
0 |
1 |
表三。
| 下标 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| T |
a |
d |
C |
a |
d |
C |
a |
d |
| (1)next |
-1 |
0 |
0 |
-1 |
0 |
0 |
-1 |
0 |
| (2)next |
-1 |
0 |
0 |
0 |
1 |
2 |
3 |
4 |
对比串的模式值第一种表示方法和第二种表示方法,看表一:
第一种表示方法next[2]= -1,表示T[2]=T[0],且T[2-1] !=T[0]
第二种表示方法next[2]= 0,表示T[2-1] !=T[0],但并不管T[0] 和T[2]相不相等。
第一种表示方法next[3]= 0,表示虽然T[2]=T[0],但T[1] ==T[3]
第二种表示方法next[3]= 1,表示T[2] =T[0],他并不管T[1] 和T[3]相不相等。
第一种表示方法next[5]= -1,表示T[5]=T[0],且T[4] !=T[0],T[3]T[4] !=T[0]T[1],T[2]T[3]T[4] !=T[0]T[1]T[2]
第二种表示方法next[5]= 0,表示T[4] !=T[0],T[3]T[4] !=T[0]T[1] ,T[2]T[3]T[4] !=T[0]T[1]T[2],但并不管T[0] 和T[5]相不相等。换句话说:就算T[5]==’x’,或 T[5]==’y’,T[5]==’9’,也有next[5]= 0 。
从这里我们可以看到:串的模式值第一种表示方法能表示更多的信息,第二种表示方法更单纯,不容易搞错。当然,用第一种表示方法写出的模式匹配函数效率更高。比如说,在串S=“adCadCBdadCadCad 9876543”中匹配串T=“adCadCad”, 用第一种表示方法写出的模式匹配函数,当比较到S[6] != T[6] 时,取next[6]= -1(表三),它可以表示这样许多信息: S[3]S[4]S[5]==T[3]T[4]T[5]==T[0]T[1]T[2],而S[6] != T[6],T[6]==T[3]==T[0],所以S[6] != T[0],接下来比较S[7]和T[0]吧。如果用第二种表示方法写出的模式匹配函数,当比较到S[6] != T[6] 时,取next[6]= 3(表三),它只能表示:S[3]S[4]S[5]== T[3]T[4]T[5]==T[0]T[1]T[2],但不能确定T[6]与T[3]相不相等,所以,接下来比较S[6]和T[3];又不相等,取next[3]= 0,它表示S[3]S[4]S[5]== T[0]T[1]T[2],但不会确定T[3]与T[0]相不相等,即S[6]和T[0] 相不相等,所以接下来比较S[6]和T[0],确定它们不相等,然后才会比较S[7]和T[0]。是不是比用第一种表示方法写出的模式匹配函数多绕了几个弯。
为什么,在讲明第一种表示方法后,还要讲没有第一种表示方法好的第二种表示方法?原因是:最开始,我看严蔚敏的一个讲座,她给出的模式值表示方法是我这里的第二种表示方法,如图:
她说:“next 函数值的含义是:当出现S[i] !=T[j]时,下一次的比较应该在S[i]和T[next[j]] 之间进行。”虽简洁,但不明了,反复几遍也没明白为什么。而她给出的算法求出的模式值是我这里说的第一种表示方法next值,就是前面的get_nextval()函数。匹配算法也是有瑕疵的。于是我在这里发帖说她错了:
http://community.csdn.net/Expert/topic/4413/4413398.xml?temp=.2027246
现在看来,她没有错,不过有张冠李戴之嫌。我不知道,是否有人第一次学到这里,不参考其他资料和明白人讲解的情况下,就能搞懂这个算法(我的意思是不仅是算法的大致思想,而是为什么定义和例子中next[j]=k(0≤k
书归正传,下面给出我写的求第二种表示方法表示的模式值的函数,为了从S的任何位置开始匹配T,“当出现S[i] !=T[j]时,下一次的比较应该在S[i]和T[next[j]] 之间进行。” 定义next[0]=0 。
void myget_nextval(const char *T, int next[])
{
// 求模式串T的next函数值(第二种表示方法)并存入数组 next。
int j = 1, k = 0;
next[0] = 0;
while ( T[j] != '\0' )
{
if(T[j] == T[k])
{
next[j] = k;
++j; ++k;
}
else if(T[j] != T[0])
{
next[j] = k;
++j;
k=0;
}
else
{
next[j] = k;
++j;
k=1;
}
}//while
for(int i=0;i
{
cout<
}
cout<
}// myget_nextval
下面是模式值使用第二种表示方法的匹配函数(next[0]=0)
int my_KMP(char *S, char *T, int pos)
{
int i = pos, j = 0;//pos(S 的下标0≤pos
while ( S[i] != '\0' && T[j] != '\0' )
{
if (S[i] == T[j] )
{
++i;
++j; // 继续比较后继字符
}
else // a b a b c a a b c
// 0 0 0 1 2 0 1 1 2
{ //-1 0 -1 0 2 -1 1 0 2
i++;
j = next[j]; /*当出现S[i] !=T[j]时,
下一次的比较应该在S[i]和T[next[j]] 之间进行。要求next[0]=0。
在这两个简单示范函数间使用全局数组next[]传值。*/
}
}//while
if ( T[j] == '\0' )
return (i-j); // 匹配成功
else
return -1;
} // my_KMP
六.后话--KMP的历史
[这段话是抄的]
Cook于1970年证明的一个理论得到,任何一个可以使用被称为下推自动机的计算机抽象模型来解决的问题,也可以使用一个实际的计算机(更精确的说,使用一个随机存取机)在与问题规模对应的时间内解决。特别地,这个理论暗示存在着一个算法可以在大约m+n的时间内解决模式匹配问题,这里m和n分别是存储文本和模式串数组的最大索引。Knuth 和Pratt努力地重建了 Cook的证明,由此创建了这个模式匹配算法。大概是同一时间,Morris在考虑设计一个文本编辑器的实际问题的过程中创建了差不多是同样的算法。这里可以看到并不是所有的算法都是“灵光一现”中被发现的,而理论化的计算机科学确实在一些时候会应用到实际的应用中。
另一个人的思路,更通俗易懂
如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段。
我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法。KMP算法是拿来处理字符串匹配的。换句话说,给你两个字符串,你需要回答,B串是否是A串的子串(A串是否包含B串)。比如,字符串A="I'm matrix67",字符串B="matrix",我们就说B是A的子串。你可以委婉地问你的MM:“假如你要向你喜欢的人表白的话,我的名字是你的告白语中的子串吗?”
解决这类问题,通常我们的方法是枚举从A串的什么位置起开始与B匹配,然后验证是否匹配。假如A串长度为n,B串长度为m,那么这种方法的复杂度是O (mn)的。虽然很多时候复杂度达不到mn(验证时只看头一两个字母就发现不匹配了),但我们有许多“最坏情况”,比如,A= "aaaaaaaaaaaaaaaaaaaaaaaaaab",B="aaaaaaaab"。我们将介绍的是一种最坏情况下O(n)的算法(这里假设 m<=n),即传说中的KMP算法。
之所以叫做KMP,是因为这个算法是由Knuth、Morris、Pratt三个提出来的,取了这三个人的名字的头一个字母。这时,或许你突然明白了AVL 树为什么叫AVL,或者Bellman-Ford为什么中间是一杠不是一个点。有时一个东西有七八个人研究过,那怎么命名呢?通常这个东西干脆就不用人名字命名了,免得发生争议,比如“3x+1问题”。扯远了。
个人认为KMP是最没有必要讲的东西,因为这个东西网上能找到很多资料。但网上的讲法基本上都涉及到“移动(shift)”、“Next函数”等概念,这非常容易产生误解(至少一年半前我看这些资料学习KMP时就没搞清楚)。在这里,我换一种方法来解释KMP算法。
假如,A="abababaababacb",B="ababacb",我们来看看KMP是怎么工作的。我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符(j当然越大越好),现在需要检验A[i+1]和B[j+1]的关系。当A[i+1]=B[j+1]时,i和j各加一;什么时候j=m了,我们就说B是A的子串(B串已经整完了),并且可以根据这时的i值算出匹配的位置。当A[i+1]<>B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配(从而使得i和j能继续增加)。我们看一看当 i=j=5时的情况。
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
此时,A[6]<>B[6]。这表明,此时j不能等于5了,我们要把j改成比它小的值j'。j'可能是多少呢?仔细想一下,我们发现,j'必须要使得B[1..j]中的头j'个字母和末j'个字母完全相等(这样j变成了j'后才能继续保持i和j的性质)。这个j'当然要越大越好。在这里,B [1..5]="ababa",头3个字母和末3个字母都是"aba"。而当新的j为3时,A[6]恰好和B[4]相等。于是,i变成了6,而j则变成了 4:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
从上面的这个例子,我们可以看到,新的j可以取多少与i无关,只与B串有关。我们完全可以预处理出这样一个数组P[j],表示当匹配到B数组的第j个字母而第j+1个字母不能匹配了时,新的j最大是多少。P[j]应该是所有满足B[1..P[j]]=B[j-P[j]+1..j]的最大值。
再后来,A[7]=B[5],i和j又各增加1。这时,又出现了A[i+1]<>B[j+1]的情况:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
由于P[5]=3,因此新的j=3:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
这时,新的j=3仍然不能满足A[i+1]=B[j+1],此时我们再次减小j值,将j再次更新为P[3]:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
现在,i还是7,j已经变成1了。而此时A[8]居然仍然不等于B[j+1]。这样,j必须减小到P[1],即0:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 0 1 2 3 4 5 6 7
终于,A[8]=B[1],i变为8,j为1。事实上,有可能j到了0仍然不能满足A[i+1]=B[j+1](比如A[8]="d"时)。因此,准确的说法是,当j=0了时,我们增加i值但忽略j直到出现A[i]=B[1]为止。
这个过程的代码很短(真的很短),我们在这里给出:
j:=0;
for i:=1 to n do
begin
while (j>0) and (B[j+1]<>A[i]) do j:=P[j];
if B[j+1]=A[i] then j:=j+1;
if j=m then
begin
writeln('Pattern occurs with shift ',i-m);
j:=P[j];
end;
end;最后的j:=P[j]是为了让程序继续做下去,因为我们有可能找到多处匹配。
这个程序或许比想像中的要简单,因为对于i值的不断增加,代码用的是for循环。因此,这个代码可以这样形象地理解:扫描字符串A,并更新可以匹配到B的什么位置。
现在,我们还遗留了两个重要的问题:一,为什么这个程序是线性的;二,如何快速预处理P数组。
为什么这个程序是O(n)的?其实,主要的争议在于,while循环使得执行次数出现了不确定因素。我们将用到时间复杂度的摊还分析中的主要策略,简单地说就是通过观察某一个变量或函数值的变化来对零散的、杂乱的、不规则的执行次数进行累计。KMP的时间复杂度分析可谓摊还分析的典型。我们从上述程序的j 值入手。每一次执行while循环都会使j减小(但不能减成负的),而另外的改变j值的地方只有第五行。每次执行了这一行,j都只能加1;因此,整个过程中j最多加了n个1。于是,j最多只有n次减小的机会(j值减小的次数当然不能超过n,因为j永远是非负整数)。这告诉我们,while循环总共最多执行了n次。按照摊还分析的说法,平摊到每次for循环中后,一次for循环的复杂度为O(1)。整个过程显然是O(n)的。这样的分析对于后面P数组预处理的过程同样有效,同样可以得到预处理过程的复杂度为O(m)。
预处理不需要按照P的定义写成O(m^2)甚至O(m^3)的。我们可以通过P[1],P[2],...,P[j-1]的值来获得P[j]的值。对于刚才的B="ababacb",假如我们已经求出了P[1],P[2],P[3]和P[4],看看我们应该怎么求出P[5]和P[6]。P[4]=2,那么P [5]显然等于P[4]+1,因为由P[4]可以知道,B[1,2]已经和B[3,4]相等了,现在又有B[3]=B[5],所以P[5]可以由P[4] 后面加一个字符得到。P[6]也等于P[5]+1吗?显然不是,因为B[ P[5]+1 ]<>B[6]。那么,我们要考虑“退一步”了。我们考虑P[6]是否有可能由P[5]的情况所包含的子串得到,即是否P[6]=P[ P[5] ]+1。这里想不通的话可以仔细看一下:
1 2 3 4 5 6 7
B = a b a b a c b
P = 0 0 1 2 3 ?
P[5]=3是因为B[1..3]和B[3..5]都是"aba";而P[3]=1则告诉我们,B[1]、B[3]和B[5]都是"a"。既然P[6]不能由P[5]得到,或许可以由P[3]得到(如果B[2]恰好和B[6]相等的话,P[6]就等于P[3]+1了)。显然,P[6]也不能通过P[3]得到,因为B[2]<>B[6]。事实上,这样一直推到P[1]也不行,最后,我们得到,P[6]=0。
怎么这个预处理过程跟前面的KMP主程序这么像呢?其实,KMP的预处理本身就是一个B串“自我匹配”的过程。它的代码和上面的代码神似:
P[1]:=0;
j:=0;
for i:=2 to m do
begin
while (j>0) and (B[j+1]<>B[i]) do j:=P[j];
if B[j+1]=B[i] then j:=j+1;
P[i]:=j;
end;最后补充一点:由于KMP算法只预处理B串,因此这种算法很适合这样的问题:给定一个B串和一群不同的A串,问B是哪些A串的子串。
串匹配是一个很有研究价值的问题。事实上,我们还有后缀树,自动机等很多方法,这些算法都巧妙地运用了预处理,从而可以在线性的时间里解决字符串的匹配。我们以后来说。
代码:
KMP算法的实现
KMP算法是一种用于字符串匹配的算法,这个算法的高效之处在于当在某个位置匹配不成功的时候可以根据之前的匹配结果从模式字符串的另一个
位置开始,而不必从头开始匹配字符串.
因此这个算法的关键在于,当某个位置的匹配不成功的时候,应该从模式字符串的哪一个位置开始新的比较.假设这个值存放在一个next数组中,其
中next数组中的元素满足这个条件:next[j] = k,表示的是当模式字符串中的第j + 1个(这里是遵守标准C语言中数组元素从0开始的约定,以下不
再说明)发生匹配不成功的情况时,应该从模式字符串的第k + 1个字符开始新的匹配.如果已经得到了模式字符串的next数组,那么KMP算法的实现
如下:
// KMP字符串模式匹配算法
// 输入: S是主串,T是模式串,pos是S中的起始位置
// 输出: 如果匹配成功返回起始位置,否则返回-1
int KMP(PString S, PString T, int pos)
{
assert(NULL != S);
assert(NULL != T);
assert(pos >= 0);
assert(pos < S->length);
if (S->length < T->length)
return -1;
printf("主串\t = %s\n", S->str);
printf("模式串\t = %s\n", T->str);
int *next = (int *)malloc(T->length * sizeof(int));
// 得到模式串的next数组
GetNextArray(T, next);
int i, j;
for (i = pos, j = 0; i < S->length && j < T->length; )
{
// i是主串游标,j是模式串游标
if (-1 == j || // 模式串游标已经回退到第一个位置
S->str[i] == T->str[j]) // 当前字符匹配成功
{
// 满足以上两种情况时两个游标都要向前进一步
++i;
++j;
}
else // 匹配不成功,模式串游标回退到当前字符的next值
{
j = next[j];
}
}
free(next);
if (j >= T->length)
{
// 匹配成功
return i - T->length;
}
else
{
// 匹配不成功
return -1;
}
}
下面看看如何得到next数组.
这是一个递推求解的过程,初始的情况是next[0] = -1.
假设在某一个时刻有如下的等式成立:str[0...k-1] = str[j - k...j - 1],那么next[j] = k,在这个前提下,继续进行下一个字符的匹配.
1)如果str[0...k] = str[j - k...j],那么next[j + 1] = next[j] + 1 = k + 1.
2)反之,如果上面的匹配不成立,那么就要从next[k]开始进行新的匹配,如果成功的话,那么:
next[j + 1] = next[next[j]] + 1 = next[k] + 1;
如果还是不能匹配成功就再从next[next[k]]的位置开始进行的新的匹配,直到匹配成功为止.如果这个过程一直进行下去都没有找到可以成功匹配的字符的话,那么next[j + 1] = 0,这时表示要从字符串的第一个位置开始新的匹配了.
用一个公式表示上述的算法,那么可以写作:
next[j] =
1)-1,当j = 0时;
2) Max{k | 0 <= k < j && str[0..k - 1] = str[j - k...j - 1]};
3)0,其他情况,此时匹配要从第一个位置重新开始.
寻找next数组的算法如下:
// 得到字符串的next数组
void GetNextArray(PString pstr, int next[])
{
assert(NULL != pstr);
assert(NULL != next);
assert(pstr -> length > 0 );
// 第一个字符的next值是-1,因为C中的数组是从0开始的
next[ 0 ] = - 1 ;
for ( int i = 0 , j = - 1 ; i < pstr -> length - 1 ; )
{
// i是主串的游标,j是模式串的游标
// 这里的主串和模式串都是同一个字符串
if ( - 1 == j || // 如果模式串游标已经回退到第一个字符
pstr -> str[i] == pstr -> str[j]) // 如果匹配成功
{
// 两个游标都向前走一步
++ i;
++ j;
// 存放当前的next值为此时模式串的游标值
next[i] = j;
}
else // 匹配不成功j就回退到上一个next值
{
j = next[j];
}
}
} 完整的算法如下:
/* *******************************************************************
created: 2006/07/02
filename: KMP.cpp
author: 李创
http://www.cppblog.com/converse/
参考资料: 严蔚敏<<数据结构>>
purpose: KMP字符串匹配算法的演示
******************************************************************** */
#include < stdio.h >
#include < stdlib.h >
#include < assert.h >
#include < string .h >
#define MAX_LEN_OF_STR 30 // 字符串的最大长度
typedef struct String // 这里需要的字符串数组,存放字符串及其长度
{
char str[MAX_LEN_OF_STR]; // 字符数组
int length; // 字符串的实际长度
} String, * PString;
// 得到字符串的next数组
void GetNextArray(PString pstr, int next[])
{
assert(NULL != pstr);
assert(NULL != next);
assert(pstr -> length > 0 );
// 第一个字符的next值是-1,因为C中的数组是从0开始的
next[ 0 ] = - 1 ;
for ( int i = 0 , j = - 1 ; i < pstr -> length - 1 ; )
{
// i是主串的游标,j是模式串的游标
// 这里的主串和模式串都是同一个字符串
if ( - 1 == j || // 如果模式串游标已经回退到第一个字符
pstr -> str[i] == pstr -> str[j]) // 如果匹配成功
{
// 两个游标都向前走一步
++ i;
++ j;
// 存放当前的next值为此时模式串的游标值
next[i] = j;
}
else // 匹配不成功j就回退到上一个next值
{
j = next[j];
}
}
}
// KMP字符串模式匹配算法
// 输入: S是主串,T是模式串,pos是S中的起始位置
// 输出: 如果匹配成功返回起始位置,否则返回-1
int KMP(PString S, PString T, int pos)
{
assert(NULL != S);
assert(NULL != T);
assert(pos >= 0 );
assert(pos < S -> length);
if (S -> length < T -> length)
return - 1 ;
printf( " 主串\t = %s\n " , S -> str);
printf( " 模式串\t = %s\n " , T -> str);
int * next = ( int * )malloc(T -> length * sizeof ( int ));
// 得到模式串的next数组
GetNextArray(T, next);
int i, j;
for (i = pos, j = 0 ; i < S -> length && j < T -> length; )
{
// i是主串游标,j是模式串游标
if ( - 1 == j || // 模式串游标已经回退到第一个位置
S -> str[i] == T -> str[j]) // 当前字符匹配成功
{
// 满足以上两种情况时两个游标都要向前进一步
++ i;
++ j;
}
else // 匹配不成功,模式串游标回退到当前字符的next值
{
j = next[j];
}
}
free(next);
if (j >= T -> length)
{
// 匹配成功
return i - T -> length;
}
else
{
// 匹配不成功
return - 1 ;
}
}