栈地址的分配和大小端模式
1. 栈地址的生长方式 (从高地址到低地址) -- 即先分配的变量存在高地址,后分配的存在低地址
栈的空间是由编译器进行开辟和释放,主要存放局部变量和函数参数。
----- 函数参数的地址是连续的。
来看一个简单的例子:
#include
#include
using namespace std;
//函数参数列表的存放方式是,先对最右边的形参分配地址,后对左边的形参分配地址
void fun(int a,int b)
{
printf("&b = 0x%x\n",&b);
printf("&a = 0x%x\n",&a);
}
int main()
{
int i = 3,j = 4;
//栈地址的分配是从高地址到低地址进行分配的
printf("&i = 0x%x\n",&i);
printf("&j = 0x%x\n",&j);
fun(i,j);
system("pause");
return 0;
} 输出结果:
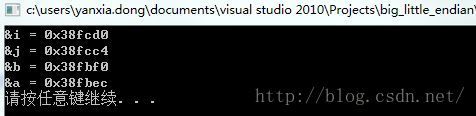
可以看出栈地址的生长方向是向下的,即先分配的变量存在高地址,后分配的变量存在低地址中。
#include
using namespace std;
//程序中存在一定的顺序点,顺序点是指执行过程中修改变量值的最晚时刻
void f(int i,int j)
{
printf("&i = 0x%x\n",&i);
printf("&j = 0x%x\n",&j);
printf("i = %d,j = %d\n",i,j);
}
int main()
{
int k = 1;
f(k,k++);
printf("k = %d\n",k);
system("pause");
return 0;
} 函数参数的求值顺序依赖于编译器的实现,在vs2010中求值是从右向左。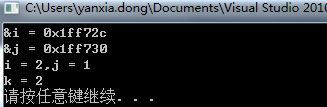
2)大小端的问题
先说说大小端的来由吧,为什么会有大小端模式呢?
在我们的计算机系统中,数据的存储是以字节为单位的,每个地址单元都对应着一个字节,一个字节是8bit。
但是我们常用的基本数据类型不止只有一个char(8bit),还有int(32bit),short(16bit).
并且对于位数大于8的处理器,如32bit和64bit的处理器,由于寄存器的宽度大于一个字节,那就存在着如何将多个字节安排的问题了。
于是我们的大小端模式诞生了。
大端模式: 数据的高字节部分保存在内存的低地址中,低字节存在高地址中。
小端模式: 和大端模式的顺序相反,高字节存在高地址中,低字节存在低地址中。
那么怎么知道你的编译器是大端模式还是小端模式呢?
1)用union来判断
union data
{
int i;
char c;
};
int main()
{
union data dat;
dat.i=1;//一个字节,若存在低地址,是小端,否则是大端
if(dat.c == 1)
{
printf("little endian.\n");
}
else
{
printf("big endian.");
printf("%d\n",dat.c);
}
system("pause");
return 0;
}2)int -> char
int main()
{
int x = 0x2345;
char c1,c2;
c1 = *((char *)&x);//(char *)&x[0]
c2 = *((char *)&x + 1);//(char *)&x[1]
printf("0x%x\t",c1);//0x45
printf("0x%x\n",c2);//0x23 is little endian
system("pause");
return 0;
}