内存管理九 linux内存页面回收
一、概序:
内核中的页面可以分为两类,一类是使用完毕便无保存的价值,所以立即便可释放、回收,这种页面的
周转很简单:空闲 -> (分配)-> 使用 -> (释放)-> 空闲,例如通过kmalloc/vmalloc/alloc_page()分配的内存。
另外一类是使用完毕了,其内容仍有保存的价值,只要条件允许,把这些页面“养起来”可以提供后面的工作效率,
这些页面释放后会加入到LRU的链表中,经过时间的缓冲让其慢慢老化,如果再次使用到,可以直接将页面内容
继续使用,否则等待被回收。如:文件系统中用来缓冲的文件目录结构,文件系统读写操作的缓冲区。
在内存紧张时,内核会将很少使用的内存换出到交换分区,以便释放出物理内存,此种机制成为“页交换”,
也统称为页面回收,页面回收涉及到LRU链表、内存回收算法、Kswapd内核线程等知识,下面会做相关介绍。
二、LRU链表:
1、LRU链表:
(1)LRU链表按照zone来配置,即每一个zone管理自己单独的LRU链表,在struct zone的结构体中有一个
lruvec的成员执行这些链表,根据不同的页面类型和页面的活跃度有如下5中类型的链表:
- 不活跃匿名页面链表LRU_INACTIVE_ANON
- 活跃匿名页面链表LRU_ACTIVE_ANON
- 不活跃文件映射页面链表LRU_INACTIVE_FILE
- 活跃映射页面链表LRU_ACTIVE_FILE
- 不可回收页面链表LRU_UNEVICTABLE
struct zone {
/* Fields commonly accessed by the page reclaim scanner */
spinlock_t lru_lock;
struct lruvec lruvec;
......
}
struct lruvec {
struct list_head lists[NR_LRU_LISTS];
struct zone_reclaim_stat reclaim_stat;
};
enum lru_list {
LRU_INACTIVE_ANON = LRU_BASE,
LRU_ACTIVE_ANON = LRU_BASE + LRU_ACTIVE,
LRU_INACTIVE_FILE = LRU_BASE + LRU_FILE,
LRU_ACTIVE_FILE = LRU_BASE + LRU_FILE + LRU_ACTIVE,
LRU_UNEVICTABLE,
NR_LRU_LISTS
};(2)页面加入到LRU链表lru_cache_add():
通过list_add函数将页面添加到LRU链表lruvec->list结构的头部:
lru_cache_add -> __pagevec_lru_add -> __pagevec_lru_add_fn -> add_page_to_lru_list-> list_add
static __always_inline void add_page_to_lru_list(struct page *page,
struct lruvec *lruvec, enum lru_list lru)
{
int nr_pages = hpage_nr_pages(page);
mem_cgroup_update_lru_size(lruvec, lru, nr_pages);
list_add(&page->lru, &lruvec->lists[lru]);
__mod_zone_page_state(lruvec_zone(lruvec), NR_LRU_BASE + lru, nr_pages);
}lru_to_page(&lru_list)和list_del(&page->lru )实现从LRU链表摘除页面,lru_to_page从链表的尾部摘除页面,实现了
先进先出的算法(FIFO),随着时间的推移,不活跃的LRU都移动到了LRU链表的尾部,比较适合被回收,如下图所示:
#define lru_to_page(head) (list_entry((head)->prev, struct page, lru))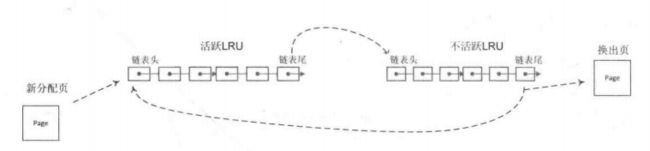
2、第二次机会算法:
经典LRU链表的FIFO算法,存在一定的弊端,可能会将经常使用的页面在LRU链表的尾部被回收掉,故第二次
机会算法在此基础做了修改,设置了访问状态位(硬件控制的比特位):
- 页面被访问,访问的状态位置1;
- 页面回收时会检查访问位,如果为0,淘汰页面,如果为1,给此页面第二次机会;
- 如果一个页面硬件被访问,其访问位一直为1,就一直不会被淘汰;
- 内核使用PG_active表示页面活跃度,PG_referenced表示页面是否被访问过;
其中涉及的主要操作函数有:
- mark_page_accessed()控制状态位;
- page_referenced()判断page是否访问调用;
- page_check_references()扫描不活跃LRU链表,判断页面是否活跃;
(1)mark_page_accessed(struct page *page)
//kernel-4.4/mm/swap.c
void mark_page_accessed(struct page *page)
{
if (!PageActive(page) && !PageUnevictable(page) &&
PageReferenced(page)) {
if (PageLRU(page))
activate_page(page);
else
__lru_cache_activate_page(page);
ClearPageReferenced(page);
if (page_is_file_cache(page))
workingset_activation(page);
} else if (!PageReferenced(page)) {
SetPageReferenced(page);
}
}a、if PG_active == 0 && PG_reference == 1:
把该页加入到活跃LRU,并设置PG_active = 1;
清除PG_reference = 0;
b、如果PG_reference == 0:
设置PG_reference = 1;
(2)page_check_references(struct page *page, struct scan_control *sc)
//kernel-4.4/mm/vmscan.c
static enum page_references page_check_references(struct page *page,
struct scan_control *sc)
{
int referenced_ptes, referenced_page;
unsigned long vm_flags;
//page_referenced检查该页有多少个访问引用pte
referenced_ptes = page_referenced(page, 1, sc->target_mem_cgroup,
&vm_flags);
//返回该页面PG_reference标志位的值
referenced_page = TestClearPageReferenced(page);
if (referenced_ptes) {
//如果该页面是匿名页面,则加入到活跃链表
if (PageSwapBacked(page))
return PAGEREF_ACTIVATE;
SetPageReferenced(page);
//如果最近第二次访问的page cache或shared page cache,则介入到活跃链表
if (referenced_page || referenced_ptes > 1)
return PAGEREF_ACTIVATE;
//可执行的文件加入到活跃链表
if (vm_flags & VM_EXEC)
return PAGEREF_ACTIVATE;
//如果都不符合尚需三种情况继续留在不活跃链表等待回收
return PAGEREF_KEEP;
}
//如果没有访问引用PTE,可以尝试回收此page
if (referenced_page && !PageSwapBacked(page))
return PAGEREF_RECLAIM_CLEAN;
return PAGEREF_RECLAIM;
}
(3)page_referenced
page_referenced的函数比较长,这里不再展示出来,此函数主要完成的工作如下:
- 利用RMAP系统遍历所有映射该页面的pte;
- 对于每个pte,如果L_PTE_YOUNG比特位置位,说明之前被访问过,referenced技术加1,然后情况比特位;
- 返回referenced计数,表示该页有多少个访问引用pte;
三、kswapd内核线程:
kswapd是非常重要的内核线程,负责在内存不足的情况下回收页面,下面会分几个不同的阶段来介绍。
1、kswapd初始化及唤醒:
kswapd在初始化时会在node节点创建一个kswapd%d的内核线程,在前面有说过每一个node节点都有
一个pg_data_t的结构体来描叙,与kswapd相关的结构体成员如下:
typedef struct pglist_data {
//kswapd_wait是一个等待队列
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
//在内存水位低的时候,通过wakeup_kswapd唤醒kswapd,并传入如下两个参数
enum zone_type classzone_idx;
int kswapd_max_order;
} pg_data_t;int kswapd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
int ret = 0;
if (pgdat->kswapd)
return 0;
pgdat->kswapd = kthread_run(kswapd, pgdat, "kswapd%d", nid);
return ret;
}系统启动时会通过kswapd_try_to_sleep()函数中睡眠让出CPU,alloc_page在低水位时(ALLOC_WAMRK_LOW)
无法分配出内存时,会通过wakeup_kswapd来唤醒,其中唤醒kswapd线程的流程如下:
alloc_pages-> __alloc_pages_nodemask -> __alloc_pages_slowpath ->wake_all_kswapds
void wakeup_kswapd(struct zone *zone, int order, enum zone_type classzone_idx)
{
pg_data_t *pgdat;
......
pgdat->kswapd_max_order = order;
pgdat->classzone_idx = min(pgdat->classzone_idx, classzone_idx);
wake_up_interruptible(&pgdat->kswapd_wait);
}2、kswapd执行函数回收内存:
在内存低的时候,唤醒了kswapd回去执行期执行函数,当内存节点的的水位处于平衡状态时,停止回收内存:
//balance_pgdat是内存回收的核心函数
static int kswapd(void *p)
{
......
for ( ; ; ) {
balanced_classzone_idx = classzone_idx;
balanced_order = balance_pgdat(pgdat, order,
&balanced_classzone_idx);
}
}static unsigned long balance_pgdat(pg_data_t *pgdat, int order,
int *classzone_idx)
{
do {
//从高端zone查找第一个处于不平衡水位的end_zone
for (i = pgdat->nr_zones - 1; i >= 0; i--) {
if (!zone_balanced(zone, order, 0, 0)) {
end_zone = i;
break;
}
}
//从低端zone开始回收页面至end_zone
for (i = 0; i <= end_zone; i++) {
struct zone *zone = pgdat->node_zones + i;
if (kswapd_shrink_zone(zone, end_zone,
&sc, &nr_attempted))
raise_priority = false;
}
//加大扫描粒度进行回收,并且检查最低端zone到classzone_idx的zone是否处于平衡状态
//classzone_idx是内存分配时计算出的最适合内存分配的zone的编号
} while (sc.priority >= 1 &&
!pgdat_balanced(pgdat, order, *classzone_idx));
*classzone_idx = end_zone;
return order;
}
其中内存回收涉及到的核心函数如下:
(1)kswapd_shrink_zone:是真正扫描页面和进行页面回收的函数,返回true表明回收成功;
(2)shrink_zone/shrink_lruvecshrink_list:用于扫描zone中所有可回收的页面;
(3)shrink_active_list:扫描活跃LRU链表,看是否有页面可以迁移到不活跃LRU链表中;
(4)shrink_inactive_list:扫描不活跃LRU链表尝试回收页面,返回已回收的页面数量;
3、总结:
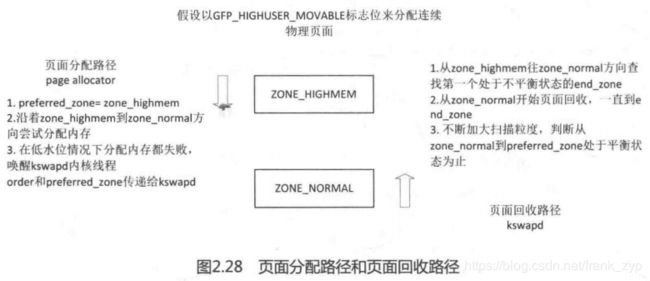
页面分配和回收的流程如下,是两个相反的方向,这样可以避免一些资源或锁等的竞争关系,从而
代码一些资源上的浪费和不必要的BUG,这种设计的思想非常好:
作者:frank_zyp
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文无所谓版权,欢迎转载。