深度学习论文笔记(异常检测)——f-AnoGAN: Fast unsupervised anomaly detection with generative adversarial networks
文章目录
- 声明
- 主要工作
- 算法介绍
- 阶段一:训练WGAN
- 阶段二:训练Encoder
- 训练方式一: i z i izi izi
- 训练方式二: z i z ziz ziz
- 训练方式三: i z i f izi_f izif
- 异常检测
- 实验
声明
出于好奇,本人只是阅读过该篇文章,并没有将该论文应用于实际生活,故不能在实践上给予各位一些建议,万分抱歉!
如果诸位在看我写过的文章时发现了错误,请务必告诉本人,不胜感激!
主要工作
提出了一种Encoder,可以快速将图片映射到隐空间中的某个点,接着利用WGAN进行异常检测。
在深度学习论文笔记(异常检测)—— Generative Adversarial Networks to Guide Marker Discovery一文中,我总结了AnoGAN,其通过不断迭代优化,在隐空间中寻找某个点,该点生成的图片与测试图片最为相近,接着利用DCGAN进行异常检测,由于需要迭代优化,势必会耗费大量时间,而f-AnoGAN通过引入Encoder,解决了这个问题。
代码地址
算法介绍
有监督异常检测存在的问题
- 需要耗费大量人力与时间对数据进行标注,在医疗领域,数据标注的代价更高,并且数据量比较少,而有监督学习往往需要耗费大量数据。
- 有监督学习只能处理训练样例中存在的情况。
针对有监督的问题,论文提出了使用无监督的GAN进行医疗数据的异常检测,其具体机制为:使用正常数据训练GAN,生成器 G G G只能生成正常数据,如果能在隐空间中找到一点 Z Z Z, G ( Z ) G(Z) G(Z)与测试图像最为相近, G ( Z ) G(Z) G(Z)为正常图像,如果两者的差距大于某个值,就可判断测试图像为异常图像。鉴别器 D D D本质是一个二分类模型,可以鉴别出真实图像与生成器生成图像之间的细微差别,而异常图像本身与正常图像差别较大,鉴别器会将异常图像分为非正常图像。可以看到,鉴别器与生成器都可以单独用于异常检测,和AnoGAN一样,论文将两者进行了结合。
模型分为两个阶段,如下图
阶段一:训练WGAN
阶段二:训练Encoder
阶段一:训练WGAN
此处总结数据准备
设有 N N N张正常医疗图片构成的集合 R R R, I n ∈ R I_n \in R In∈R( n = 1 、 2 、 3... N n=1、2、3...N n=1、2、3...N),从 I n I_n In中随机截取 K K K张大小为 c ∗ c c*c c∗c的图片构成训练数据集
设标记好的数据集为 J J J,按上述方式采集大小为 c ∗ c c*c c∗c的图像 y m y_m ym,同时获得对应的大小为 c ∗ c c*c c∗c的掩码图像 a m a_m am(为像素为1表示异常,为0表示无异常), < y m , a m >
在视网膜光学相干断层扫描图像数据集上构建训练与测试数据集的流程如下:
阶段二:训练Encoder
论文没有给出Encoder的结构,应该是一个卷积神经网络,具体可以查看代码部分
WGAN训练完毕后,不在改变,由生成器充当decoder,与Encoder一起构成了auto-encoder结构,Encoder负责将训练图片(查看上一节数据准备部分)映射为隐空间中的点 Z Z Z,生成器将 Z Z Z映射为图片。
Encoder存在三种训练方式,如下图
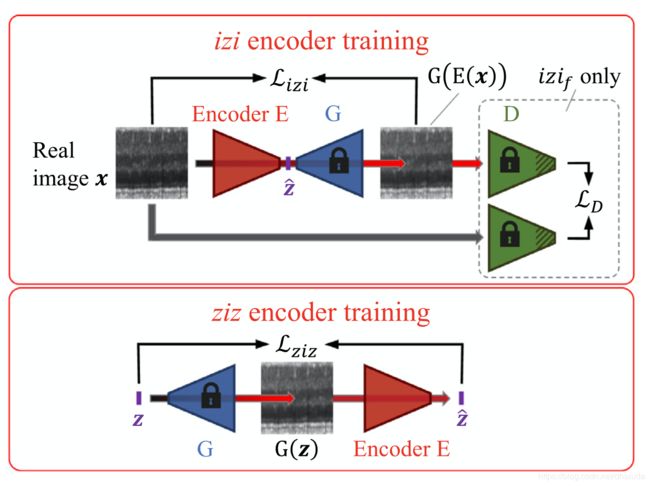
训练方式一: i z i izi izi
具体步骤
- Encoder将图片x映射为隐空间中的点 z ^ \hat z z^
- 生成器将 z ^ \hat z z^映射为图片 G ( z ^ ) G(\hat z) G(z^)
- 损失函数为MSE: L i z i ( x ) = 1 n ∣ ∣ x − G ( z ^ ) ∣ ∣ 2 L_{izi}(x)=\frac{1}{n}||x-G(\hat z)||^2 Lizi(x)=n1∣∣x−G(z^)∣∣2 n n n为像素的个数
训练方式二: z i z ziz ziz
具体步骤
- 在隐空间中随机选取一个点 z z z,生成器将 z z z映射为图片 G ( z ) G(z) G(z)
- Encoder将 G ( z ) G(z) G(z)映射为隐空间中的点 z ^ \hat z z^
- 损失函数为MSE: L z i z ( z ) = 1 d ∣ ∣ z − z ^ ) ∣ ∣ 2 L_{ziz}(z)=\frac{1}{d}||z-\hat z)||^2 Lziz(z)=d1∣∣z−z^)∣∣2 d为隐空间的维数
训练方式三: i z i f izi_f izif
具体步骤
- Encoder将图片x映射为隐空间中的点 z ^ \hat z z^
- 生成器将 z ^ \hat z z^映射为图片 G ( z ^ ) G(\hat z) G(z^)
- 将 G ( z ^ ) G(\hat z) G(z^)与 x x x输入到鉴别器中,得到 L D = 1 n d ∣ ∣ f ( x ) − f ( G ( z ^ ) ) ∣ ∣ 2 L_D=\frac{1}{n_d}||f(x)-f(G(\hat z))||^2 LD=nd1∣∣f(x)−f(G(z^))∣∣2,f(x)为鉴别器中间某一层的特征图,该特征图被认为含有输入图像的统计信息, L D L_D LD用于比较图像之间统计信息的差异, n d n_d nd为特征图的维数(个人理解为特征图像素个数)
- 损失函数为 L i z i f ( x ) = 1 n ∣ ∣ x − G ( z ^ ) ∣ ∣ 2 + λ 1 n d ∣ ∣ f ( x ) − f ( G ( z ^ ) ) ∣ ∣ 2 L_{izi_f}(x)=\frac{1}{n}||x-G(\hat z)||^2+\lambda \frac{1}{n_d}||f(x)-f(G(\hat z))||^2 Lizif(x)=n1∣∣x−G(z^)∣∣2+λnd1∣∣f(x)−f(G(z^))∣∣2 λ \lambda λ为超参数
f − A n o G A N f-AnoGAN f−AnoGAN将 i z i f izi_f izif 作为Encoder的训练方式
异常检测
异常检测其实是一个二分类问题,我们需要设计一个异常分数公式用于计算异常分数,异常分数高于某个值,即可认为出现异常,f-AnoGAN将 L i z i f ( x ) L_{izi_f}(x) Lizif(x)作为异常分数公式, L i z i f ( x ) L_{izi_f}(x) Lizif(x)从像素差异与图片之间的统计学差异角度比较了两张图片之间的差距。
假设 x x x为异常图片,由于生成器只能生成正常图片,鉴别器能鉴别图片是否符合正常图片分布,则 G ( z ^ ) G(\hat z) G(z^)与 x x x、 f ( G ( z ^ ) ) f(G(\hat z)) f(G(z^))与 f ( x ) f(x) f(x)之间的差异势必比较大。
L i z i L_{izi} Lizi对应AnoGAN中的 R e s i d u a l L o s s Residual Loss ResidualLoss, L D L_D LD则对应 D i s c r i m i n a t i o n L o s s Discrimination Loss DiscriminationLoss,AnoGAN中统计过正常与异常图片在 R e s i d u a l L o s s Residual Loss ResidualLoss与 D i s c r i m i n a t i o n L o s s Discrimination Loss DiscriminationLoss上的取值差异,如下:
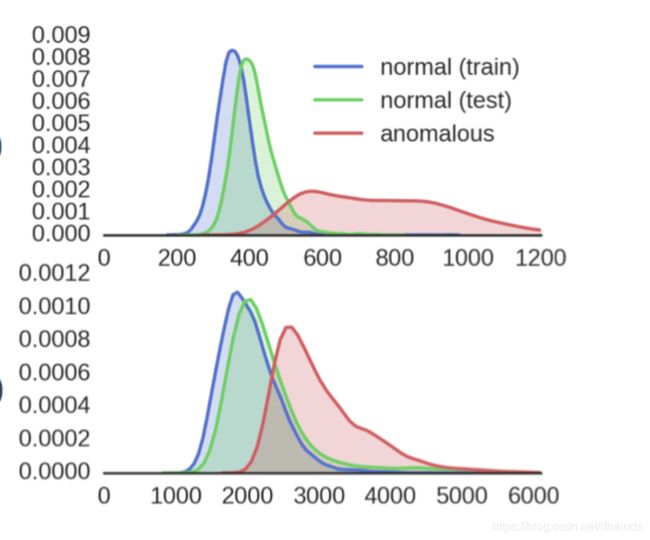
x轴表示 L i z i L_{izi} Lizi与 L D L_D LD的值,y轴表示频率,可以看出
- 异常图片的 L i z i L_{izi} Lizi与 L D L_D LD普遍大于正常图片
- 正常图片与异常图片在 L i z i L_{izi} Lizi与 L D L_D LD上的取值分布重叠部分小,说明 L i z i L_{izi} Lizi与 L D L_D LD对于正常图片与异常图片的区分度高
因此, L i z i f ( x ) L_{izi_f}(x) Lizif(x)可用于计算异常得分
实验
问题一:隐空间是否平滑连续?
如果隐空间不够平滑连续,只有部分隐空间中的点能生成真实度较高的图片,为了验证隐空间是连续的,论文进行了两个实验
实验一:随机选择隐空间中的两个点,两点之间做一条位于高维度空间的直线,生成这条直线上的点对应的图片
实验二:依据真实图片在隐空间中选择两个点(应该是使用了Encoder),两点之间做一条位于高维度空间的直线,生成这条直线上的点对应的图片
两个实验的结果如下
可以看到,图像之间的变化非常自然,由此可见隐空间还是比较平滑的,如果隐空间是剧烈抖动的,那么图像之间的渐变效果应该会非常明显
问题二:f-AnoGAN的预测准确率如何?
异常检测本质上是一个二分类问题,可以使用准确率召回率等指标进行模型评估
论文比对的baseline有
- A E AE AE
- A d v A E AdvAE AdvAE
- A L I ALI ALI
- A D A_D AD:使用WGAN的鉴别器输出作为异常分数,由于WGAN的输出比较的是生成图片与真实图片的Wasserstein距离,因此不能直接作为异常分数,设测试图片为 x x x,则异常分数定义如下 A D = m ^ x − D ( x ) A_D=\hat m_{x}-D(x) AD=m^x−D(x)
随机选择32000张测试图片,统计对应的鉴别器输出,计算平均值,即为 m ^ x \hat m_x m^x - i t e r a t i v e iterative iterative:使用WCAN的AnoGAN
结果如下:
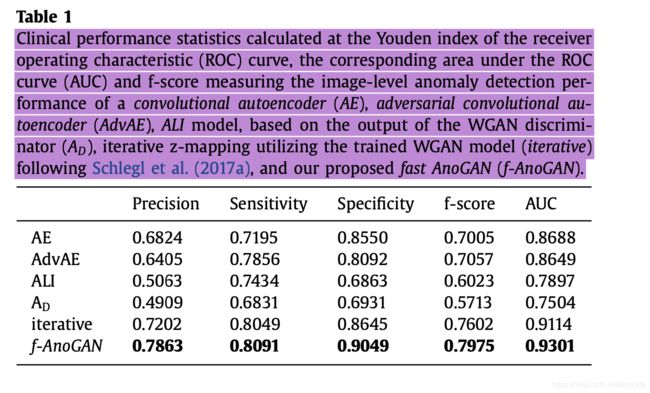
f-AnoGAN的评价指标均为最高,表现相当优异
AUC如下
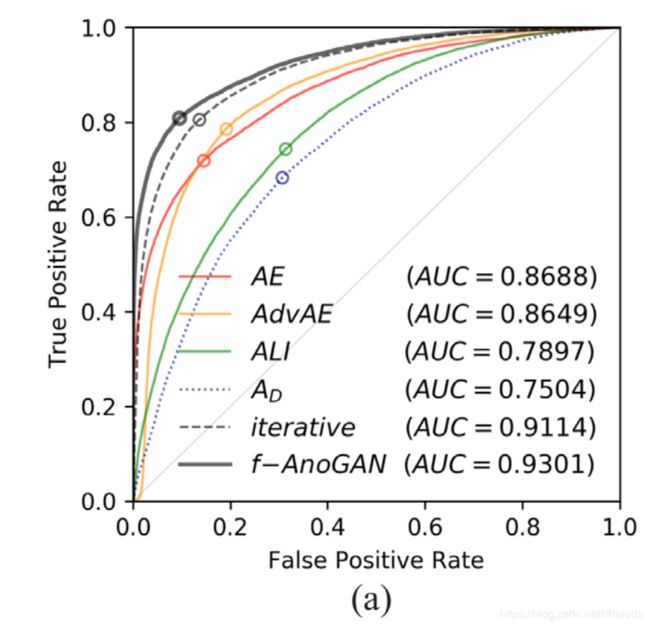
问题三:f-AnoGAN异常检测的效果如何?
问题四:不同Encoder训练策略的比较
首先是异常检测的视觉效果
接着是各项指标
AUC如下:
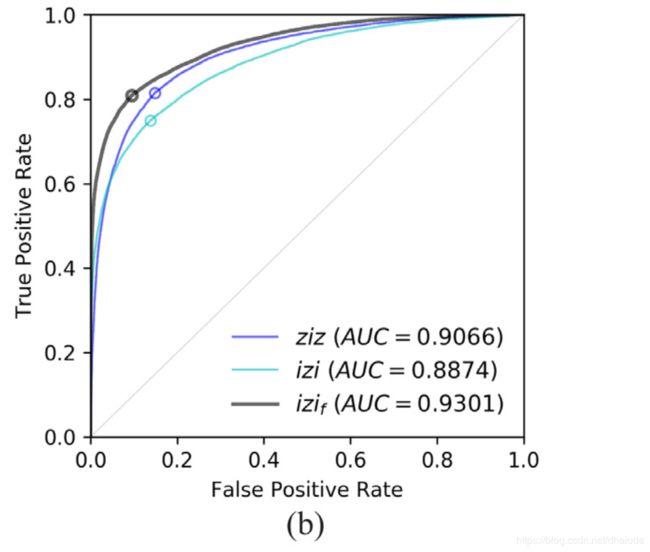
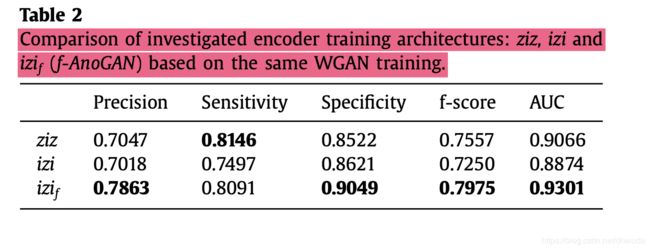
可看出, i z i f izi_f izif策略的训练结果最佳