从DPDK和eBPF感受一下Smart NIC
安德森先生这周从上海来过周末,小小给妈妈外婆讲了刚学到的恺撒加密算法,而我,写一篇随笔吧。
周三晚上,我演示了Linux下一代防火墙bpfilter的一个自制简易POC:
前天晚上在家加班处理问题,一顿操作后没响应了,以为系统panic了,就等待重启,远程登录的设备,就不知道是不是真panic了还是说仅仅网络断了,等待期间撸了下文里的代码,还测通了,当再想起正事儿的时候,快一个小时过去了,系统依旧没有恢复…让同事帮忙带外check,发现是在我配置vf时网卡reset了,丢了路由…这就是远程登录的坏处,搞搞业务代码还行,搞网络搞内核的还是机器在眼前,键盘在手边让人安心啊。
不过好歹我没有干等,下文分享给大家,一起玩bpfilter和智能网卡吧。必须值得一提的,iproute2和netfilter我已经用了十来年了,前者一直在与时俱进,后者却几乎没有变化,然而这并不意味着netfilter就是一无是处,在我看来5个hook点可以部署成ebpf的容器,配合以pinned map,就完美了,ebpf是瑞士军刀,它缺个刀鞘,否则容易误伤自己。
bpfilter是什么,让我演示给你看:
https://blog.csdn.net/dog250/article/details/103283981
那么,这个和DPDK有什么关系。说实话,本文不该提DPDK的,应该提的是类似netmap,PF_RING的这种东西:
https://www.ntop.org/products/packet-capture/pf_ring/
只不过,DPDK太为人所熟知了,所以就用DPDK来指代这一切,但也只是指代。
本文不说DPDK的细节,因为我也不是很懂,虽然不喜欢DPDK但也不贬它,DPDK在本文中只是一个引子。
不管怎样,先说结论,DPDK和eBPF都是在吐槽嫌弃现代操作系统内核实现的网络协议栈。
实话实说,我也觉得网络协议栈不应该在操作系统内核实现,它只是一个应用,而不是系统的范畴。但是30多年来,网络协议栈一直都在各大操作系统内核中实现。
之所以这样,是因为操作系统原初并没有将数据处理和逻辑控制相分离,通信行业的数据面,控制面,管理面分离的理念并没有在新生的计算机业内发展起来,人们一团糟地将一切和具体业务无关的东西都塞进了操作系统内核,当然,这也是造成宏内核的根本原因。
随着计算机网络技术的发展,通信技术和计算机网络技术逐渐融合。
把网络协议栈从操作系统剥离出来的最好方式就是 实现一个数据平面 。
DPDK似乎找到了一种正确的方法,即直接将数据包拉到用户态来处理,绕过操作系统内核(Tilera Core以及通用的netmap当然也是这种方式)。虽然它们的实现各自不同,但整体看来,这些机制又大又重。
由于网卡功能有限,它没有逻辑计算单元,仅负责收发数据包的IO操作以及极少量的数据包缓存,大部分的协议流程都必须由主机CPU来完成,即便绕过了操作系统内核,CPU也还是必须的,因此DPDK一般而言都是专门分配一个或者几个CPU核心来处理数据包。
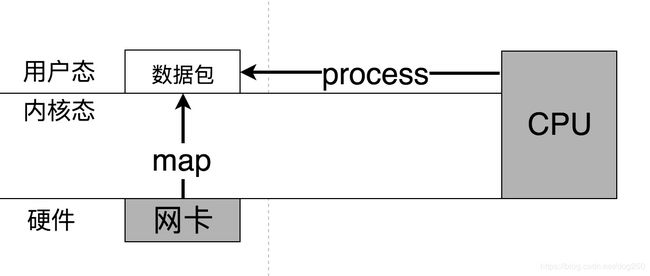
既然数据包来自网卡,何不让网卡自己去处理?给网卡赋予逻辑处理能力就可以了。
因此,ASIC以及FPGA承担了高性能网络处理的职责,专门的电路可以及时就地处理数据包,无需主机CPU参与,解放了CPU。
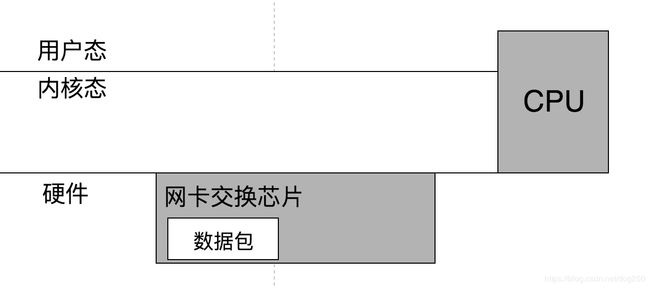
但同样是大而重的,你必须采用专用的软件对专门的硬件进行编程,类似DPDK有一套需要学习后才能上手的SDK一样,FPGA甚至需要专门的语言。
何不在网卡上装一个足够通用的CPU配备一块足够通用的内存呢,如此网卡就是一个五脏俱全的小型计算机了,既然是个计算机,那就可以执行通用代码咯。
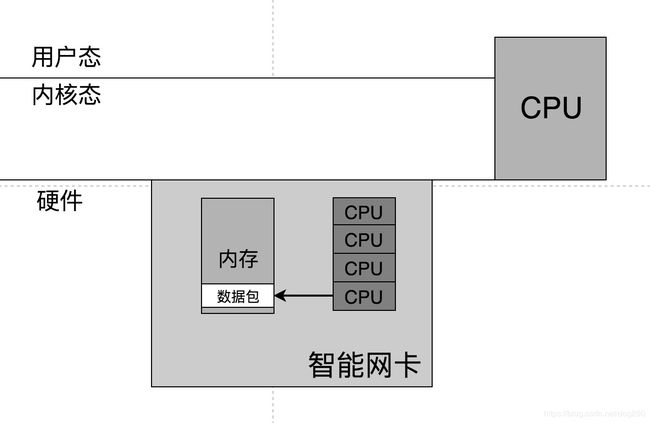
和DPDK把数据包拉到用户态的方向相反,与其把数据上拉被CPU处理,把处理数据包的代码向下注入网卡是殊途同归的,为了让网卡可以执行注下去的代码,给网卡内置几个CPU即可,这就是智能网卡的思路。
DPDK从上面经由用户态bypass内核协议栈,智能网卡从下面在硬件里offload协议栈的逻辑。
在这个意义上,DPDK其实就是把x86 CPU+Ringbuffer和Intel网卡一起,当成了一块 “智能网卡”
下面的图示展示了智能网卡的结构以及注入代码的执行逻辑,来自netronome的Open-NFP官网:
netronome开创了智能网卡新时代,netronome SmartNIC可以配备几十个处理器同时执行网络数据包处理的代码,从而卸载主机CPU的劳力,这就是我们常说的硬件Offload。
那么如何把代码注入到智能网卡呢?
你可以使用专用的模式,阅读智能网卡厂商的指令集,然后确保最终的机器码对应该指令集即可,但幸运的是,我们有通用的eBPF的JIT编译,可以将eBPF中间字节码编译成智能网卡的机器码。整个过程从编程到部署,非常通用:

目前netronome SmartNIC已经实现了该JIT编译器,参见Linux内核目录树:
linux-source-5.xx/drivers/net/ethernet/netronome
其中,eBPF字节码的JIT编译器在 “nfp/bpf” 子目录。
具体到Offload如何部署,也是很简单。一般而言,我们要先用C语言写一个eBPF程序,比如test.c,然后用clang指定目标体系结构为bpf,将其编译成二进制字节码test.o,这个时候,就差一个加载器了。
以我非常喜欢的iproute2套件为例,比方说要把test.o加载到一块netronome网卡eth0,需要这么做即可:
ip link set dev eth0 xdpoffload obj test.o
如此一来,test.c里面的逻辑就可以在智能网卡中被执行了,完全卸载了主机CPU的劳力。
整个操作过程,基本上也就这般。
和大而重的DPDK相比,智能网卡的eBPF小而巧,如果我们把DPDK看成是一门红衣大炮,那么eBPF就是瑞士军刀,虽然处理完整的TCP协议还不够,但是做个数据包拦截,解析是绰绰有余。
eBPF和智能网卡是我们这种手艺人的福音!
编程手艺人指的就是不懂大型软件工程流程,没参与过大型软件开发,不会高级编程语言,没写过多少代码,不会使用发布工具,不经常用git,但也不是一点都不会编程,还是稍微懂一点编程的。不过手艺人精通计算机原理,精通操作系统的实现,精通网络协议,所以手艺人一般可以轻松完成BUG的定位和fix工作,由于不会大段大段写代码,所以手艺人往往精于精准定位,一两行代码就能fix,比如加一个mb。所以,手艺人往往在职场工作量上吃亏,手艺人善于自己玩。
几年前我没事就想折腾折腾协议栈,比如优化下nf_conntrack啦,把socket指针藏进nf_conntrack啦,把路由项藏进nf_conntrack啦,在网卡层短路协议栈啦,实现一个无状态NAT啦,在内核实现一个加密通道啦…然而最终也只是玩玩,如今,有了eBPF和XDP,并且eBPF支持了pinned map之后,以上这些都可以重玩了。有时间重新撸一遍,嗯,就这么定了!
介绍些资料:
https://lwn.net/Articles/760041/ 【netronome网卡进化路径上的绝佳一笔,可以在单片ASIC上共享eBPF程序和map了!】
https://lwn.net/Articles/675826/ 【多端口switch模型,Linux反客为主,打破网络设备厂商的垄断】
通用的switchdev驱动模型之前,Linux需要厂商的专门工具套件操作交换机,控制权在厂商,switchdev之后,通用接口被实现,交换机正式纳入Linux网络设备体系,Linux至此可以用标准接口实现交换机的控制面和管理面了,至此以后,各大互联网厂商的自研交换机才开始遍地开花!!
http://wiki.netfilter.org/pablo/netdev0.1/papers/Rocker-switchdev-prototyping-vehicle.pdf 【多端口switch设备的实例】
下面是我自己写的一些关于eBPF的文章:
https://blog.csdn.net/dog250/article/details/103283981
https://blog.csdn.net/dog250/article/details/103245748
https://blog.csdn.net/dog250/article/details/102982948
https://blog.csdn.net/dog250/article/details/103094759
https://blog.csdn.net/dog250/article/details/103014526
https://blog.csdn.net/dog250/article/details/102884567
浙江温州皮鞋湿,下雨☔️进水不会胖!