非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型
非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型
还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢?
答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究:
第一步:非线性模型那么多,我们应该选择“哪一个模型呢?”
1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型
点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
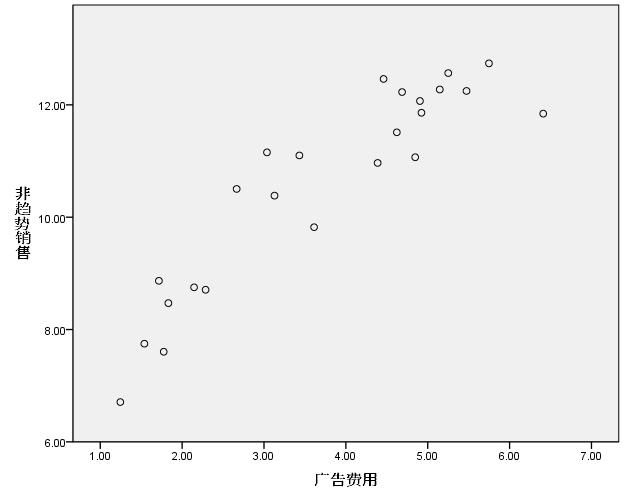
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高!
点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果:
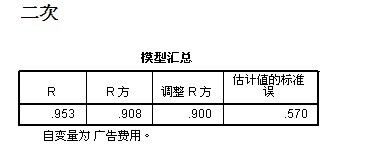
通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度 明显高于“二次”模型的拟合度 (0.912 >0.900)不过,几乎接近
接着,我们采用S 模型,得到如下所示的结果:
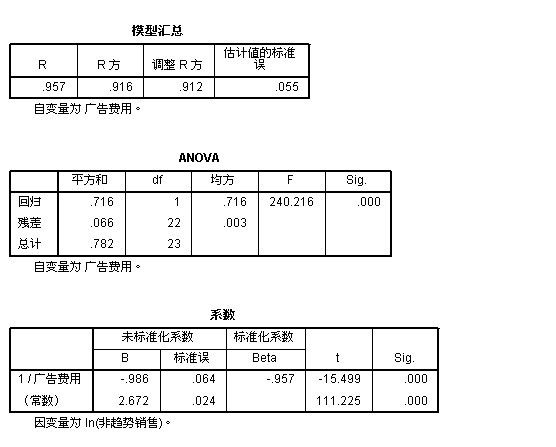
结果分析:
1:从ANOVA表中可以看出:总体误差= 回归平方和 + 残差平方和 (共计:0.782) F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等)
2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986) 常数项为2.672
所以 S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用)
当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用)
下面,我们直接采用“非线性”模型来进行操作
第一步:确定“非线性模型”
从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。
从图形可以看出:它符合The asymptotic regression model (渐近回归模型)
表达式为:Y(销售量)= b1 + b2*e∧b3*(广告费用)
当b1>0, b2<0, and b3<0,时,它符合效益递减规律,我们称之为:Mistcherlich's model
第二步:确定各参数的初始值
1:b1参数值的确定,从表达式可以看出:随着”广告费用“的增加,销售量也会增加,最后达到一个峰值,由于:b2<0, b3<0 ,随着广告费用的增加:b2*e∧b3*(广告费用)会逐渐趋向于“0” 而此时 Y(销售量)将接近于 b1值,从上图可以看出:Y(销售量)的最大值为12点多,接近13,所以,我们设定b1的初始值为13
2:b2参数值确定:当Y(销售量)最小时,此时应该广告费用最小,基本等于“0”,可以得出:b1+b2= Y(销售量)此时Y销售量最小,从图中可以看出:第一个值为6.7左右,接近7这个值,所以:b2=7-13=-6
3: b3参数值确定:可以用图中两个分离点的斜率来确定b3的值,例如取(x1=2.29,y1=8.71) 和( x2=5.75, y2=12.74) 通过公式 y2-y1/x2-x1=1.16,(此处可以去整数估计值来算b3的值)
确定参数初始值和参数范围的方法如下所示:
1:通过图形确定参数的取值范围,然后在这个范围里选择初始值。
2:根据非线性方程的数学特性进行某些变换后,再通过图形帮助判断初始值的范围。
3:先使用固定的数代替某些参数,以此来确定其它参数的取值范围。
4:通过变量转换,使用线性回归模型来估计参数的初始值
第三步:建立模型表达式和选择损失函数
点击“分析”—回归——非线性,进入如下所示界面:
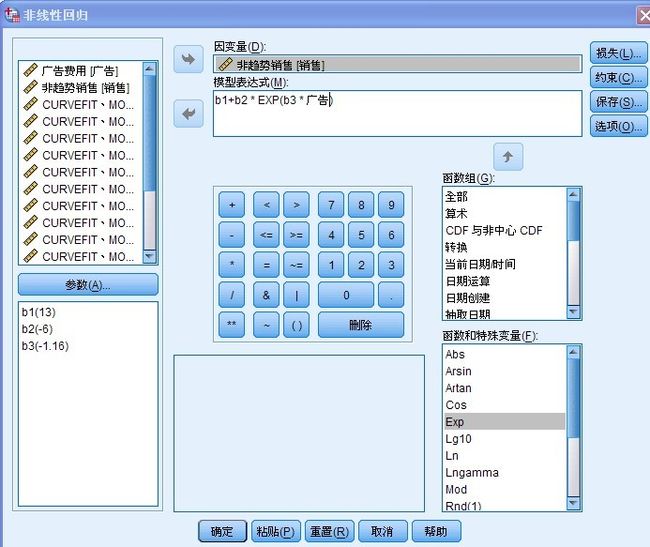
如上图中,点击参数,分别添加b1,b2,b3进入参数框内,在模型表达式中输入:b1 + b2*Exp(b3*广告费用) (步骤为:选择“函数组”—算术——Exp函数),将“销售量”变量拖入“因变量”框内
“损失函数”默认选项为“残差平方和” 如果有特需要求,可以自行定义
点击“约束”进入如下所示的界面:
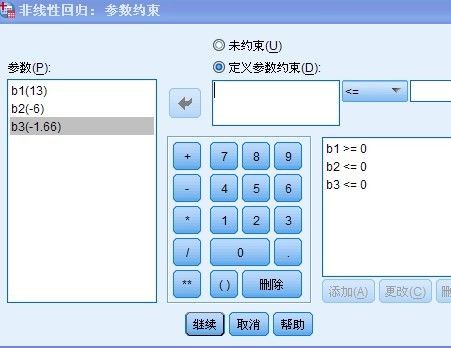
点击“继续”按钮,此时会弹出警告信息,提示用户是否接受建议, 建议内容为:将采用序列二次编程进行参数估计,点击确定,接受建议即可
参数的取值范围指在迭代过程中,将参数限制在有意义的范围区间内,提供两种对参数范围约束的方法:
1:线性约束,在约束表达式里只有对参数的线性运算
2:非线性约束,在约束表达式里,至少有一个参数与其它参数进行了乘,除运算,或者自身的幂运算
在“保存”选项中,勾选“预测值”和“残差”即可,点击继续
点击“选项”得到如下所示的界面:
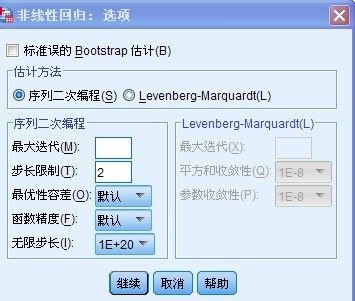
此处的“估计方法”选择“序列二次编程”的方法, 此方法主要利用的是双重迭代法进行求解,每一步迭代都建立一个二次规划算法,以此确定优化的方向,把估计参数不断的带入损失函数进行求值运算,直到满足指定的收敛条件为止
点击继续,再点击“确定”得到如下所示的结果:
上图结果分析:
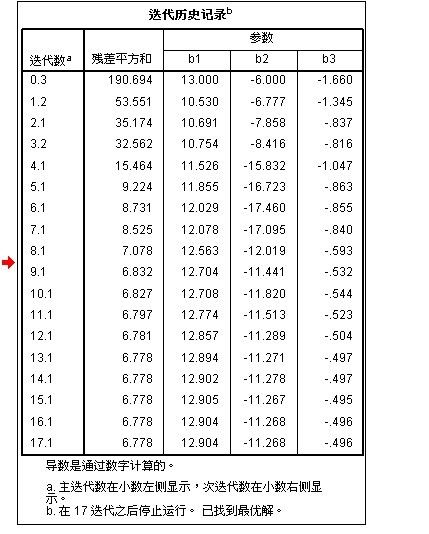
1:从“迭代历史记录”表中可以看出:迭代了17次后,迭代被终止,已经找到最优解
此方法是不断地将“参数估计值”代入”损失函数“求解, 而损失函数采用的是”残差平方和“最小,在迭代17次后,残差平方和达到最小值,最小值为(6.778)此时找到最优解,迭代终止
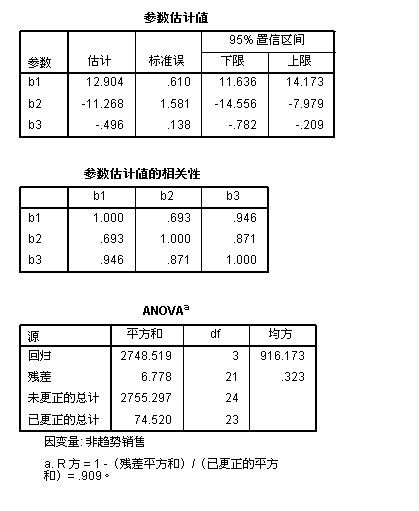
2:从参数估计值”表中可以看出:
b1= 12.904 (标准误为0.610,比较小,说明此估计值的置信度较高) b2=-11.268 (标准误为:1.5881,有点大,说明此估计值的置信度不太高) b3=-0.496(标准误为:0.138,很小,说明此估计值的置信度很高)
非线性模型表达式为:Y(销售量)= 12.904-11.268*e^(-0.496*广告费用)
3:从“参数估计值的相关性”表中可以看出:b1 和 b3的相关性较强,b2和b1或b3的相关性都相对弱一些,其中b1和b2的相关性最弱
4:从anova表中可以看出:R方 = 1- (残差平方和)/(已更正的平方和) = 0.909, 拟合度为0.909,说明此模型能够解释90多的变异,拟合度已经很高了
前面已经提到过,S行曲线的拟合度更高,为(0.916)那到底哪个更合适呢? 如果您的数据样本容量够大,我想应该是“非线性模型”的拟合度会更高!