Linux I/O编程 实验内容
一、实验目的:
练习用UNIX I/O进行文件读写的编程方法,用UNIX I/O函数管理文本信息、二进制数据、结构体数据,掌握UNIX I/O的基本编程方法。练习测时函数使用,通过测量UNIX I/O函数运行时间,建立UNIX I/O API函数基本开销的概念。
二、实验内容与要求:
先创建用户家目录下创建文件名为“姓名+学号+04”的子目录,作为本次实验目录,本次实验的所有代码都放到该目录下,要求将所有源代码与数据文件打包成文件”学号-姓名-lab4.tar.gz”, 压缩包与实验报告分别上传到指定目录下。
任务1. 在当前用户目录下创建数据文件student.txt,文件的内部信息存储格式为Sname:S#:Sdept:Sage:Ssex,即“姓名:学号:学院:年龄:性别”,每行一条记录,输入不少于10条学生记录,其中包括学生本人记录。调用标准I/O库编写程序task41.c,从文件中查找Sdept字段值为“计算机与网络安全学院”的文本行,输出到文件csStudent.txt中,保存时各字段顺序调整为S#:Sname:Sage: Ssex:Sdept。
提示:从终端读入一个文本行到字符串 char buf[MAXSIZE]可调用函数可调用函数:
“fgets(buf, MAXSIZE, stdin);”,其中stdin是表示键盘输入设备的文件指针。
代码:
#include
任务2. 调用Unix I/O库函数,编写程序task42.c,从键盘读入5个学生的成绩信息,包括学号、姓名、语文、数学、英语,成绩允许有一位小数,存入一个结构体数组,结构体定义为:
typedef struct _subject {
char sno[20]; //学号
char name[20]; //姓名
float chinese; //语文成绩
float math; //数学成绩
float english; //英语成绩
} subject;
代码:
#include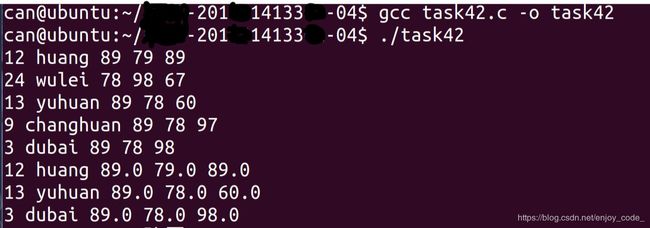
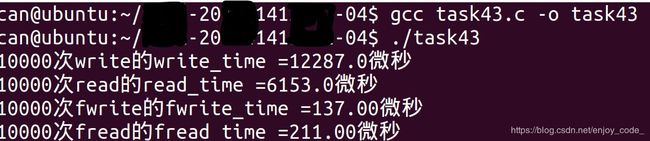
任务3(可选):在Linux环境下,可以调用库函数gettimeofday测量一个代码段的执行时间,请写一个程序task43.c,测量read、write、fread、fwrite函数调用所需的执行时间,并与prof/gprof工具测的结果进行对比,看是否基本一致。并对四个函数的运行时间进行对比分析。
提示:由于一次函数调用时间太短,测量误差太多,应测量上述函数多次(如10000次)运行的时间,结果才会准确。
代码:
#includefwrite和fread有自己的缓冲区,直到缓冲区写满或者指针指向文本结束位置时,才会进行一次I/O操作,大大减少了write和read函数在内核空间和用户空间之间的转换,这种转换会带来非常大的cpu开销,所以前者的效率更高。(截图如下:)
附录: multiply,使用prof/gprof测量程序运行时间
Linux/Unix环境提供了prof/gprof工具来收集一个程序各函数的执行次数和占用CPU时间等统计信息,使用prof/gprof工具查找程序性能问题,要求编译命令添加-p选项(prof)或-pg选项(gprof),程序执行时就会产生执行跟踪文件mon.out(或gmon.out),再运行prof(或gprof)程序读取跟踪数据,产生运行报告。现在用gprof对以下程序各函数运行性能(占用CPU时间)进行测量。先输入程序源代码:
#include 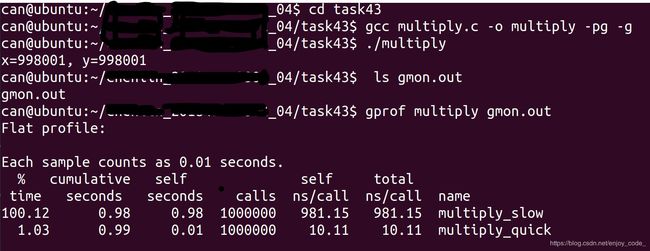
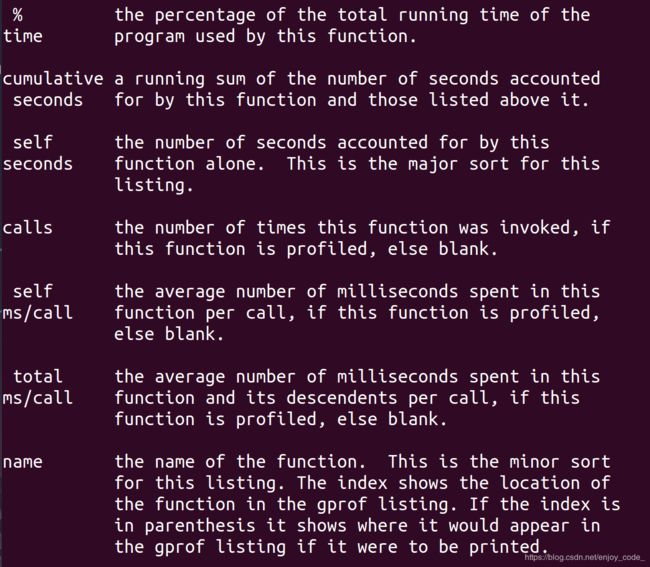
multipy_slow花费了0.98s,multipy_quick花费了0.01s
任务4:在Linux系统环境下,编写程序task44.c,对一篇英文文章文件的英文单词词频进行统计。
(1)以“单词:次数”格式输出所有单词的词频(必做)
(2)以“单词:次数”格式、按词典序输出各单词的词频(选做)
(3)以“单词:次数”格式输出出现频度最高的10个单词的词频
例如,若某个输入文件内容为:
GNU is an operating system that is free software—that is, it respects users’ freedom.
The development of GNU made it possible to use a computer without software that would trample your freedom.
则输出应该是:
GNU:2
is:3
it:2
……
代码:
#include 

后记
第一次写C for Linux ,特别是gcc 编译器特别不习惯,出现了很多没见过的问题。
第一个就是
段错误 (核心已转储)
这种字样,一般就是相当于vs上数组越界,访问到不合理的内存这种情况,多去留意下自己write和read这些I/O类的函数,一行行仔细比对,一定能找到问题所在。
第二个就是c语言很久没写过了,很多语法都不记得了。还犯了在结构体里初始化char数组的小失误。
第三个就是某些头文件在gcc编译器里找不到,只能自己编写成库文件,否则就只能换一个函数来使用。
收获:
read和write是要进行内核模式和用户模式之间的切换的,这种切换会带来非常大的cpu开销,所以相比之下,fwrite和fread有自己的缓冲区,缓冲区满了或文件指针结束了才进行一次读出/写入操作,效率更高。(都是二进制的读写,不适合文本数据)
fgets和fputs,可以一行行的读写,适合文本数据。
当不足n个字符时,读到\n就停止,会在末尾增添\0。如果刚刚好n个字符,优先读入\0,不读入\n。
read和write:(参数)
(int fd, const void *buf, size_t nbyte)
文件描述符,缓冲区,指定I/O字节数
fread和fwrite: (参数)
(const void *ptr, size_t size, size_t nmemb, FILE *stream)
目标元素数组的指针,每个元素大小(字节),元素个数(字节),文本指针
fgets和fputs: (参数)
(char *str, int n, FILE *stream)
字符数组的指针,读取的最大字符数,文本指针
注意:FILE * 类型和int类型不相等
编译.c文件时,命令中添加-p选项(prof)或-pg选项(gprof),程序执行时就会产生执行跟踪文件mon.out(或gmon.out),再运行prof(或gprof)程序读取跟踪数据,产生运行报告。
strtok函数可以把字符串切割成若干个字符串。
任务四其实可以用字典树来做,但是很久没摸索过c语言了,实在吃力,不得不放弃了。
最后温馨提醒:以上所有代码都需要"wrapper.h"这个头文件,如果需要进行代码复用,亲手尝试代码运行结果的同学,可以私信我转发。这个头文件只是个针对课程学习内容的万能头文件,有能力的同学可以自己按需添加头文件也可,不一定需要wrapper.h
如果需要wrapper.h,可以私信我转发,但效率一般不高,如果有积分的同学可以到wrapper.h头文件CSDN下载地址https://download.csdn.net/download/enjoy_code_/12521655
自行下载,我虽然设置成了0积分,但还是被系统管理员改成了1积分,请见谅。跪谢理解。