音视频基础知识
人们期望将彩色格式由目前的4∶2∶0提升到4∶4∶4,以提高色彩的逼真度,对数字高清电视的清晰度期望提高到4k(3840×2160@60),甚至8k(7680×4320@60),比特深度期望由8bpp提升到12bpp,因而视频信号的传输码率将大幅度增加。于是人们希望进一步提高视频编码压缩比,及网络适应能力。
一,视频播放器原理
视频播放器播放一个互联网上的视频文件,需要经过以下几个步骤:解协议,解封装,解码视音频,视音频同步。如果播放本地文件则不需要解协议,为以下几个步骤:解封装,解码视音频,视音频同步。他们的过程如图所示。

解协议的作用,就是将流媒体协议的数据,解析为标准的相应的封装格式数据。视音频在网络上传播的时候,常常采用各种流媒体协议,例如HTTP,RTMP,或是MMS等等。这些协议在传输视音频数据的同时,也会传输一些信令数据。这些信令数据包括对播放的控制(播放,暂停,停止),或者对网络状态的描述等。解协议的过程中会去除掉信令数据而只保留视音频数据。例如,采用RTMP协议传输的数据,经过解协议操作后,输出FLV格式的数据。
解封装的作用,就是将输入的封装格式的数据,分离成为音频流压缩编码数据和视频流压缩编码数据。封装格式种类很多,例如MP4,MKV,RMVB,TS,FLV,AVI等等,它的作用就是将已经压缩编码的视频数据和音频数据按照一定的格式放到一起。例如,FLV格式的数据,经过解封装操作后,输出H.264编码的视频码流和AAC编码的音频码流。
解码的作用,就是将视频/音频压缩编码数据,解码成为非压缩的视频/音频原始数据。音频的压缩编码标准包含AAC,MP3,AC-3等等,视频的压缩编码标准则包含H.264,MPEG2,VC-1等等。解码是整个系统中最重要也是最复杂的一个环节。通过解码,压缩编码的视频数据输出成为非压缩的颜色数据,例如YUV420P,RGB等等;压缩编码的音频数据输出成为非压缩的音频抽样数据,例如PCM数据.
视音频同步的作用,就是根据解封装模块处理过程中获取到的参数信息,同步解码出来的视频和音频数据,并将视频音频数据送至系统的显卡和声卡播放出来。
二,流媒体协议
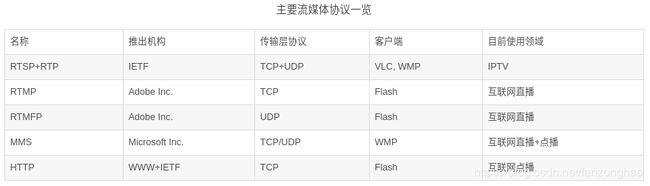
流媒体协议是服务器与客户端之间通信遵循的规定。当前网络上主要的流媒体协议如表所示。
三,封装格式
封装格式的主要作用是把视频码流和音频码流按照一定的格式存储在一个文件中。现如今流行的封装格式如下表所示:

四,视频编码
4.1,颜色空间
YCbCr色彩空间和它的变形(有时被称为YUV)是最常用的有效的表示彩色图像的方法。Y是图像的亮度(luminance/luma)分量,使用以下公式计算,为R,G,B分量的加权平均值:
Y = kr R + kgG + kbB
其中k是权重因数。
其中每个色差分量为R,G,B值和亮度Y的差值:
Cb = B -Y
Cr = R -Y
Cg = G- Y
其中,Cb+Cr+Cg是一个常数(其实是一个关于Y的表达式),所以,只需要其中两个数值结合Y值就能够计算出原来的RGB值。所以,我们仅保存亮度和蓝色、红色的色差值,这就是(Y,Cb,Cr)。
相比RGB色彩空间,YCbCr色彩空间有一个显著的优点。Y的存储可以采用和原来画面一样的分辨率,但是Cb,Cr的存储可以使用更低的分辨率。
在RGB格式中,对于宽度为w,高度为h的画面,需要w*h*3个字节来存储其每个像素的rgb信息,画面的像素数据是连续排列的.
在YUV格式中,以YUV420格式为例。宽度为w高度为h的画面,其亮度Y数据需要w*h个字节来表示(每个像素点一个亮度)。而Cb和Cr数据则是画面中4个像素共享一个Cb,Cr值。这样Cb用w*h/4个字节,Cr用w*h/4个字节。
YUV的优点:
1、YUV表示法的重要性是它的亮度信号(Y)和色度信号(U、V)是相互独立的 。
2、YUV表示法的另一个优点是可以利用人眼的特性来降低数字彩色图像所需要的存储容量。
4.2,视频编码
视频编码的主要作用是将视频像素数据(RGB,YUV等)压缩成为视频码流,从而降低视频的数据量。如果视频不经过压缩编码的话,体积通常是非常大的,一部电影可能就要上百G的空间。视频编码是视音频技术中最重要的技术之一。视频码流的数据量占了视音频总数据量的绝大部分。高效率的视频编码在同等的码率下,可以获得更高的视频质量。
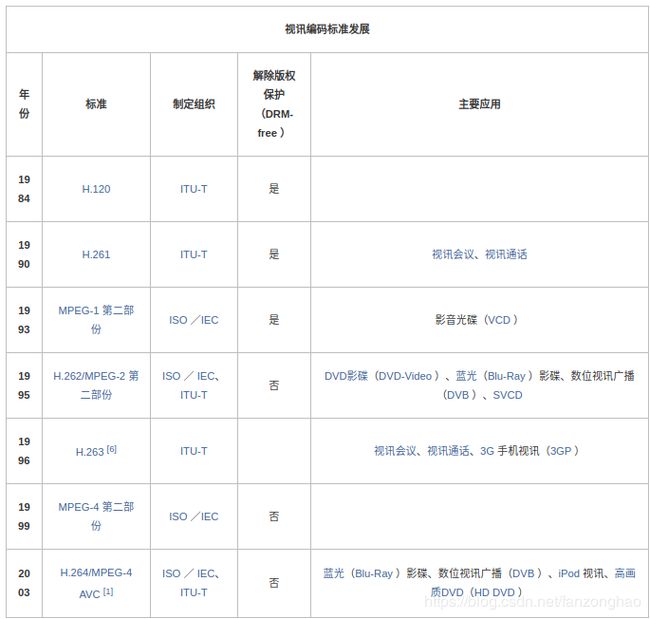
在视频编解码技术定义方面有两大标准机构。一个是国际电信联盟 (ITU) 致力于电信应用,已经开发了用于低比特率视频电话的 H.26x 标准,其中包括 H.261、H.262、H.263 与 H.264;另一个是国际标准化组织 (ISO) 主要针对消费类应用,已经针对运动图像压缩定义了 MPEG 标准。MPEG 标准包括 MPEG1、MPEG2 与 MPEG4。
将MPEG-2、MPEG-4(MPEG-4 Part 2)、H.264(MPEG-4 AVC、MPEG-4 Part 10)三者进行分辨率表现与所用带宽的比较,无论MPEG-2、MPEG-4、H.264,三者都能达1920×1080i(非交错)的高清晰度(High Definition,HD)、24fps(每秒更新24张画面)的影像画质,但传输带宽上MPEG-2需要12~20Mbps,相对的H.264只要7~8Mbps,而MPEG-4则介于两者间,更直接地说,若把MPEG-2的带宽用作基准的100%,MPEG-4要达相同效果只需要60%带宽,H.264更是低至40%,约为原MPEG-2的1/2~1/3。

FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案,几乎囊括了现存所有的视音频编码标准.
学习链接:https://blog.csdn.net/leixiaohua1020/article/details/47068015
4.3不同视频压缩编码方式比较
https://blog.csdn.net/leixiaohua1020/article/details/12237177 上述链接得出
不同视频压缩编码方式的视频质量有如下关系:
HEVC > H.264 > MPEG4 > H.263 > MPEG2
H.264最大的优势是具有很高的数据压缩比率,在同等图像质量的条件下,H.264的压缩比是MPEG-2的2倍以上,是MPEG-4的1.5~2倍。举个例子,原始文件的大小如果为88GB,采用MPEG-2压缩标准压缩后变成3.5GB,压缩比为25∶1,而采用H.264压缩标准压缩后变为879MB,从88GB到879MB,H.264的压缩比达到惊人的102∶1。
低码率(Low Bit Rate)对H.264的高的压缩比起到了重要的作用,和MPEG-2和MPEG-4ASP等压缩技术相比,H.264压缩技术将大大节省用户的下载时间和数据流量收费。尤其值得一提的是,H.264在具有高压缩比的同时还拥有高质量流畅的图像,正因为如此,经过H.264压缩的视频数据,在网络传输过程中所需要的带宽更少,也更加经济。

反复的质量比较测试已经表明,在相同的图象质量下,相比于H.264,通过H.265编码的视频码流大小比H.264减少大约39-44%。由于质量控制的测定方法不同,这个数据也会有相应的变化。通过主观视觉测试得出的数据显示,在码率减少51-74%的情况下,H.265编码视频的质量还能与H.264编码视频近似甚至更好,其本质上说是比预期的信噪比(PSNR)要好。
事实上,H.265和H.264标准在各种功能上有一些重叠。例如,H.264标准中的Hi10P部分就支持10bit色深的视频。另一个,H.264的部分(Hi444PP)还可以支持4:4:4色度抽样和14比特色深。在这种情况下,H.265和H.264的区别就体现在前者可以使用更少的带宽来提供同样的功能,其代价就是设备计算能力:H.265编码的视频需要更多的计算能力来解码。目前已经有支持H.265解码的芯片发布了——美国博通公司(Broadcom)在今年1月初的CES大展上发布了一款Brahma BCM 7445芯片,它是一个采用28纳米工艺的四核处理器,可以同时转码四个1080P视频数据流或解析分辨率为4096×2160的H.265编码超高清视频。
4.4 版权
五,专利
各家公司把自己的专利放进“专利池”(patent pool)中,由专利授权组织(池)公司 MPEG LA 统一进行管理.
关于新的视频标准专利,你可能得多交几份钱了!
AVC/HEVC的专利费
六、H264相关概念
6.1序列
H264编码标准中所遵循的理论依据个人理解成:参照一段时间内相邻的图像中,像素、亮度与色温的差别很小。所以当面对一段时间内图像我们没必要去对每一幅图像进行完整一帧的编码,而是可以选取这段时间的第一帧图像作为完整编码,而下一幅图像可以记录与第一帧完整编码图像像素、亮度与色温等的差别即可,以此类推循环下去。
什么叫序列呢?上述的这段时间内图像变化不大的图像集我们就可以称之为一个序列。序列可以理解为有相同特点的一段数据。但是如果某个图像与之前的图像变换很大,很难参考之前的帧来生成新的帧,那么久结束删一个序列,开始下一段序列。重复上一序列的做法,生成新的一段序列。
6.2、帧类型

在H.264基准类中,仅使用I帧和P帧以实现低延时,因此是网络摄像机和视频编码器的理想选择。
H264结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由16x16的yuv数据组成。宏块作为H264编码的基本单位。
在H264协议内定义了三种帧,分别是I帧、B帧与P帧。I帧就是之前所说的一个完整的图像帧,而B、帧与P帧所对应的就是之前说的不编码全部图像的帧。P帧与B帧的差别就是P帧是参考之前的I帧而生成的,而B帧是参考前后图像帧编码生成的。
6.3、GOP(画面组)
GOP我个人也理解为跟序列差不多意思,就是一段时间内变化不大的图像集。GOP结构一般有两个数字,如M=3,N=12。M指定I帧和P帧之间的距离,N指定两个I帧之间的距离。上面的M=3,N=12,GOP结构为:IBBPBBPBBPBBI。在一个GOP内I frame解码不依赖任何的其它帧,p frame解码则依赖前面的I frame或P frame,B frame解码依赖前最近的一个I frame或P frame 及其后最近的一个P frame。
6.4、IDR帧(关键帧)
在编码解码中为了方便,将GOP中首个I帧要和其他I帧区别开,把第一个I帧叫IDR,这样方便控制编码和解码流程,所以IDR帧一定是I帧,但I帧不一定是IDR帧;IDR帧的作用是立刻刷新,使错误不致传播,从IDR帧开始算新的序列开始编码。I帧有被跨帧参考的可能,IDR不会。
I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样,例如:
IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15 这里的B8可以跨过I10去参考P7
------------------------------------------------------------------------
IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12 这里的B9就只能参照IDR8和P11,不可以参考IDR8前面的帧
作用:
H.264引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
6.5、H264压缩方式
H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
帧内(Intraframe)压缩也称为空间压缩(Spatialcompression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码jpeg差不多。
帧间(Interframe)压缩的原理是:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporalcompression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Framedifferencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
6.5.1 帧内预测编码

可利用这种像素间的相关性进行压缩编码。例如,当前像素X(设为立即传送的像素)可用前一个像素a、b或c,或三者的线性加权来预测,假设预测像素值为A=p1*a+p2*b+p3*c。a、b、c被称为参考像素。实际传送时,把实际像素X(当前值)和参考像素(预测值)相减,只传送X-A,到了接收端再把(X-A)+A恢复成X。由于A是已传送的(在接收端被存储),于是得到当前值。由于X与A相似,(X-A)值很小,视频信号被压缩,这种压缩方式称为帧内预测编码。
6.5.2 帧间预测编码
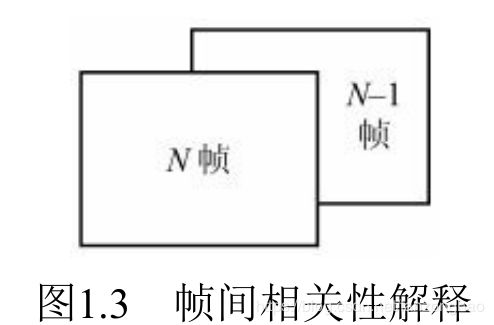
一般而言,帧间预测编码的编码效率比帧内编码更高。可利用图1.3所示的帧间相关性进行压缩编码。由于邻近帧之间的相关性一般比帧内像素间的相关性更强,因此压缩比也更大。由此可见,利用像素之间(帧内)的相关性和帧间的相关性,找到相应的参考像素或参考帧作为预测值,可以实现视频压缩编码。
1.单向预测
(1)预测原理
图3.11所示为单向预测的预测编码框图。

当前帧图像![]() 与预测图像
与预测图像![]() 相减后的帧误差
相减后的帧误差![]() ,经量化器量化后输出
,经量化器量化后输出![]() ,传送到信道。预测图像
,传送到信道。预测图像![]() 与
与![]() 相加,得
相加,得![]() ,当不计量化失真时,即当前的
,当不计量化失真时,即当前的![]() 。
。
把当前帧![]() 与帧存储器输出的前一帧
与帧存储器输出的前一帧![]() (也称参考帧)同时输入到运动参数估值器中,经搜索、比较得到运动矢量MV。此MV输入到运动补偿预测器中,得到预测图像
(也称参考帧)同时输入到运动参数估值器中,经搜索、比较得到运动矢量MV。此MV输入到运动补偿预测器中,得到预测图像![]() 。预测图像不可能完全等同于当前图像
。预测图像不可能完全等同于当前图像![]() 无论预测得如何精确,总存在帧
无论预测得如何精确,总存在帧
误差![]() 。由上述可知,利用上一帧的图像经运动矢量位移作为预测值的方法称为单向预测或单向时间预测。这时,有
。由上述可知,利用上一帧的图像经运动矢量位移作为预测值的方法称为单向预测或单向时间预测。这时,有

其中,(i, j)即运动矢量。如何减小帧差和更精确地预测当前像素,是提高帧间压缩编码效率的关键。
2.双向预测
有时,不只是利用前一帧像素进行预测,还需利用后一帧像素,即预测值为:
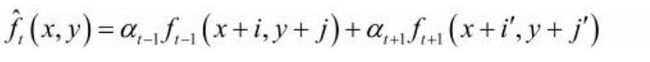
其中, 分别为t到t-1和t到t+1间的运动矢量MV,
分别为t到t-1和t到t+1间的运动矢量MV, 分别为前向和后向预测系数,可按最佳预测公式确定。
分别为前向和后向预测系数,可按最佳预测公式确定。
这时,用前向参考帧预测当前帧称为前向运动补偿,利用后向参考帧预测当前帧称为后向运动补偿,利用前、后向同时预测,就称为双向预测运动补偿。在诸如会议电视、可视电话等实时通信中,一般不应用双向预测,因为后向预测在当前帧之后进行,会引入编码时延。它可用在广播电视系统中,如采用MPEG标准的编码系统,特别针对一些暴露区域,即t-1帧尚未暴露而t+1帧已呈
现出来的区域。图3.14为单向和双向预测编码举例。为了进一步提高编码效率,多帧预测(包括单向和双向预测)被引入,如H.264标准参考帧可达16帧。

6.5.3编码原理

大量统计表明,视频信号中包含着能量上占大部分的直流和低频成分(图像的平坦部分),还有少量的高频成分(图像的细节部分)。因此,可以用另一种方法进行视频编码,将图像经过某种数学变换后,得到变换域中的图像(如图1.4所示),其中u、v分别是空间频率坐标轴。在图1.4中,用“o”表示的低频和直流占图像能量中的大部分;而用“×”表示的高频成分则是少量的;其余均是零值,用“O”表示。于是可用较少的码表示直流、低频以及高频,而“O”则不必用码表示,由此可完成压缩编码。
6.6、压缩方式说明
Step1:分组,也就是将一系列变换不大的图像归为一个组,也就是一个序列,也可以叫GOP(画面组);
Step2:定义帧,将每组的图像帧归分为I帧、P帧和B帧三种类型;
Step3:预测帧, 以I帧做为基础帧,以I帧预测P帧,再由I帧和P帧预测B帧;
Step4:数据传输, 最后将I帧数据与预测的差值信息进行存储和传输。
6.7 流程图
编码:
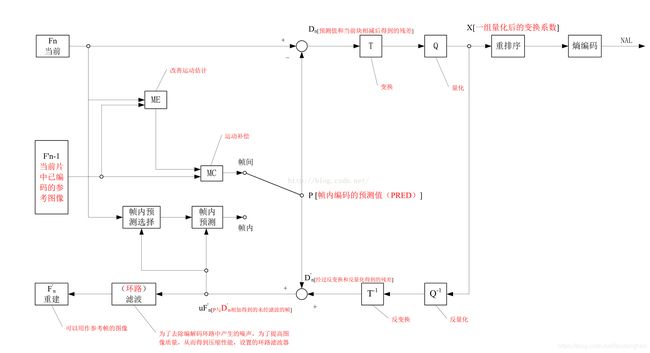
编码器採用的仍是变换和预測的混合编码法。在上图中,输入的帧或场Fn以宏块为单位被编码器处理。首先,按帧内或者帧间预測编码的方法进行处理。假设採用帧间预測编码,其预測值PRED是由当前片中前面已编码的參考图像经运动补偿(MC)后得到,当中參考图像用F’n-1表示。预測值PRED和当前块相减后,产生一个残差块Dn,经块变换、量化后产生一组量化后的变换系数X,再经熵编码,与解码所需的一些头信息一起组成压缩后的码流,经NAL(网络自适应层)供传输和存储用。
变换和量化.
解码:

在图6.2中,将编码器的NAL输出的H264比特流经熵解码得到量化后的一组变换系数X,再经反量化、反变换,得到残差D’n。利用从该比特流中解码出的头信息,解码器就产生一个预測块PRED,它和编码器中的原始PRED是同样的。当该解码器产生的PRED与残差D’n相加后,就得到了uF’n,再经滤波后,最后就得到滤波后的解码输出图像F’n。
上面介绍了视频压缩编码过程中的几个重要的方法。在实际应用中这几个方法不是分离的,通常将它们结合起来使用以达到最好的压缩效果。下图给出了混合编码(即变换编码+ 运动估计和运动补偿+ 熵编码)的模型。该模型普遍应用于MPEG1,MPEG2,H.264等标准中。
混合编码
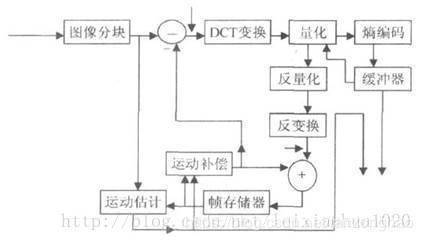
从图中我们可以看到,当前输入的图像首先要经过分块,分块得到的图像块要与经过运动补偿的预测图像相减得到差值图像X,然后对该差值图像块进行DCT变换和量化,量化输出的数据有两个不同的去处:一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。另一个应用是进行反量化和反变化后的到信号X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。
参考文献:
https://blog.csdn.net/leixiaohua1020/article/details/18893769
https://blog.csdn.net/leixiaohua1020/article/details/28114081