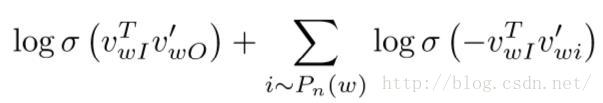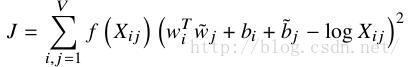这几天把第三课推掉了,又到了写博客的时间,好开心,有木有
这一课主要讲了两大部分:第一大部分讲得是如何建立Object function并且如何找到optimum point;第二大部分讲的是如何评测生成的VSM的优劣。主要讲的是这两大部分,其中穿插了一些小的知识点,会在下面详细写出。
老样子,先写出Video/Slide的pipeline: Refresher: word2vec model -> Gradient Descent -> Stochastic Gradient Descent -> Skip-gram model and CBWM -> Intrinsic evaluation -> Extrinsic evaluation -> Ambiguity -> softmax and cross entropy error -> training word vectors or not?
Video/Slide
- Refresher: word2vec model
这一部分主要介绍了word2vec model的cost function
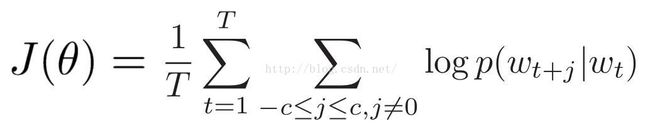
就是这个东东啦,其中T代表着windows的个数,c代表着context的wide。
最右边的p使用softmax计算

w_o就是上式左边的那个w_t+j,w_I就是上式右边的w_t。
我们习惯上把所有参数全部塞到一个长长长长的vector里面这个vector我们称它为theta,这样的话上式中的cost function里的参数就得有 2d*V个了(d是每个单词向量的长度,V是单词的个数,由于输入输出单词向量表示法不一样所以是二倍的)
现在我们有了cost function就得想办法找到optimum point啦!当然最简单也是最容易想到的就是Gradient Descent,也就是对cost function的theta向量求导得到最佳下降梯度,然后用原theta减去这个梯度乘以step就得到更新后的向量了。这种方法每次找到的方向很精确,每次都能往最陡的坡度走,但是有一个问题,观察上面的公式一,我们的cost function是对所有windows进行相加,而每求一个梯度都得把所有的windows求一遍和,如果dataset小的话没什么问题,但是如果对于很大的dataset那么没步进一步的cost是很大的。所以SGD闪亮登场!
- Stochastic Gradient Descent
SGD不再对整个windows的和求梯度,而是对一个window求梯度之后就立即更新theta。
这个方法灰常好啊,收敛快呀,但是每一次更新都是针对这一个window里的单词更新的,这就意味着,一次更新最多更新2c - 1 个单词的参数,也就是 (2c-1)*d个参数。这样的话就不必每次更新整个参数矩阵,仅仅更新window的单词在参数矩阵中对应的列就好了。这样的话可以很大的提高计算效率,和存储效率。
解决了Gradient Descent的Cost大的问题,现在问题又来了(- -),上面第二个公式可以看到求概率P的时候使用到了softmax它的分母是对所有的words求和,我们的vocabulary通常是很大的,计算一次很痛苦的有木有,这个咋办呢?办法总是有的,我们观察上面的softmax的公式,可以发现,我们的目的就是让正确的word脱颖而出。那么这样的话我们取整个单词表的词就没必要了嘛,只要让正确的word的值大,其他随机的word和center word组合的值小不是一样的嘛。于是skip-gram和negative sampling组合的方式应运而生!首先我们定义了一个noise distribution用来随机选取随机的word。
其中sigma函数是sigmod函数,这很好理解目的是要两个向量靠得更近方向更一致,那么sigmod函数中两个向量靠得越近值就越大,反之越小。
CBWM类似Skip-gram的逆运算在之前的博文中也有写就不再赘述了。
其中有一个要注意的是最终我们得到了L和L‘的参数矩阵,相当于得到了这个co-occurance矩阵里单词的信息,怎么处理这两个矩阵呢?一种办法是直接相加L_final = L + L',另一种方法是把两个矩阵连接起来,这样的结果就综合了输入矩阵和输入矩阵的信息。
Intrinsic evaluation 是对VSM的一个简单迅速的评估。这种评估方法不放到整个系统中评估,而仅仅是评估一个subtask进行评估。评估过程很快,可以很好的理解这个系统。但是不知道放到实际的系统中是否也表现的很好。Intrinsic evaluation的第一种评估是Syntactic评估,这种评估方法问题比较少;第二种是semantic评估,存在一词多义的 问题,还有corpus的数据比较旧的问题,这两个问题都会影响评估结果。Glove word vector是至今Intrinsic evaluation才是结果最好的model,Asymmetric context只评估左边window的单词效果不好。More training time and more data对评估结果很有帮助。
Extrinsic evaluation就是把VSM放到实际的任务中进行评估,花费时间较长,如果效果不好的话也不清楚是VSM的问题还是其他模块的问题或者是interaction的问题。有一个简单的办法确认是不是VSM的问题,把这个subsystem用其他的subsystem替换如果精度提高那就换上!
如果一个单词有很多个意思怎么办?如果你简单的就当作一个mean vector来处理那就会相当于把两个不同意思的向量进行向量相加,这显然是不准确的。解决方法在Notes讲得很详细,这里摘抄如下:
1. Gather fixed size context windows of all occurrences of the word(for instance, 5 before and 5 after)
2. Each context is represented by a weighted average of the context words’ vectors (using idf-weighting)
3. Apply spherical k-means to cluster these context representations.
4. Finally, each word occurrence is re-labeled to its associated cluster and is used to train the word representation for that cluster.
简单的说就是使用k-means聚类将如同的context先聚类出来,再给每个certriod赋相应的word,再把相应的context归给这个word,最后再用我们之前的普通训练方法训练。这就解决了一次多义的问题。
- Softmax and cross entropy error
和之前一样评估一个单词发生的概率,很简单也是可以用softmax当然这个方法cost太大,所以用skip-gram更好一些。我们的目的是使得我们的参数让结果向量中ground-truth位的值最大(有点绕)。之前我们用的是sigmod函数配合内积的方法,还有一种方法也能很好的解决这个问题,那就是cross entropy error。Cross entropy可以用来评估两个概率之间差异的大小H(p, q)。我们把P代入ground-truth概率向量,q代入我们计算的概率向量,目的是使得两者差异最小也就是使H(p, q)最小。展开H(p, q) = H(p) + D_KL(p || q)。由于p本身的性质,第一项天然就会为0,不为零也没关系,因为我们是要改变q中的参数,p始终是fix的,不会影响计算结果。所以求H(p, q)就会等价为求D_KL(p || q)的最小值。
- training word vectors or not?
首先摘抄notes里的一句话:Word vectors should not be retrained if the training data set is small. If the training set is large, retraining may improve performance.
为什么是这样呢?我来解释一下这句话:第一,当data set比较小的时候,我们进行Gradient Decent进行theta的更新只能更新到data set中的word其他的word的向量不用被更新到,而我们的softmax weight W是根据新的dataset进行判别的,那么这样的结果就会使dataset中不包含的word的判别出问题。第二,当data set比较大的时候,假设涵盖了整个vocabulary,我们不论是进行Gradient Decent更新theta还是对Softmax weight W进行更新就是对整个vocabulary进行更新,不会出现遗漏的问题,而这种方法增添进来了新的data set里的信息有可能会使精确度增加。
Paper -> Glove: Global Vectors for word representation
这个paper主要介绍了Glove的大致原理。大概事情是这样的,现在我们处理capture fine-grained semantic的能力和capture syntactic的能力都还不错。semantic基于term-document这样的模式效果好,syntactic基于term-document的模式效果好,但有没有一种方法能把这两个东西综合一下呢?于是Glove应运而生了!事实也证明了,这玩意胜过了similarity tasks和named entity recognition。
摘抄文中经典的一段:
While methods like LSA efficiently leverage statistical information, they do relatively poorly on the word analogy task, indicating a sub-optimal vector space structure. Methods like skip-gram may do better on the analogy task, but they poorly utilize the statistics of the corpus since they train on separate local context windows instead of on global co-occurrence counts.
Glove的目的就是要把那两个玩意综合起来一下。
怎么综合起来呢?Glove的发明人使用了一个曲线救国的迂回战术。首先从word-context出发,定义P_ij = P(j|i) = X_ij / X_i。其中X_ij是在word i的context中j出现的次数。X_i是word i的context中的单词的总个数。P_ij就是word j出现在word i的context的概率。现在定义一个probe单词k假设i,k的相关性大那么P_ik就会大,反之就小。那么我们可以得出结论如果P_ik / P_jk >> 1则k和i的相关性要远远大于k和j的相关性;如果P_ik / P_jk 约等于1那么k和i的相关性及k和j的相关性就类似;如果P_ik / P_jk << 1则k和i的相关性要远远小于k和j的相关性。
定义一个function: F(w_i, w_j, w_k(~)) = P_ik / P_jk
我们知道等式右边是从word-context出发也就是基于skip-gram类似的算法的,而等式左边是基于term-document也就是类似LSA的,也就是这样一个等式把sentiment method和syntactic method联系起来了。
推倒过程不表,paper上很详细,最后得到(w_i)'(w_k)~ + b_i + b_k(~) = log(X_ik)
为了使上式计算出的X_ij和ground truth X_ij尽可能的一致,最后构造了一个cost function
其中f(X_ij)是weight function怎么得来的就不说了,paper上很详细。
3.1和3.2分别介绍了Glove和其他模型的关系还有Gloved的计算复杂度,没啥说的。
第四部分experiment主要就是测试结果,略过不表。
Paper -> Improving Word Representations via Global Context and Multiple Word Prototypes
这个paper主要就讲了两件事:第一就是如何用Neural Network实现Global Context-Aware Neural Language Model;第二就是为了解决一次多义的问题将Multi-Prototype也引入模型。
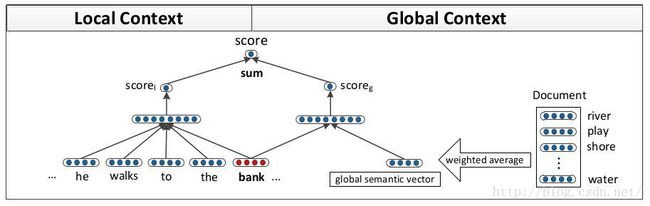
第一部分所讲的精髓都在这里面,左边建立一个Neural Network算出a_1的值,然后score_l = W_2 * a_1 + b_2
右边先对Document里的word取weight average然后在通过右边的Neural Network求出a_2,通过右边的function求得
score_g = W_2(g) * a_1(g) + b_2(g)
最后一步图上也画了就是对两个score取sum,score = score_l + score_g
摘抄一段文中的句子:The local score preserves word order and syntactic information, while the global score uses a weighted average which the global score uses a weighted average which is similar to bag-of-words features, capturing more of the semantics and topics of the document.
第二部分就是为了解决一次多义的问题。方法如下:We then use spherical k-means to cluster these context representations, which has been shown to model semantic relations well. Finally, each word occurrence in the corpus is re-labeled to its associated cluster and is used to train the word representation for that cluster.
其实使用k-means进行预处理的方法课上的slide和notes讲的更详细,做完预处理之后之后的处理方法就和之前的处理方法一样了。
第四部分就是experiment的结果了,略过不表。
版权声明:本文为博主原创文章,未经博主允许不得转载。