MySQL性能突发事件问题排查技巧
点击▲关注 “数据和云” 给公众号标星置顶
更多精彩 第一时间直达
作者介绍:崔虎龙,云和恩墨-开源架构部-MySQL技术顾问,长期服务于数据中心(金融,游戏,物流)行业,熟悉数据中心运营管理的流程及规范,自动化运维 等方面。擅长MySQL,Redis,MongoDB 数据库高可用设计 和 运维故障处理,备份恢复,升级迁移,性能优化 。
经过多年的实际经验,整理了一些材料,已Linux环境下MySQL性能突发事件问题排查技巧分享给大家。
作为DBA在面对性能上突发问题的时候,是否出现过束手无策,无从下手的经历。 其实性能无非问题点在于存储、操作系统, 应用程序,数据库 等方面。
性能分析问题 并没有想象的那么难,当了解到一些常用的Linux 系统命令和MySQL的基础排查命令的时候,所有问题点都可以定位到。
先上一个Linux性能工具图谱图,Brendan D. Gregg动态追踪工具 DTrace 的作者。
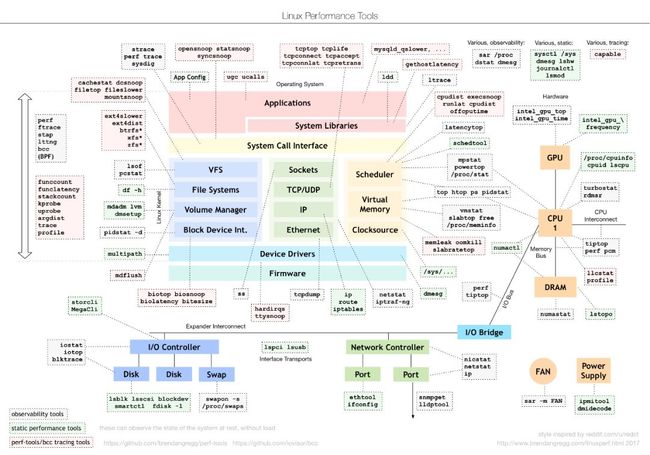
有点复杂,不用太care,只要你理解了下面的常用命令和分析点,那就可以确定绝大数性能上问题。
Linux 平台基础常用的性能收集工具:
1. top — Linux 系统进程监控
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。并且它也是 Linux 系统管理员经常使用的监控系统性能的工具。Top命令可以定期显示所有正在运行和实际运行并且更新到列表中,它显示出 CPU 的使用、内存的使用、交换内存、缓存大小、缓冲区大小、过程控制、用户和更多命令。它也会显示内存和 CPU 使用率过高的正在运行的进程。

2. vmstat — 虚拟内存统计
vmstat 命令是用于显示虚拟内存、内核线程、磁盘、系统进程、I/O 模块、中断、CPU 活跃状态等更多信息。

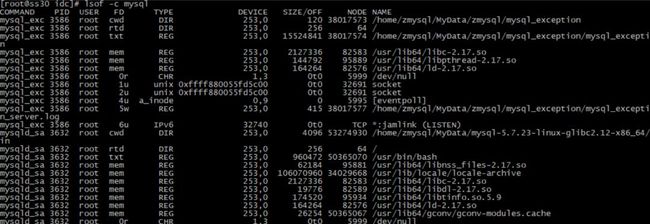
3. lsof — 打开文件列表
lsof 命令对于很多 Linux/Unix 系统都可以使用,主要以列表的形式显示打开的文件和进程。打开的文件主要包括磁盘文件、网络套接字、管道、设备和进程。这个命令很容易看出哪些文件正在使用。
4. tcpdump — 网络数据包分析器
tcpdump 是一种使用最广泛的命令行网络数据包分析,将网络中传送的数据包完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤 并提供and、or、not等逻辑语句来帮助你去掉无用的信息。

包可通过tcpdump命令解析,也可以保存成后缀为pcap的文件,使用wireshark等软件进行查看。
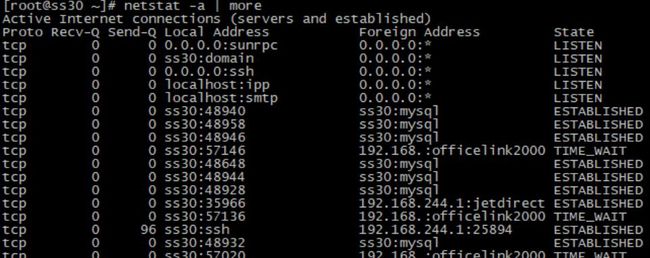
3. netstat — 网络统计
netstat 命令是一个监控网络数据包传入和传出的统计界面的命令行工具。它对于许多系统管理员去监控网络性能和解决网络相关问题是一个非常有用的工具。

4. iostat — 输入/输出统计
iostat 是收集和展示系统输入和输出存储设备统计的简单工具。这个工具通常用于查找存储设备性能问题,包括设备、本地磁盘、例如 NFS 远程磁盘。
除了上述 还有 其他一些Linux 常用的工具sar,htop, IPTraf , iotop ,iftop ,iptraf 等。
MySQL常用性能突发事件分析命令:
1. SHOW PROCESSLIST; —当前MySQL数据库的运行的所有线程

2. INNODB_TRX; — 当前运行的所有事务
## 当前运行的所有事务 ,还有具体的语句
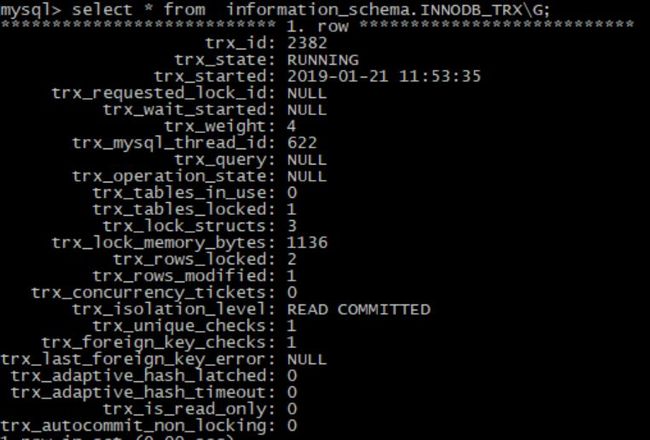
3. INNODB_LOCKS; — 当前出现的锁
## 当前事务出现的锁的语句信息
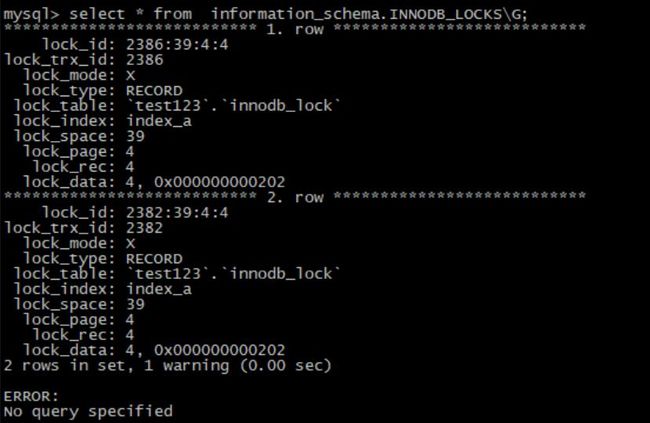
4. INNODB_LOCK_WAITS; — 锁等待的对应关系计
## 锁等待的对应关系

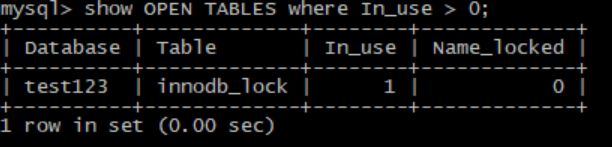
5. SHOW OPEN TABLES where In_use >0; — 当前打开表
查看哪些表在使用中,In_use列表示有多少线程正在使用某张表,Name_locked表示表名是否被锁,这一般发生在Drop或Rename命令操作这张表时。所以这条命令不能帮助解答我们常见的问题:当前某张表是否有死锁,谁拥有表上的这个锁等。
下面比较重点部分,请注意!
6. SHOW ENGINE INNODB STATUS \G; —Innodb状态
显示除了大量的内部信息,输出内容比较复杂难懂,输出内容中包含了一些平均值的统计信息,这些平均值是自上次输出结果生成以来的统计数。
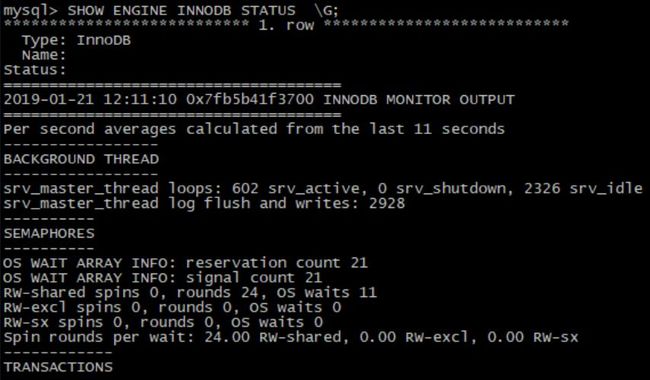
具体分析如下:
①.Header
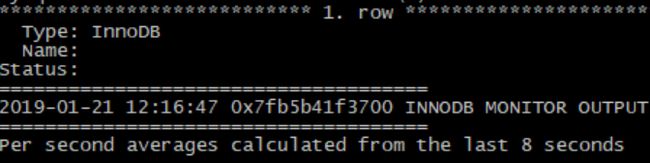
这部分简单的打印,输出的时间,以及自从上次输出的间隔时间。
②.BACKGROUND THREAD

参数 |
说明 |
Srv_master_thread loops |
Master线程的循环次数,master线程在每次loop过程中都会sleep,sleep的时间为1秒。而在每次loop的过程中会选择active、shutdown、idle中一种状态执行。Master线程在不停循环,所以其值是随时间递增的。 |
Srv_active |
Master线程选择的active状态执行。Active数量增加与数据表、数据库更新操作有关,与查询无关,例如:插入数据、更新数据、修改表等。 |
Srv_shutdown |
这个参数的值一直为0,因为srv_shutdown只有在mysql服务关闭的时候才会增加。 |
Srv_idle |
这个参数是在master线程空闲的时候增加,即没有任何数据库改动操作时。 |
Log_flush_and_write |
Master线程在后台会定期刷新日志,日志刷新是由参数innodb_flush_log_at_timeout参数控制前后刷新时间差。 |
注:Background thread部分信息为统计信息,即mysql服务启动之后该部分值会一直递增,因为它显示的是自mysqld服务启动之后master线程所有的loop和log刷新操作。通过对比active和idle的值,可以获知系统整体负载情况。Active的值越大,证明服务越繁忙。 |
|
③. SEMAPHORES 信号量
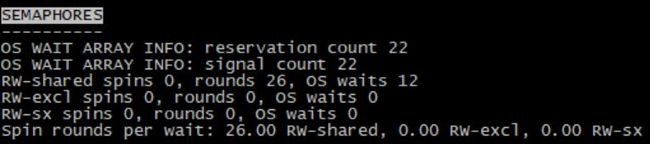
OS WAIT ARRAY INFO 操作系统等待数组的信息,它是一个插槽数组,innodb使用了多少次操作系统的等待
保留统计(reservation count)显示了innodb分配插槽的频度
信号计数(signal count) 衡量的是线程通过数组得到信号的频度
RW-shared spins:#这行显示读写的共享锁的计数器
RW-excl spins:#这行显示读写的排他锁的计数器
RW-sx spins:#这行显示共享排它锁计数器
*备注:5.7.2增加了一种新的读写锁类型称为SX共享排他锁
锁的拥有则可以读表中的任何数据,如果在相应的行上能够获得X锁,则可以修改该行。
S |
SX |
X |
|
S |
o |
o |
x |
SX |
o |
x |
x |
X |
x |
x |
x |
④. TRANSACTIONS
包含Innodb 事务(transactions)的统计信息,还有当前活动的事务列表。

transaction id: 这个ID是一个系统变量随时每次新的transaction产生而增加。
Purge done:正在进行清空(purge)操作的transaction ID。你可以通过查看第transaction id和第Purge done ID的区别,明白没有被purge的事务落后的情况。
History listlength:记录了undo spaces内unpurged的事务的个数。
⑤. FILE I/O
显示了I/O Helper thread的状态,包括一些统计信息
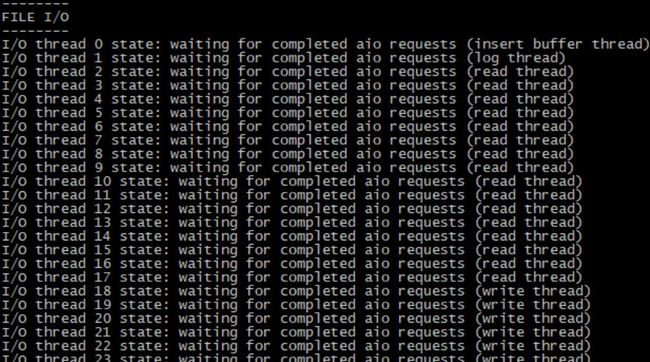

pending operations, pending的log和buffer pool thread的fsync()调用
399 OS file:行显示了reads, writes, and fsync()调用次数。
0.00 reads/s…… : 显示了每秒的统计信息
备注:“aio”表示“ 异步I/O(asynchronous I/O).”
⑥. INSERT BUFFER AND ADAPTIVE HASH INDEX
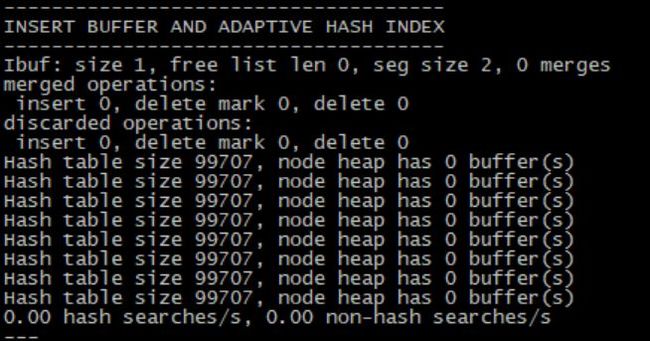
Ibuf:insertbuffer的一些信息,包括free list, segment size
Hash table:显示了hash table的一些信息最后一行显示了每秒进行了多少次hash搜索,以及非hash搜索
⑦. LOG

Log sequence number表示的是redo log buffer中的lsn
Log flushed up to表示的是redo log file中的lsn
Pages flushed up to表示的缓冲池最旧脏页的lsn
Last checkpoint at 指的就是最近一个物理页刷新到磁盘时,它的fil_page_lsn的变量值。
⑧. BUFFER POOL AND MEMORY
当前内存使用状态
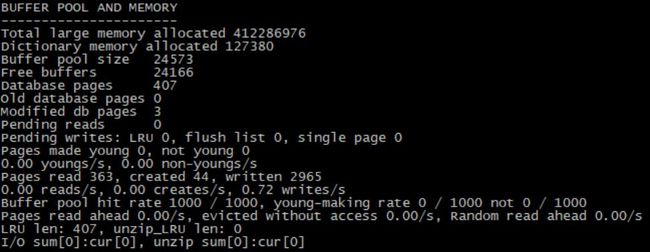
Pages read ahead:显示了每秒线性预读跟随机预读的次数
备注:InnoDB 提供了两种预读的方式,一种是 Linear read ahead,由参数innodb_read_ahead_threshold控制,当你连续读取一个 extent 的 threshold 个 page 的时候,会触发下一个 extent 64个page的预读。另外一种是Random read-ahead,由参数innodb_random_read_ahead控制,当你连续读取设定的数量的page后,会触发读取这个extent的剩余page。InnoDB 的预读功能是使用后台线程异步完成。
⑨. ROW OPERATIONS
0 queries inside InnoDB, 0 queries in queue:显示了有多少线程在Innodb内核
read views open inside InnoDB:显示了有多少read view被打开了,一个read view是一致性保证的MVCC “snapshot”
备注:innodb多版本并发(MVCC)通过read view来确定一致性读时的数据库snapshot, innodb的read view确定一条记录能否看到,
在RC隔离级别下,是每个SELECT都会获取最新的read view;
在RR隔离级别下,则是当事务中的第一个SELECT请求才创建read view
7. SHOW STATUS LIKE 'innodb_row_lock_%'; — 锁性能状态
查看当前锁性能状态

解释如下:
Innodb_row_lock_current_waits:当前等待锁的数量
Innodb_row_lock_time:系统启动到现在、锁定的总时间长度
Innodb_row_lock_time_avg:每次平均锁定的时间
Innodb_row_lock_time_max:最长一次锁定时间
Innodb_row_lock_waits:系统启动到现在、总共锁定次数
8. SQL语句EXPLAIN; — 查询优化器
EXPLAIN执行计划部分,略过(后续专题分享)
作为一个DBA,问题排查技巧是每个工程师都需要掌握的核心技能。
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
2018DTCC , 数据库大会PPT
2018DTC,2018 DTC 大会 PPT
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2018OOW ,Oracle OpenWorld 资料
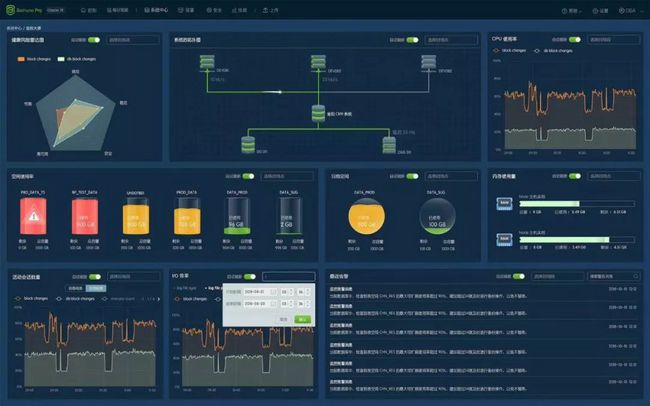
产品推荐云和恩墨Bethune Pro企业版,集监控,巡检,安全于一身,你的专属数据库实时监控和智能巡检平台,漂亮的不像实力派,你值得拥有!