回到归因模型上,马尔科夫链模型实质就是:访客下一次访问某个渠道的概率,取决于这次访问的渠道。
归因分析 (Attribution Analysis) 模型解析 - 简书一、什么是归因分析? 在复杂的数据时代,我们每天都会面临产生产生的大量的数据以及用户复杂的消费行为路径,特别是在互联网广告行业,在广告投放的效果评估上,往往会产生一系列的问题...
一、什么是归因分析?
在复杂的数据时代,我们每天都会面临产生产生的大量的数据以及用户复杂的消费行为路径,特别是在互联网广告行业,在广告投放的效果评估上,往往会产生一系列的问题:
· 哪些营销渠道促成了销售?
· 他们的贡献率分别是多少?
· 而这些贡献的背后,是源自于怎样的用户行为路径而产生的?
· 如何使用归因分析得到的结论,指导我们选择转化率更高的渠道组合?
归因分析 (Attribution Analysis) 要解决的问题就是广告效果的产生,其功劳应该如何合理的分配给哪些渠道。
你可能第一反应就是:当然是我点了哪个广告,然后进去商品详情页产生了购买以后,这个功劳就全部归功于这个广告呀!没有错,这也是当今最流行的分析方法,最简单粗暴的单渠道归因模型 ------ 这种方法通常将销售转化归功于消费者第一次 (首次互动模型,First Model) 或者最后一次接触 (末次互动模型,Last Model) 的渠道。但是显然,这是一个不够严谨和准确的分析方法。
举个例子:
小陈同学在手机上看到了朋友圈广告发布了最新的苹果手机,午休的时候刷抖音看到了有网红在评测最新的苹果手机,下班在地铁上刷朋友圈的时候发现已经有小伙伴收到手机在晒图了,于是喝了一杯江小白壮壮胆回家跟老婆申请经费,最后老婆批准了让他去京东买,有保障。那么请问,朋友圈广告、抖音、好友朋友圈、京东各个渠道对这次成交分别贡献了多少价值?----- 太难了,笔者也不知道
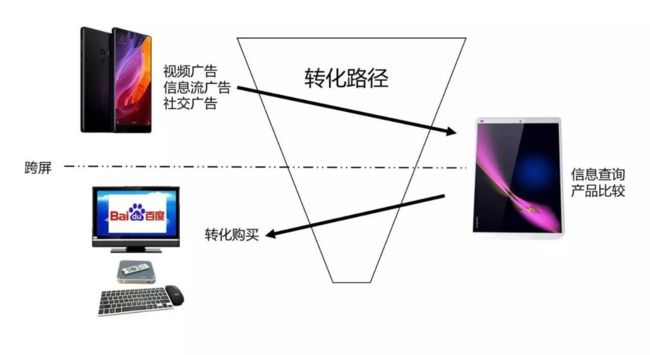
再举个例子:下图是某电商用户行为序列图示,各字母代表的含义是 D - 广告位,Q - 商品详情页,D - 推荐位,M - 购买商品。
那么请问,Da、Db、Dc 这三种广告位对这次用户购买行为的贡献率分别是多少?------ 这个问题相对简单点,等你看完文章自然就懂了!

我们发现,现实情况往往是很复杂的多渠道投放,在衡量其贡献价值以及做组合渠道投放力度的分配时,只依靠单渠道归因分析得到的结果和指导是不科学的,于是引入了多渠道归因分析的方法。当然,多渠道归因分析也不是万能的,使用怎样的分析模型最终还是取决于业务本身的特性以及考虑投入其中的成本。
二、几种常见的归因模型
1、末次互动模型
也称,最后点击模型 ----- 最后一次互动的渠道获得 100% 的功劳,这是最简单、直接,也是应用最为广泛的归因模型。

优点:首先它是最容易测量的归因模型,在分析计方面不容易发生错误。另外由于大部分追踪的 cookie 存活期只有 30-90 天(淘宝广告的计算周期最长只有 15 天),对于顾客的行为路径、周期比较长的场景,在做归因分析的时候可能就会发生数据的丢失,而对于末次互动模型,这个数据跟踪周期就不是那么特别重要了。
弊端:这种模型的弊端也是比较明显,比如客户是从收藏夹进入商品详情页然后形成了成交的,按照末次归因模型就会把 100% 的功劳都归功于收藏夹(直接流量)。但是真实的用户行为路径更接近于产生兴趣、信任、购买意向、信息对比等各种环节,这些都是其他渠道的功劳,在这个模型中则无法统计进来,而末次渠道的功劳评估会被大幅高估。
适用于:转化路径少、周期短的业务,或者就是起临门一脚作用的广告,为了吸引客户购买,点击直接落地到商品详情页。
2、末次非直接点击互动模型
上面讲到的末次互动模型的弊端是数据分析的准确性受到了大量的 "直接流量" 所误导,所以对于末次非直接点击模型,在排除掉直接流量后会得到稍微准确一点的分析结果。
在营销分析里,直接流量通常被定义为手动输入 URL 的访客流量。然而,现实是市场上的所有分析工具都把没有来源页的流量视为直接流量。比如:文章里没有加跟踪代码的链接、用户直接复制粘贴 URL 访问等等
从上面的案例中,我们可以想象,用户是从淘宝收藏夹里点了一个商品然后进行了购买,但是实际上他可能是点了淘宝直通车后把这个商品加入到收藏夹的,那么在末次非直接点击互动模型里,我们就可以把这个功劳归功于淘宝直通车。
适用于:如果你的公司认为,你们业务的直接流量大部分都被来自于被其他渠道吸引的客户,需要排除掉直接流量,那么这种模型会很适合你们。
3、末次渠道互动模型
末次渠道互动模型会将 100% 的功劳归于客户在转化前,最后一次点击的广告渠道。需要注意这里的 "末次互动" 是指任何你要测量的转化目标之前的最后一次互动,转化目标可能是销售线索、销售机会建立或者其他你可以自定义的目标。
优点:这种模式的优点是通常跟各渠道的标准一致,如 Facebook Insight 使用末次 Facebook 互动模型,谷歌广告分析用的是末次谷歌广告互动模型等等。
弊端:很明显当你在多渠道同时投放的时候,会发生一个客户在第一天点了 Facebook 的广告,然后在第二天又点击了谷歌广告,最后并发生了转化,那么在末次渠道模型中,Facebook 和谷歌都会把这次转化的 100% 功劳分别归到自己的渠道上。这就导致各个部门的数据都看起来挺好的,各个渠道都高估了自己影响力,而实际效果则可能是折半,如果单独使用这些归因模型并且把他们整合到一个报告中,你可能会得到 "翻倍甚至三倍" 的转化数据。
适用于:单一渠道,或者已知某个渠道的价值特别大
4、首次互动模型
首次互动的渠道获得 100% 的功劳。
如果,末次互动是认为,不管你之前有多少次互动,没有最后一次就没有成交。那么首次互动就是认为,没有我第一次的互动,你们剩下的渠道连互动都不会产生。
换句话说,首次互动模型更加强调的是驱动用户认知的、位于转化漏斗最顶端的渠道。
优点:是一种容易实施的单触点模型
弊端:受限于数据跟踪周期,对于用户路径长、周期长的用户行为可能无法采集真正的首次互动。
适用于:这种模型适用于没什么品牌知名度的公司,关注能给他们带来客户的最初的渠道,对于扩展市场很有帮助的渠道。
5、线性归因模型
对于路径上所有的渠道,平等地分配他们的贡献权重。

线性归因是多触点归因模型中的一种,也是最简单的一种,他将功劳平均分配给用户路径中的每一个触点。
优点:他是一个多触点归因模型,可以将功劳划分给转化漏斗中每个不同阶段的营销渠道。另外,他的计算方法比较简单,计算过程中的价值系数调整也比较方便。
弊端:很明显,线性平均划分的方法不适用于某些渠道价值特别突出的业务。比如,一个客户在线下某处看到了你的广告,然后回家再用百度搜索,连续三天都通过百度进入了官网(真实用户场景也许就是用户懒得记录或者收藏官网地址),并在第四天成交。那么按照线性归因模型,百度会分配到 75% 的权重,而线下某处的广告得到了 25% 的权重,这很显然并没有给到线下广告足够的权重。
适用于:根据线性归因模型的特点,他更适用于企业期望在整个销售周期内保持与客户的联系,并维持品牌认知度的公司。在这种情况下,各个渠道在客户的考虑过程中,都起到相同的促进作用。
6、时间衰减归因模型
对于路径上的渠道,距离转化的时间越短的渠道,可以获得越多的功劳权重。
时间衰减归因模型基于一种假设,他认为触点越接近转化,对转化的影响力就越大。这种模型基于一个指数衰减的概念,一般默认周期是 7 天。也就是说,以转化当天相比,转化前 7 天的渠道,能分配 50% 权重,前 14 天的渠道分 25% 的权重,以此类推...
优点:相比线性归因模型的平均分权重的方式,时间衰减模型让不同渠道得到了不同的权重分配,当然前提是基于 "触点离转化越近,对转化影响力就越大" 的前提是准确的情况下,这种模型是相对较合理的。
弊端:这种假设的问题就是,在漏洞顶部的营销渠道永远不会得到一个公平的分数,因为它们总是距离转化最远的那个。
适用于:客户决策周期短、销售周期短的情况。比如,做短期的促销,就打了两天的广告,那么这两天的广告理应获得较高的权重。
7、基于位置的归因模型(U 型归因)
基于位置的归因模型,也叫 U 型归因模型,它其实是混合使用了首次互动归因和末次互动归因的结果。
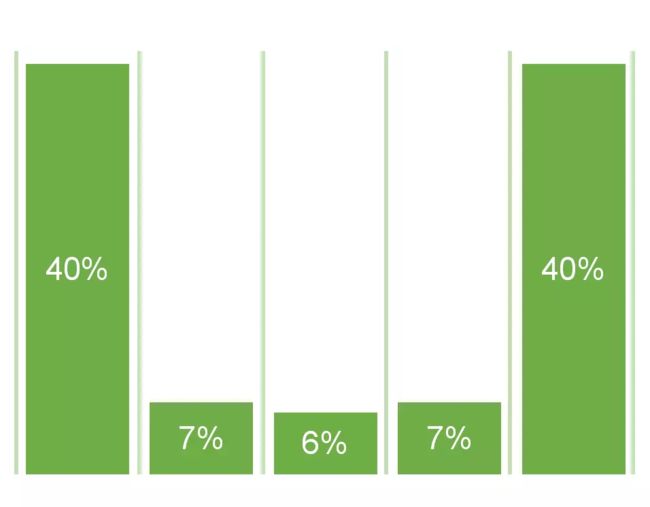
U 型归因模型也是一种多触点归因模型,实质上是一种重视最初带来线索和最终促成成交渠道的模型,一般它会给首次和末次互动渠道各分配 40% 的权重,给中间的渠道分配 20% 的权重,也可以根据实际情况来调整这里的比例。
U 型归因模型非常适合那些十分重视线索来源和促成销售渠道的公司。该模型的缺点则是它不会考虑线索转化之后的触点的营销效果,而这也使得它成为销售线索报告或者只有销售线索阶段目标的营销组织的理想归因模型。
归因分析模型的计算原理演绎
以下,我们通过神策数据提供的归因模式,做一次计算原理的演绎:
下图是通过神策分析所得到某电商用户行为序列图示。在图示中,各字母代表的含义是 D - 广告位、Q - 商品详情页、D - 推荐位、M - 购买商品。目标转化事件是 “购买商品”,为了更好地 “配对”,运营人员将 M1(目标转化事件——购买商品 1)与 Q1(前项关联事件——商品 1 详情)设置了属性关联,同样将 M2 与 Q2 进行关联。

该场景中,发生了两次购买行为,神策分析进行归因时会进行两轮计算,产生计算结果。
(一)第一轮计算:
第一步,从 M1 开始向前遍历寻找 Q1 以及离 Q1 最近发生的广告浏览。

、
如图所示,不难得到结果 M1=[Dc,Dc,Da]。
第二步,我们带入分析模型中,进行功劳的分配。运营人员选择 “位置归因” 的分析模型,根据 “位置归因” 的计算逻辑,第一个 “待归因事件” 和最后一个 “待归因事件” 各占 40%,中间平分 20%。
第一轮我们得到结果:Dc=0.4;Dc=0.2;Da=0.4
(二)第二轮计算
从 M2 开始向前遍历寻找 Q2 以及离 Q2 最近发生的广告浏览。

这里值得强调的是,即使第一轮中计算过该广告,在本轮计算时依然会参与到计算中,因为经常会出现一个广告位同时推荐多个商品的情况。
我们不难得到结论,M2=[Dc,Db]。基于这个结论,我们通过 “位置归因” 得到结果:Dc=0.5;Db=0.5(不足 3 个时会有特殊处理)。
经过两轮计算,我们得出结论:Dc=1.1;Da=0.4;Db=0.5,则广告位 c 的贡献最大、广告位 b 贡献次之,广告位 a 的贡献最小。
8、马尔科夫链
马尔科夫链模型来自于数学家 Andrew Markov 所定义的一种特殊的有序列。马尔科夫链 (Markov Chain),描述了一种状态序列,其每个状态值取决于前面有限个状态。马尔科夫链是具有马尔科夫性质的随机变量的一个数列。
马尔科夫链思时间、状态都是离散的马尔科夫过程,是将来发生的事情,和过去的经理没有任何关系(只和当前有关系)。通俗的讲:今天的事情只取决于昨天,而明天的事情只取决于今天。
谷歌的 PageRank,就是利用了马尔科夫模型。假设有 A,B,C 三个网页,A 链向 B,B 链上 C。那么 C 分到的 PR 权重只由 B 决定,和 A 没有任何关系。如果互联网上所有的网页不断地重复计算 PR,很容易可以想到这个 PR 值最后会收敛,并且区域一个稳定的值,这也就是为什么它会被谷歌用来确定网页等级。
回到归因模型上,马尔科夫链模型实质就是:访客下一次访问某个渠道的概率,取决于这次访问的渠道。
归因模型的选择,很大程度上决定转化率计算结果,像前面讲的首次互动、末次互动等模型,实际上需要人工来分配规则的算法,显然它并不是一种 “智能化” 的模型选择。而且因为各个推广渠道的属性和目的不同,我们也无法脱离用户整个的转化路径来单独进行计算。因此,马尔科夫链归因模型实质上是一种以数据驱动的(Data-Driven)、更准确的归因算法。
马尔科夫链归因模型适用于渠道多、数量大、有建模分析能力的公司。
那么具体马尔科夫链怎么玩?(请自备图论知识)
如果将各推广渠道视为系统状态,推广渠道之间的转化视为系统状态之间的转化,可以用马尔科夫链表示用户转化路径。
马尔科夫链表示系统在 t+1 时间的状态只与系统在 t 时间的状态有关系,与系统在 t-1,t-2,...,t0 时间的状态无关,平稳马尔科夫链的转化矩阵可以用最大似然估计,也就是统计各状态之间的转化概率计算得到。用马尔科夫链图定义渠道推广归因模型:
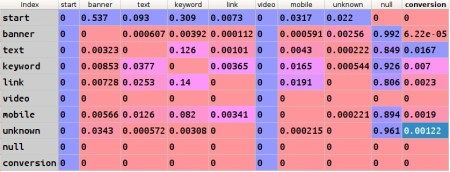
1、状态集合,定义为 banner,text,keyword,link,video,mobile,unknown 7 种推广类型加上 start,null,conversion 3 种系统状态
2、稳定状态下的转化矩阵,通过某公司 web 网站 20 天的原始 click 数据计算的得到如下状态转化矩阵
3、利用该转化矩阵来构造有向图(Directed Graph),通过计算从节点 start 到节点 conversion 的所有非重复路径(Simple Path)的累乘权重系数之和来计算移除效应系数
4、通过移除效应系数,计算各个状态的转化贡献值
什么是移除效应?
渠道的移除效应定义为:移除该状态之后,在 start 状态开始到 conversion 状态之间所有路径上概率之和的变化值。通过计算各个渠道的移除效应系数,根据移除效应系数在总的系数之和之中的比例得到渠道贡献值。移除效应实际上反映的是移除该渠道之后系统整体转化率的下降程度。
我们可以把上面的案例简化一下,尝试具体计算下移除效应和各渠道的转化贡献值:
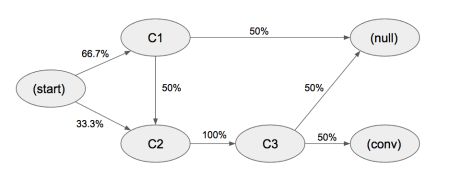
假设简化后的状态集是 {C1,C2,C3}, 各路径上代表状态间转化的概率
在以上系统中,总体的转化率 = (0.667*0.5*1*0.5+0.333*1*0.5)= 33.3%
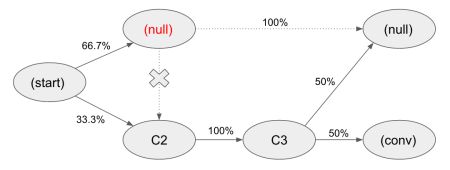
当我们尝试移除节点 C1
移除节点 C1 后,整体转化率 = 0.333*0.1*0.5 = 16.7%,所以 C1 节点的移除效应系数 = 1-0.167/0.333=0.5
同理可计算节点 C2 和 C3 的移除效应分别是 1 和 1
通过移除效应系数计算得到转化贡献值:
C1 : 0.5 / (0.5+1+1) = 0.2
C2 : 1 / (0.5+1+1) = 0.4
C3 : 1 / (0.5+1+1) = 0.4
如果你对马尔科夫链有疑惑,可以点击这里了解下
三、如何选择归因模型
从上面这么多种归因模型来看,我们大概可以把他们分成 2 类:
(1)基于规则的:预先为渠道设置了固定的权重值,他的好处是计算简单、数据容易合并、渠道之间互不影响,当然你也可以根据实际需要去调整他们的权重配比
(2)基于算法的:每个渠道的权重值不一样,会根据算法和时间,不同渠道的权重值会发生变化(数据驱动)
在选择用何种归因模型之前,我们应该先想清楚业务模式!
如果是新品牌、新产品推广,企业应该给予能给我们带来更多新用户的渠道足够的权重,那么我们应该选择首次互动模型;
如果是投放了单一的竞价渠道,那么我们应该选取末次互动归因模型或者渠道互动归因模型;
如果公司很在乎线索来源和促成销售渠道,那么我们应该选择 U 型归因模型;
如果公司的渠道多、数据量大,并且由永久用户标识,基于算法的归因模型能够为营销分析提供巨大的帮助;
....
总的来说,没有完美的归因模型。任何模型都存在他的局限性和不足,如何有效地结合客观数据与主观推测,是用好归因模型的重要能力前提。
四、还有哪些有趣的归因模型?
这里抛出一个有趣的问题,大家可以通过思考他背后的分析逻辑,尝试一下如何应用到归因模型中
小陈和小卢同学准备吃午餐,小陈带了 3 块蛋糕,小卢带了 5 块蛋糕。这时,有一个路人路过,路人饿了,于是他们约路人一起吃午饭,路人接受了邀约。小陈、小卢和路人 3 个人把 8 块蛋糕全部吃完了,吃完饭后,路人感谢他们的午餐,于是给了他们 8 个金币,然后离去。
小陈和小卢为这 8 个金币的分配展开了争执。
小卢说:我带了 5 块蛋糕,理应我得 5 个金币,你得 3 个金币。
小陈不同意:既然我们一起吃这 8 块蛋糕,理应平分这 8 个金币。
为此他们找到了公正的夏普里。
夏普里说:公正的分发是,小陈你应当得到 1 个金币,你的好朋友小卢应该得到 7 个金币。经过夏普里的解释,小陈和小卢认为很有道理,愉快地接受了这种分金币的方案。
请问,夏普里是怎样分析得到 1:7 这样的分配的呢?
全文完
一、什么是归因分析?二、几种常见的归因模型1、末次互动模型2、末次非直接点击互动模型3、末次渠道互动模型4、首次互动模型5、线性归因模型6、时间衰减归因模型7、基于位置的归因模型(U 型归因)归因分析模型的计算原理演绎8、马尔科夫链三、如何选择归因模型四、还有哪些有趣的归因模型?
品牌归因分析现场纪实(抹除关键数据与结论)
项目目的与步骤介绍
写这篇纪实文章是为了整理思路,完善拼图,并能给后来者介绍一个数据工程师是如何开展一个完整的项目的方法,起到借鉴意义。也为了让团队成员了解到我的项目进度和遇到的项目瓶颈,方便更好的协作完成项目。
本项目的目的是通过对品牌的渠道数据的收集整理,并利用多种方法对渠道进行归因分析,最终提出一些渠道上的投入增减建议,改善渠道营销效果。完成本项目步骤梳理如下,然后我会按照顺序一一来介绍每一步的关键资料和方法。
一、资料收集整理(渠道营销的各种归因方法、马尔科夫数学理论)
拿到项目,大致确认步骤后,我就开始上网查资料,学习归因分析和马尔科夫的知识,搜集到比较重要的资料有以下一些:
归因分析:
1、8 个营销归因模型,为什么很多人会选最简单的那个?
2、互联网广告的归因分析 (Attribution Analysis)
3、高阶媒体归因:沙普利值 vs 马尔科夫链 - 极诣数字营销 - 互联网数字营销专家 - 全方位顾问咨询服务
马尔科夫理论介绍:
1、[图文] 马尔可夫链分析法 - 百度文库
2、小白都能看懂的马尔可夫链详解
马尔科夫归因分析 R 语言实现:
1、Marketing Channel Attribution with Markov Models in R
2、https://adavide1982.shinyapps.io/ChannelAttribution/
3、给初学者的营销渠道归因建模指南(马尔可夫链 + R 语言)
一些具体搭建归因模型的 细节:
1、上山抓松鼠:归因分析
2、多渠道归因建模:好,坏和丑陋的模型
3、多渠道归因:定义,模型和现实检查
4、功能应用示例
延伸阅读:
1、用 Python 入门不明觉厉的马尔可夫链蒙特卡罗(附案例代码)
除了归因模型分析,更好的测量渠道价值的方式:
1、受控实验
2、网络运营中十个经典的数据分析方法
二、从数据库中整理数据(类似 mysql)
由于数据库下载速度慢的瓶颈,问 leader 要来原始数据分析,进行最原始数据的清洁和整理工作
三、给整理好的人群做聚类分析,按人群进行分类
聚类关键代码
#-*- coding: utf-8 -*- #K-Means聚类算法 import pandas as pd from sklearn.cluster import KMeans #导入K均值聚类算法 inputfile = '../tmp/zscoreddata.xls' #待聚类的数据文件 k = 5 #需要进行的聚类类别数 #读取数据并进行聚类分析 data = pd.read_excel(inputfile) #读取数据 #调用k-means算法,进行聚类分析 kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好 kmodel.fit(data) #训练模型 kmodel.cluster_centers_ #查看聚类中心 kmodel.labels_ #查看各样本对应的类别
四、数据清洁与整理
已经完善√(python 语言实现)
五、最终归因分析和可视化代码
现成小工具:https://adavide1982.shinyapps.io/ChannelAttribution/
R 语言代码实现:Marketing Channel Attribution with Markov Models in R
有时间实践一下,R 与 Rstudio 已经安装好。
以下是实践代码,已经成功实现以上小工具的功能
# Install these libraries (only do this once)
install.packages("ChannelAttribution")
install.packages("reshape")
install.packages("ggplot2")
# Load these libraries (every time you start RStudio)
library(ChannelAttribution)
library(reshape)
library(ggplot2)
getwd()
setwd("F:/anaconda3/XX/XX/XX")#文件存储地址
getwd()
Data=read.csv("Rdata_end.csv",header=T)
H <- heuristic_models(Data, 'path', 'total_conversions', var_value='total_conversions_value')
M <- markov_model(Data, 'path', 'total_conversions', var_value='total_conversions_value', order = 1)
# You can specify the Markov order by adding the "order" argument. By default, it will run as Order 1.
# NOTE: The same steps apply from building the heuristics models in order to pass in your own data for building the markov_model.
# Merges the two data frames on the "channel_name" column.
R <- merge(H, M, by='channel_name')
# Selects only relevant columns
R1 <- R[, (colnames(R)%in%c('channel_name', 'first_touch_conversions', 'last_touch_conversions', 'linear_touch_conversions', 'total_conversion'))]
# Renames the columns
colnames(R1) <- c('channel_name', 'first_touch', 'last_touch', 'linear_touch', 'markov_model')
# Transforms the dataset into a data frame that ggplot2 can use to graph the outcomes
R1 <- melt(R1, id='channel_name')
# Plot the total conversions
ggplot(R1, aes(channel_name, value, fill = variable)) +
geom_bar(stat='identity', position='dodge') +
ggtitle('TOTAL CONVERSIONS') +
theme(axis.title.x = element_text(vjust = -2)) +
theme(axis.title.y = element_text(vjust = +2)) +
theme(title = element_text(size = 16)) +
theme(plot.title=element_text(size = 20)) +
ylab("")
# NOTE: The "+" allows you to split the code over multiple lines without running each line individually.
R2 <- R[, (colnames(R)%in%c('channel_name', 'first_touch_value', 'last_touch_value', 'linear_touch_value', 'total_conversion_value'))]
colnames(R2) <- c('channel_name', 'first_touch', 'last_touch', 'linear_touch', 'markov_model')
R2 <- melt(R2, id='channel_name')
ggplot(R2, aes(channel_name, value, fill = variable)) +
geom_bar(stat='identity', position='dodge') +
ggtitle('TOTAL VALUE') +
theme(axis.title.x = element_text(vjust = -2)) +
theme(axis.title.y = element_text(vjust = +2)) +
theme(title = element_text(size = 16)) +
theme(plot.title=element_text(size = 20)) +
ylab
write.csv(R,file="R.csv",row.names=F,quote=F)
data.csv=read.csv("R.csv") #保存文本文件
dim(data.csv)
做好归因分析:需要考虑的几个问题
1、分析购买前多久的行为合适?(选择回顾窗口)
2、两个渠道切换中间间隔的时间多长以上就可以考虑前一个点击对后一个点击无影响了?
3、时间多接近的渠道点击可以归类为一次点击?
3、用哪些特征做聚类合适?
4、根据最后交互 / 最终点击归因模型的分析方法,我们可以继续分析倒数第二、第三等的渠道重要度分析,这样的方法可以让我们看到更宏大的归因局面。
全文完
项目目的与步骤介绍一、资料收集整理(渠道营销的各种归因方法、马尔科夫数学理论)二、从数据库中整理数据(类似 mysql)三、给整理好的人群做聚类分析,按人群进行分类四、数据清洁与整理五、最终归因分析和可视化代码
多渠道归因 – union本文结构 1、简介 2、转化贡献计算 3、马尔可夫链 4、移除效应 5、渠道效率分析 6、投放优化 7、Bid…
本文结构
1、简介
2、转化贡献计算
3、马尔可夫链
4、移除效应
5、渠道效率分析
6、投放优化
7、Bidding 优化
8、访问行为分析
9、改进方向
10、代码示例
在每一个行业中,效果评估都是决策过程中一个重要的部分。输入产出比是一个显而易见的度量,但是由于只是单个指标,有可能导致次优化的决策。同时在在线广告领域,难以衡量整体的表现,单一指标难以考虑到各个在线广告活动的联合效果,因此为了理解线上营销活动的影响,一个多渠道的归因模型是必须要考虑的 [3]。
由于广告的定(出)价是基于点击或者展示次数的,因此理解每次 action 的价值是非常重要的。由于各个投放的渠道的性质不同,需要了解各个渠道的营销效果。由于一般情况下,用户发起的在搜索引擎上的交互带来的结果要优于其它渠道的结果,而由于各种原因,用户一般不太愿意点击各种横幅广告,虽然这些用户有可能会认同广告实际传播的信息,因此准确评估横幅广告的效果也是非常重要的。
按照 Google Analytics 对于归因分析模型的说法:an Attribution Model is a rule, or set of rules, that determines how credit for sales and conversions is assigned to touchpoints in conversion paths
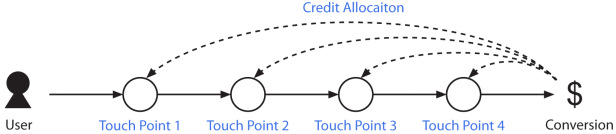
即归因分析模型是 “将最终销售转化结果分配功劳或者贡献到用户转化路径各个触点(Touch Point)上的一系列规则”,也就是分配贡献值给各个触点。转化指的是用户支付订单或者其它行为,触点可以指访问渠道来源:例如百度,搜狐,优酷,Bing,也可以指在线推广类型,例如横幅广告,邮件,文字链接,搜索关键词,视频广告等等。从广告主的角度出发,触点可以指一次活动中一个或多个广告代理商投放的多个渠道。
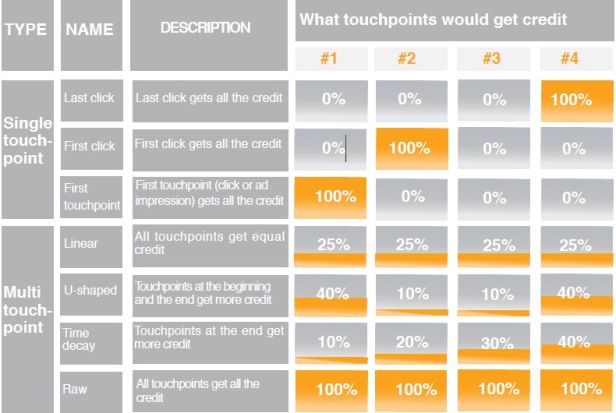
常见的归因分析模型包括:
- 最后一次点击:用户购买之前最后一个触点获取所有贡献值
- 第一次点击:用户访问路径上的第一个触点获取所有贡献值
- 线性模型:用户访问路径上的所有触点平分贡献值
- 时间衰减模型:用户访问路径上更早的触点获取更多的贡献值
归因分析最重要的应用就是计算各个推广渠道的转化贡献,在此基础之上计算推广渠道的输入产出比,并进一步进行预算的分配。假设有如下数据,start 表示开始,null 表示未转化(一般指未购买),conversion 表示转化成功:
user1 访问路径:start->bing->baidu.com->conversion
user2 访问路径:start->sougou.com->null
user3 访问路径:start->bing->ipinyou.com->conversion
user4 访问路径:start->baidu.com->so.com->conversion
根据最后一次点击模型和以上示例数据计算可得到:
- baidu.com 0.33
- ipinyou.com 0.33
- so.com 0.33
在不同的渠道和营销活动间重新分配预算时,一个正确的归因模型非常重要 [14]。归因模型的选择很大程度上决定了转化率计算结果,最近调查表明,54% 的广告主表明在使用最后一次点击归因模型,而 42% 的广告投放人员不确定如何选择合适的归因方法和模型 [9]。
[30] 中提出了一个好的归因模型应当有以下特点:
- 公平
- 按照渠道对于转化影响力得能力进行奖励
- 数据驱动
- 利用每个营销活动得触点和转化数据来建立模型
- 可解释性
- 能够被各相关方接纳
最后一次点击是最广泛采用的归因分析模型 [22],最后一次点击归因建立在用户是否购买产品和用户查看点击该产品广告次数无关的假设之上,此假设在很多情况下并不准确[10],已经证明在很多情况最后一次点击模型并不准确[2][8]。[24] 中的数据表明,在 30 天内,40% 的转化事件发生之前存在超过一次的点击行为:
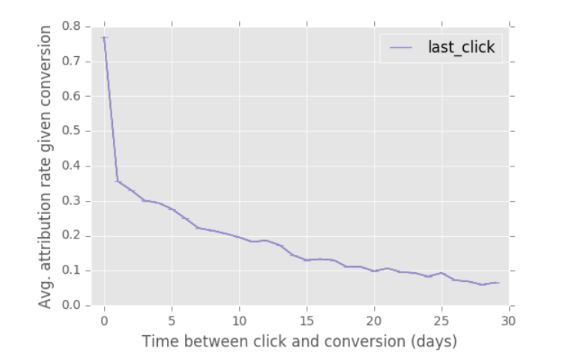
最后一次点击模型会鼓励 DSP 将预算着重分配在一些客户历程中处于最后阶段的一些触点,例如重定向或者叫二次营销用户 [21],这些用户实际上已经表明了对产品的兴趣,同时该模型低估 Email、Display 广告,高估搜索引擎的贡献值。而且推广渠道因为属性和目的的不同,并不能脱离用户整个的转化路径来单独进行计算 [3]。
第一次触点模型驱使 DSP 尽可能地进行目标客户是新客户的营销活动,例如品牌营销活动 [21]。线性归因模型可能用在以下场景:广告商的目的是维持用户访问路径的各个触点的关注度。此外对于最后一次点击、第一次点击和线性模型而言,实际上都是需要人工确定分配规则的算法, 因此需要一种以数据驱动的(Data-Driven)、更准确的归因算法。
如果将各推广渠道视为系统状态,推广渠道之间的转化视为系统状态之间的转化,可以用马尔科夫链表示用户转化路径 [4]。[4] 中提出的马尔科夫图归因模型反映了用户点击路径和访问历程的序列特征,同时也为分析渠道之间的相互影响作用提供了一种可行方法,[4]中的作者验证了,在四种类型的点击数据上(travel,two fashion retail,luggage retail),高阶马尔科夫模型相比启发式(第一次点击和最后一次点击)和简单的逻辑回归而言,在转化事件的预测上有提高,同时能够达到复杂逻辑回归相同的水平,同时在同一数据集交叉检验得到的移除效应的方差处于将校范围内,[4]中作者因此认为用(高阶)马尔可夫链来分析用户转化历程是合适的。这种方法能够利用到单个用户的轨迹数据,同时没有对渠道性质或客户决策过程作任何假设,因此通用性比较高[32]。
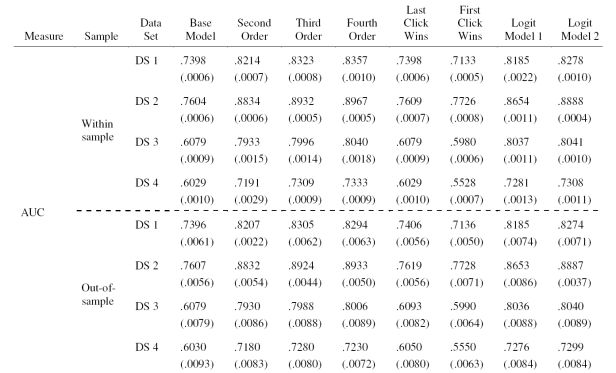

马尔可夫链表示系统在 t+1 时间的状态只与系统在 t 时间的状态有关系,与系统在 t-1,t-2,…,t0 时间的状态无关,平稳马尔可夫链的转化矩阵可以用最大似然估计,也就是统计各状态之间的转化概率计算得到。用马尔科夫链图定义渠道推广归因模型:
1、状态集合,定义为 banner,text,keyword,link,video,mobile,unknown 7 种推广类型加上 start,null,conversion 3 种系统状态
2、稳定状态下的转化矩阵,通过某公司 web 网站 20 天的原始 click 数据,同时包括转化和未转化的用户点击路径,计算 (利用 Spark+Python,详见代码示例) 得到如下状态(按照投放广告类型划分)转化矩阵
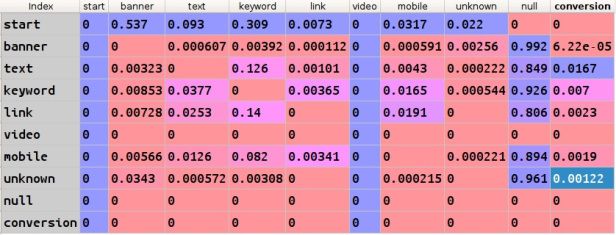
渠道的移除效应定义为:移除该状态之后,在 start 状态开始到 conversion 状态之间所有路径上概率之和的变化值。通过计算各个渠道的移除效应系数,根据移除效应系数在总的系数之和之中的比例得到渠道贡献值。移除效应实际上反映的是移除该渠道之后系统整体转化率的下降程度 [4][16]。
通过以下示例可以了解移除效应的计算过程 [5]
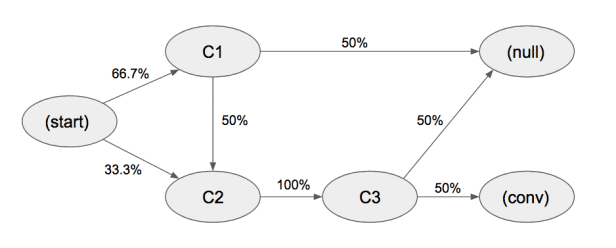
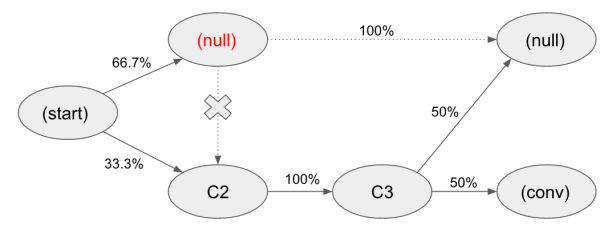
在以上系统中,总体转化率是 33.3% (0.667 * 0.5 * 1 * 0.5 + 0.333 * 1 * 0.5.) ,移除节点 C1 后整体转化率是 16.7% (0.333 * 1 * 0.5.) ,节点 C1 的移除效应系数是 0.5 ( (0.333 – 0.167) / 0.333) ),同理计算节点 C2 和 C3 的移除效应系数是 1,通过移除效应系数计算得到转化贡献值:
- C1:0.5 / (0.5 + 1 + 1) = 0.2 * 1 conversion = 0.2
- C2:1 / (0.5 + 1 + 1) = 0.4 * 1 conversion = 0.4
- C3:1 / (0.5 + 1 + 1) = 0.4 * 1 conversion = 0.4
在计算如图 2 所示的转化矩阵中各渠道的移除效果时,利用该矩阵构造有向图(Directed Graph),每次移除一个节点 node(i) 之后,通过计算从节点 start 到节点 conversion 的所有非重复路径(Simple Path[17][18])的累乘权重系数之和来计算节点 node(i) 移除效应系数 [6],重复此步骤,计算出所有非 start 和非 conversion 节点的移除效应系数,在计算出所有节点的移除效应系数之后,通过归一化计算每个渠道的转化贡献值。
按照最后一次点击模型、线性模型和一阶马尔科夫链模型计算得到的 web 端各渠道推广贡献值如下图所示:

其中马尔可夫链归因模型相比最后一次点击模型而言,在百度的转化率归因上要小,而在 so.com 和 sogou.com 的转化率归因上,马尔可夫链归隐模型的计算结果要比最后一次点击模型要大,在实际数据中也反映了这种情况:一部分的转化订单最后一次点击来源百度,但是之前的点击来自其它垂直类或者 DSP 渠道。
在转化率计算的过程中,需要注意的几点包括:
- 丢弃掉那些来源不明的渠道,例如渠道为 Unknown 的,无法将贡献分配到这些渠道上
- 丢弃那些来自书签或者内部渠道的访问记录,这种情况下数据采集到的日志显示该渠道为 Direct 或者 Internal[27]
- 将第一次购买和第二次及以上的购买行为的转化路径分别进行分析,很明显这两部分的购买行为有很大不同
- 当利用一阶马尔可夫链进行计算时,一个访问路径中相邻的两个渠道可以缩减为一个,也就是可以在路径中去掉重复渠道。例如路径为 C1 → C2 → C2 → C2 → C3,可以精简为 C1 → C2 → C3[27]。因为不管在 C2 中重复多少次,都会最终落到 C3 渠道上。去掉重复路径的结果是将会得到稍微不同的转化矩阵,但是通过移除效应计算得到贡献值仍然相同。
- 将那些没有成单(未成功转化)的路径也考虑进来。这样的话模型将正面渠道和负面渠道两方面的信息都包含在内,对业务有一个更加全面的了解。
在分配每个营销渠道的贡献之后,可以计算每个渠道的转化效率。例如总的转化单数是 10000,通过将总转化单数乘以渠道的转化贡献,计算出每个渠道的贡献单数(conversions)之后,再通过将每个渠道投入的预算除以 conversions,能够得到每个渠道的效果付费成本 Cost Per Action(CPA),通过 CPA 来比较每个渠道的效率。

在计算出每个渠道的 CPA 之后,在控制其它渠道投入预算不变的情况下,可以计算特定渠道的投入与产出(也就是转化成单数)之间的关系,一般情况下,转化成单数越高时,获得同等产出的边际成本越大,只不过每个渠道的系数不一样。
[14] 中提出在最后一次点击归因模型和多渠道归因模型的基础上,利用两种模型分别计算每次投放活动在该渠道的转化率,渠道的输入产出比通过计算每次投放活动带来的的总收益与该渠道转化率的乘积之和除以在该渠道投放的总金额进行计算,在计算 R(i) 也就是输入产出比之后,确定每个渠道投放金额上限(在已有的投放金额上适当增加),使用如下图所示的线性规划模型进行广告预算的分配。
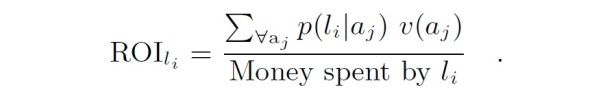

其中,Sj 代表各个渠道的预算上限,Bi 代表要进行优化的每个渠道的预算,Ri 为每个渠道通过转化率计算出来的输入产出比,B 为预算总和。在 [14] 论文作者进行的 12 天在线实验中,相等规格预算,四种相同的投放渠道,但是利用到的是不同的预算分配方法,通过多渠道归因分析为基础的预算分配策略,在 eCPA、eCPC 和 ROI 上优于最后一次点击归因模型为基础的分配策略。

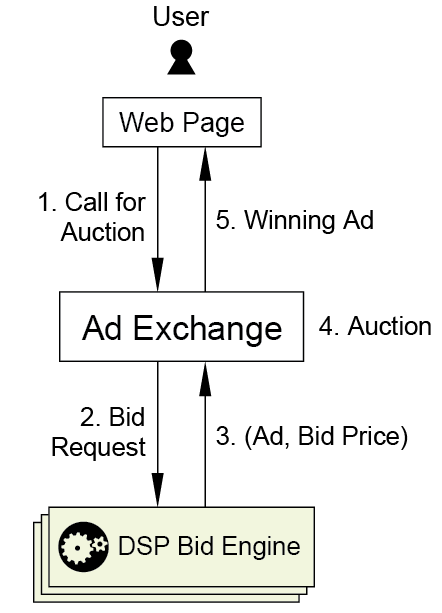
在效果广告中,点击率预测和转化率预测是两大核心问题 [25]。DSP 帮助广告主管理营销活动并优化广告出价行为。大部分的广告主关心的是营销活动如何促使用户采取广告主期望的行为,例如注册服务或者进行购买,所以一般采用的出价模型是 Cost Per Click(CPC)或者 Cost Per Action(CPA)。在实时竞价广告中,用户访问一个网页的同时通常会进行广告曝光,供给方将竞价的请求通过 Ad Exchange 发送给各个 DSP,DSP 将会负责出价的计算,最终所有 DSP 中的第二高出价会被作为最终的广告出价成本。
如果以 CPA 的模式进行结算,在每次竞价广告中出价的预期值(Expected Value Bidder)等于广告主的出价乘以估算的转化率。为了提高出价策略的效率,一个研究方向是预测转化率。
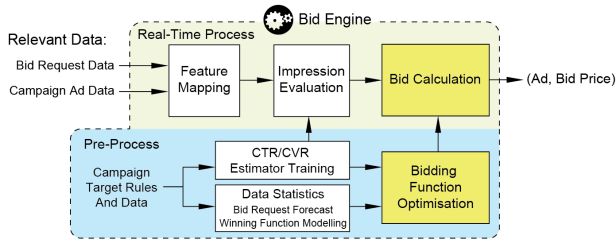
如果用 θ 表示广告的转化率,r 表示转化产生的价值,那么现有的出价则基于 [21]
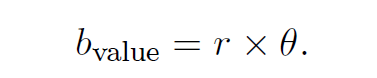
DSP 通常利用上下文(包括域名,网页内容,关键词,时间日期,地理位置,天气,语言,操作系统,浏览器)和用户的行为数据(包括搜索,浏览,购买历史,职业,收入,情绪?等)数据来计算点击率和出价。如果一个用户在第一次广告展示之后进行了点击,在接下来的竞拍中,一个理性的竞价策略应当考虑到之前广告对转化的贡献,从而降低第二次广告出价,因为转化贡献值很难再有大的提升。而现有的基于价值的出价策略由于没有追踪用户的点击行为,同时也没有预测广告点击行为对转化的贡献演化过程 [25]。
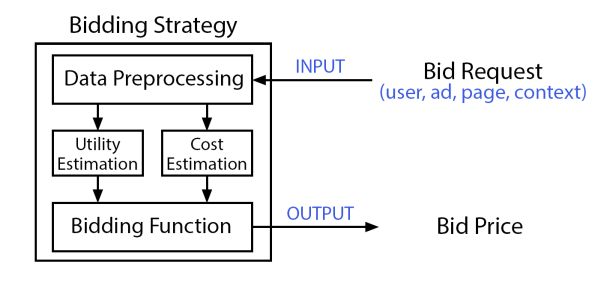
[34] 中认为最后一次触点归因模型能够在一定程度上提升 CPA 的效率,但是也提出了—————————。[23] 中提出了一种基于 lift-based 的出价策略。转化率的 lift 指的是用户在观看广告之后转化率的提升程度为Δθ,r 表示转化产生的价值,则相应的出价为:
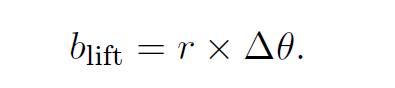
由于转化率等于该触点在整个流程中的贡献比例
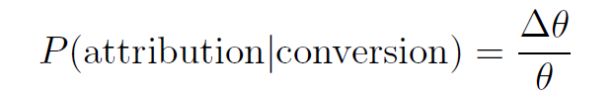
所以实际上转化率的 lift 出价对应的是在多渠道(触点)归因模型下分配给该触点的价值
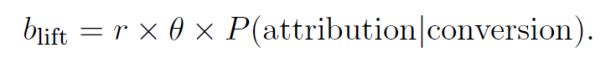
而如果实际应用中采用最后一次点击归因模型的话,对于最后一个触点而言,P(attribution | conversion) = 1,实际上又回到了 Value-based 出价模型,可以说 Value-based 是 Lift-based 的一种特殊形式。
Value-based 出价策略将预算集中在高转化率用户上,但是这些用户已经很可能将要完成转化,进一步的提高出价并不能提升转化率。Lift-based 出价策略将预算根据转化率分配在各个触点上,能够更多地影响可能进行转化的用户,[23] 的作者证明了 Lift-based 出价策略能够比 Value-based 出价策略带来为广告主更多的转化,而采用 Lift-based 的一个关键之处是采用合理的多渠道归因模型,当采用最后一次点击归因模型时,将会导致 DSP 产生高 CPA[23]。
[25]中进一步提出了一种基于指数衰减的归因模型并嵌入到 bidding 过程中来进行竞价优化,其中δ是最后一次点击到完成转化的时间间隔,X 为上下文环境,S 为是否完成转化,指数衰减因子为λ,λ反映的是用户在点击之后完成转化的概率随着时间下降的速度,利用最大对数似然率来估计该值,在实际中 [25] 的作者提出利用 L-BFGS 优化方法计算对应的损失函数最小值来估计λ的值[33]。
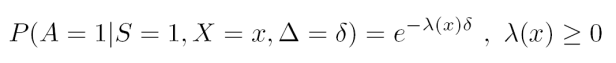

上式中实际上将转化贡献抽象为点击和转化行为之间的时间间隔的函数。当发生第二次点击时,第二次点击的边际转化贡献为:

也就是说 DSP 根据点击的边际转化贡献来进行出价(是从数据中学习到归因模型的参数并将其结合到竞价过程中(Attribution-aware Bidder)):
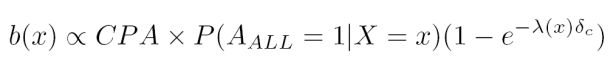
上式中的第一项代表的是点击之后的转化率,如果没有前一次点击,δc 为 0,上式中的第二项变为 1,出价则与 Value-based 模式一致。而在发生一次点击行为之后,第二次点击的出价随着时间的增长大幅下降。在实际计算中,在每个用户的每一次转化中,上式中的第二项都需要单独进行计算。
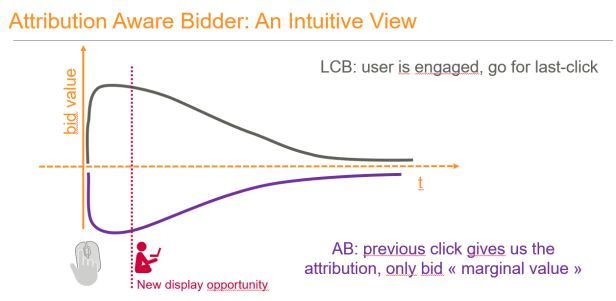
离线评估
如下图所示,基于最后一次点击归因模型的出价在一次点击之后的出价会大幅增长,基于第一次点击归因模型的出价则在点击之后出价会下降,基于指数下降的归因模型则在点击之后迅速将出价降到最低,然后在接下来的时间内平稳地提升出价。

从用户的角度出发,采用基于转化提升的竞价模型,能够使得用户避免接收同一广告主的广告,能够为 DSP 平台的展示提供广告多样性。对于广告主而言,对于一个给定的预算,[25] 的作者在离线验证中观测到基于时间衰减归因的竞价算法在投放了更少的广告的同时(Win Rate 下降),评价指标得到提升。

计算各渠道的贡献价值、分析渠道之间的相互影响是归因分析的两个最重要目标 [4]。如图 2 所示,53.7% 的用户在第一次访问中是通过横幅广告链接访问 web 网站,说明横幅广告推广类型在引起用户注意、开启用户转化漏斗方面的重要性。12.6% 的用户在通过文字链接访问 web 网站后,会通过搜索引擎关键词访问 web 网站。14% 的用户在通过搜索首位结果访问 web 网站后,在下一次访问中通过搜索引擎关键词访问 web 网站。
如图 5 所示,在来源渠道为关键词搜索的贡献值上,一阶马尔可夫链模型下的贡献值最小,因为一部分用户第一次访问先通过文字链接或搜索左侧首位进行访问网站,最后再通过搜索关键词跳转到网站直接购买。而在无线投放渠道来源上,一阶马尔科夫链模型下的贡献值最大,反映的是用户通过移动广告知晓产品,最后通过 web 渠道访问网站并进行购买(准确地说是通过移动端访问 web 网页,这种行为有点奇怪,待进一步考证),因此在马尔可夫链模型下的贡献值相比最后一次点击模型下的贡献值要大。
数据源
现有的数据源包括通过埋点采集的用户访问行为数据,这一部分数据中不包括例如用户未点击的横幅广告展示记录数据,造成的影响是将会低估横幅广告的贡献值。因此改进方向之一是需要将的未产生点击行为的广告展示记录纳入数据源。而且保险类电商成单用户的转化路径都比较短,相比于常规方法而言,基于一阶马尔科夫链的归因模型不会展示出太大的差异。
访客识别
存在这样一种情况,访客在渠道 A 进行了第一次点击,当他第二次点击之前清除了 Cookie 或者跨设备进行访问,这种情况下两次访问的访客 ID 不一致,如果不能识别两条记录是同一访客,造成的影响是分析此用户的转化行为时,会丢失第一次访问的贡献,同时第二次访问(假设完成转化)的贡献被放大。因此准确识别跨设备的用户或者关联清除了 Cookie 之后的用户的不同访问记录显得非常重要。
高阶马尔可夫链
高阶马尔可夫链表示系统在 t+1 时刻的状态不但依赖于 t 时刻也依赖与 t-1,t-2… 时刻的状态。有研究表明 [7] 用户访问行为并不能严格地用一阶马尔科夫链表示,同时高阶马尔可夫链在转化率预测上能够提供更高的准确度[4],也能够在分析渠道之间的相互影响作用提供基础。在高阶马尔可夫链的计算过程中,不能删除一个访问路径上两个相邻重复的渠道。
https://github.com/zhouyonglong/MarketingAnalytics/blob/master/multichannel_advertising_attribution.py
https://github.com/zhouyonglong/MarketingAnalytics/blob/master/exponential_decay_attribution_based_bidding.py
[1]Marketing attribution comes of age Real-life insights from advertisers
[2]Measuring ROI Beyond the Last Advertisement
[3]Analyses of Online Advertising Performance Using Attribution Modeling
[4]Mapping the Customer Journey: A Graph-Based Framework for Online Attribution Modeling
[5]http://analyzecore.com/2016/08/03/attribution-model-r-part-1/
[6http://networkx.readthedocs.io/en/latest/reference/generated/networkx.algorithms.simple_paths.all_simple_paths.html
[7https://www.researchgate.net/publication/241624113_Are_web_users_really_Markovian
[8]Attributing Conversions in a Multichannel Online Marketing Environment An Empirical Model and a Field Experiment
[9]Marketing Attribution: Valuing the Customer Journey
[10]The Multiple Attribution Problem in Pay-Per-Conversion Advertising
[11]http://www.lunametrics.com/blog/2015/12/03/the-value-of-google-analytics-data-driven-attribution/
[12]https://ranjanicnarayan.com/2017/04/22/understanding-marketing-attribution-algorithms-why-the-pain-may-not-be-worth-the-gain-in-the-long-run/
[13]A Nested Hidden Markov Model for Internet Browsing Behavior
[14]Multi-Touch Attribution Based Budget Allocation in Online Advertising
[15]Budget Optimization for Online Advertising Campaigns with Carryover Effects
[16]Mining Advertiser-specific User Behavior Using Adfactors
[17]https://en.wikipedia.org/wiki/Path_(graph_theory)
[18]Algorithms in C, Part 5: Graph Algorithms
[19]Media Exposure through the Funnel A Model of Multi-Stage Attribution
[20]Analyses of Online Advertising Performance Using Attribution Modeling
[21]Display Advertising with Real-Time Bidding and Behavioural Targeting
[22]Causally motivated attribution for online advertising
[23]Lift-Based Bidding in Ad Selection
[24]https://drive.google.com/file/d/0BwF-hgLDpCD6Z0VUSGJFQ2UtNDA/view
[25]Attribution Modeling Increases Efficiency of Bidding in Display Advertising
[26]http://research.criteo.com/criteo-attribution-modeling-bidding-dataset/
[27]http://www.yittoo.com/blog/index.php/2016/05/13/large-scale-ml-ctr-prediction/
[28]http://analyzecore.com/2017/05/31/marketing-multi-channel-attribution-model-r-part-2-practical-issues/
[29]Real-Time Bidding A new frontier of computational advertising research
[30]Real-Time Bidding based Display Advertising Mechanisms and Algorithms
[31]Optimal Real-Time Bidding for Display Advertising
[32]Putting Attribution to Work – A Graph-Based Framework for Attribution Modeling in Managerial Practice
[33]https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb
[34]Beyond the Last Touch : Attribution in Online Advertising
全文完
本文结构1、简介2、转化贡献计算3、马尔可夫链4、移除效应5、渠道效率分析6、投放优化7、Bidding 优化8、访问行为分析9、改进方向10、代码示例离线评估数据源访客识别高阶马尔可夫链
数据驱动归因的几个算法 | GA 小站数据驱动归因,英文是 Data-Driven Attribution,简称 DDA,或数据驱动归因模型,英文是 Data-Driven Attribution Models,简称 DDAM,也叫算法归因。
数据驱动归因,英文是 Data-Driven Attribution,简称 DDA,或数据驱动归因模型,英文是 Data-Driven Attribution Models,简称 DDAM,也叫算法归因。
自 Google 宣布即将推出归因模型以来,广告主对新的数据驱动模型表现出很大兴趣。
Google 于 2013 年推出了 Google Analytics Premium 的数据驱动归因模型,并于 2014 年在 AdWords 中发布了该模型。
数据驱动归因是一种基于机器学习的归因模型,与基于规则的归因模型不同,数据驱动归因使用所有可用的路径数据,包括路径长度,曝光顺序和广告素材,来了解特定营销接触点的存在如何影响用户转化的可能性以更好地将功劳分配给任何接触点。
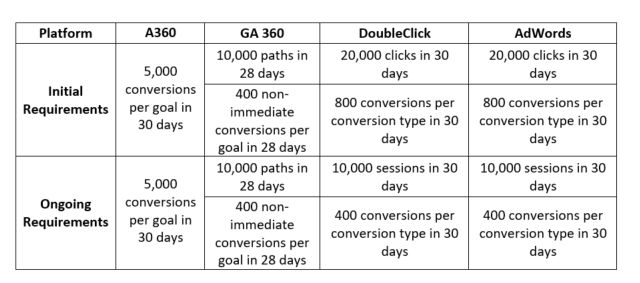
数据驱动归因是基于算法的,要想使用数据驱动归因,数据量需要积累到一定的规模才可以使用,目前数据驱动归因可在 Google 营销体系中的多个平台上使用:Google Attribution 360,Google Analytics 360,DoubleClick 和 AdWords,不同平台对数据量的要求是不一样的,如下:
常用的算法有马尔科夫链、沙普利值、生存分析和 Harsanyi Dividend。前面三个算法在学精算的有涉及到,马尔科夫链是随机过程,沙普利值是计算投资组合,生存分析是寿险精算,但都只记得个名字了♀️
具体的算法原理和实现过程有兴趣自己去谷歌一下吧。
Markov Chain:马尔科夫链
马尔可夫链因俄国数学家 Andrey Andreyevich Markov 得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备 “无记忆” 的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的 “无记忆性” 称作马尔可夫性质。
Shapley Value:沙普利值
Shapley Value 是由经济学诺贝尔奖获得者 Lloyd S. Shapley 开发的,它是一种在团队成员之间公平分配团队产出的方法。对于以数据为依据的归因,要分析的 “团队” 具有营销接触点(例如自然搜索,展示和电子邮件)作为 “团队成员”,而团队的“输出” 就是转化。数据驱动的归因算法计算每个营销接触点的反事实收益,即,将暴露于这些接触点的相似用户的转换概率与路径中未出现接触点之一的概率进行比较。
Survival Analysis:生存分析
生存分析是研究生存现象和响应时间数据及其统计规律的一门学科。是将事件的结果和出现这一结果所经历的时间结合起来分析的一种统计分析方法,目前在多个方面都有应用。
Harsanyi Dividend
Harsanyi Dividend 是沙普利值的延伸。可能只有 Adobe 使用,Adobe 也只是文档放了两个原文链接。
请参阅原文:
- Shapley, Lloyd S. (1953). A value for n-person games. Contributions to the Theory of Games, 2(28) , 307-317.
- Harsanyi, John C. (1963). A simplified bargaining model for the n-person cooperative game. International Economic Review 4(2) , 194-220
业界使用情况
目前国际一线互联网公司,谷歌系的产品用的是基于 Shapley 值,如 Google Attribution 360,Google Analytics 360,DoubleClick 和 AdWords,是要付费产品才可以使用,但是在最近的 Google Analytics 归因工具的测试版里面也可以使用数据驱动归因:

Adobe Analytics 是基于 Harsanyi Dividend,Facebook 也有使用归因算法,但并未公布使用的具体算法是哪个,只是说定期更新算法模型。
国内有些公司使用的是 Markov Chain。
参考内容:
全文完
Markov Chain:马尔科夫链Shapley Value:沙普利值Survival Analysis:生存分析Harsanyi Dividend业界使用情况
python - Python 中的渠道归因(马尔可夫链模型) - 堆栈内存溢出如何在 Python 中进行渠道归因 马尔可夫链模型 就像我们在 R 中有 ChannelAttribution 包一样。
https://www.linkedin.com/pulse/multi-channel-attribution-model-python-sheranga-gamwasam/
这是数据集链接: https : //docs.google.com/spreadsheets/d/11pa-eQDHEX63uSEA4eWiDTOZ7lbO6Vwt-dHkuhuhbSo/edit?usp=sharing
import time
import pandas as pd
import numpy as np
import collections
from itertools import chain
import itertools
from scipy.stats import stats
import statistics
def unique(list1):
unique_list = []
for x in list1:
if x not in unique_list:
unique_list.append(x)
return(unique_list)
def split_fun(path):
return path.split('>')
def calculate_rank(vector):
a={}
rank=0
for num in sorted(vector):
if num not in a:
a[num]=rank
rank=rank+1
return[a[i] for i in vector]
def transition_matrix_func(import_data):
z_import_data=import_data.copy()
z_import_data['path1']='start>'+z_import_data['path']
z_import_data['path2']=z_import_data['path1']+'>convert'
z_import_data['pair']=z_import_data['path2'].apply(split_fun)
zlist=z_import_data['pair'].tolist()
zlist=list(chain.from_iterable(zlist))
zlist=list(map(str.strip, zlist))
T=calculate_rank(zlist)
M = [[0]*len(unique(zlist)) for _ in range(len(unique(zlist)))]
for (i,j) in zip(T,T[1:]):
M[i][j] += 1
x_df=pd.DataFrame(M)
np.fill_diagonal(x_df.values,0)
x_df=pd.DataFrame(x_df.values/x_df.values.sum(axis=1)[:,None])
x_df.columns=sorted(unique(zlist))
x_df['index']=sorted(unique(zlist))
x_df.set_index("index", inplace = True)
x_df.loc['convert',:]=0
return(x_df)
def simulation(trans,n):
sim=['']*n
sim[0]= 'start'
i=1
while i0
'''
unique_channel=unique(final['path'])
#final=(pd.DataFrame(final.groupby(['path'])[['ass_conversion']].mean())).reset_index()
final_df=pd.DataFrame()
for i in range(0,len(unique_channel)):
x=(final['ass_conversion'][final['path']==unique_channel[i]]).values
final_df.loc[i,0]=unique_channel[i]
final_df.loc[i,1]=x.mean()
v=stats.ttest_1samp(x,0)
final_df.loc[i,2]=v[1]/2
if v[1]/2<=alpha/100:
final_df.loc[i,3]=str(100-alpha)+'% statistically confidence'
else:
final_df.loc[i,3]=str(100-alpha)+'% statistically not confidence'
final_df.loc[i,4]=len(x)
final_df.loc[i,5]=statistics.stdev(x)
final_df.loc[i,6]=v[0]
final_df.columns=['channel','ass_conversion','p_value','confidence_status','frequency','standard_deviation','t_statistics']
final_df['ass_conversion']=sum(import_dataset['conversions']) *final_df['ass_conversion'] /sum(final_df['ass_conversion'])
return final_df,final
import_dataset=pd.read_csv('channel attribution example.csv')
data,dataset=markov_chain(import_dataset,no_iteration=10,no_of_simulation=10000,alpha=5)
全文完
高阶媒体归因:沙普利值 vs 马尔科夫链
- 极诣数字营销 - 互联网数字营销专家 - 全方位顾问咨询服务我们在过去的文章中介绍过归因模型,有没有一种相对于其他的简单的归因模型,更加可靠的模型呢?这就是我们今天要讲的沙普利值(Shapley Value)方法和马尔科夫链(Markov Chain)的方法。

归因模型不单可以帮助我们分配媒体之间的贡献功劳,也可以在单一渠道如搜索营销中分配各个推广计划的贡献功劳。我们在过去的文章中介绍过归因模型,也曾经说过因为它们各有各的缺点,没有一种模型是完美的。那么有没有一种相对于其他的简单的归因模型,更加可靠的模型呢?答案是肯定的。这就是我们今天要讲的沙普利值(Shapley Value)方法和马尔科夫链(Markov Chain)的方法。这两种方法并未提供具体的模型而提供了博弈中计算归因的方法。由于笔者也是现学现卖,如有错误请包涵并指正。
沙普利值对媒体进行归因

沙普利值是谷歌的各种产品中普遍使用的方法,它有另一个好听的名字 Data-Driven Attribution(DDA)模型。你可以在付费版的 Google Analytics,Google Attribution,DoubleClick,和 AdWords 中使用。沙普利值的计算相当复杂,特别是当参与归因的渠道增多时将几何级增长。知乎上已经有各路神仙做了解释,推荐先看明白算法。为了行文方便我们只做一个简单的三渠道举例。
假设我们有搜索引擎推广,记为 P;SEO,记为 O;社交媒体,记为 S。我们开始进行媒体投放后一共获得了 8 个点击,并取得了 2 个转化,记为 C。未转化的记为 N。具体的结果如下:
- S>P>O>C
- S>P>C
- O>N
- P>S>N
接下来你可以忘记我们刚才的试验了,现在我们把这个结果看成一个整体,一个黑盒子。这点非常关键,道理我们最后讲。
如果你爱钻牛角尖,请把这三个渠道想象成三个开关。这三个开关控制开灯,我们接下来看当各种开关情况下所亮的灯的个数。
如果我们只投放 P,那么转化为 0,等号左边是打开了哪些开关,顺序无关,等号右边是亮了多少灯,记为 P=0;同样 S=0;O=0。如果我们仅投放 P 和 O,那么转化为 0,记为 PO=0;仅投放 P 和 S,转化为 1,记为 PS=1;仅投放 OS,转化为 0,记为 OS=0。
三者都投放时,记为 POS=2。稍作整理下,我们有下面的输入条件:
- P=O=S=0
- PO=0
- PS=1
- OS=0
- POS=2
由算法我们可以得到下面的结果:
| 加入顺序 \ 转化增益 | P | O | S |
| POS | 0 | 0 | 2 |
| PSO | 0 | 1 | 1 |
| OSP | 2 | 0 | 0 |
| OPS | 0 | 0 | 2 |
| SOP | 2 | 0 | 0 |
| SPO | 1 | 1 | 0 |
| 平均值 | 5/6 | 2/6 | 5/6 |
由此我们可以算出 P、O、S 三者是如何 “瓜分” 这两个转化的功劳的。我们对比实验数据可以粗略看出由于 O 仅参加了一次转化所以分到的功劳最少。P 和 S 一样多,它们都参加了两次转化。
好了我们先把这个例子放一边,说下马尔科夫链。
马尔科夫链对媒体归因

战斗民族的数学家安德雷 · 马尔科夫对决策的贡献普遍应用到了归因上。相对于沙普利值,马尔科夫链更讲究 “先来后到”。仍然是上面这个例子,我们添加起始点 B 后有如下情况:
- B>S>P>O>C
- B>S>P>C
- B>O>N
- B>P>S>N
接下来我们拆成对子:
| 路径 | 个数 |
| B>S | 2 |
| B>O | 1 |
| B>P | 1 |
| S>N | 1 |
| S>P | 2 |
| P>S | 1 |
| P>O | 1 |
| P>C | 1 |
| O>N | 1 |
| O>C | 1 |
根据每个节点到其他节点的概率我们可以画下面这张决策树。

我们可以算出这个决策树中 C 的概率。由于这里有个无限循环 PS,因此我们可以用无限等比数列求和公式,貌似是高中水平,Sum=a/(1-q),此处 a 为 9/8 即 1/4 * 1/3 * 1/2 + 1/4 * 1/3 + 1。q 为 2/3 * 1/3 = 2/9。这样 Sum 就为 81/56。还要加上 BOC 的 1/8 并减去多加的 1,最后得到 4/7 的概率。

要想得到每个渠道的重要性,我们只要衡量失去它们我们的损失即可。

如果 P 不存在,那么 S 也废了。转化只能通过 BOC 进行,转化数降低到了 1/4 * 1/2 = 1/8。如果 P 走不通会降低 1 – (1/8) / (4/7) 即 25/32 的转化。

如果 O 不存在,那将只剩下前面等比数列图的下面两块。a = 13/12,即 1/4 * 1/3 + 1。q 仍旧为 2/9。Sum = 39/28,减去多加的 1 为 11/28。如果 O 走不通会降低 1 – (11/28) / (4/7) 即 5/16 的转化。

如果 S 不存在,那么我们把 S 画作 N,这样一来总的转化数降低到了 1/4 * 1/3 + 1/4 * 1/3 * 1/2 + 1/4 * 1/2 = 1/4。我们可以这样算出,如果 S 走不通了会降低 1 – (1/4) / (4/7) 即 9/16 的转化。
我们综上汇总一下,POS 的功劳比依次为 25/32,5/16,9/16 即,25:10:18。发现了吗?P 和 S 不一样了!
沙普利值和马尔科夫链归因结果对比
首先这两个方法相比基础的模型如 First Touch,Last Touch,Linear 等有着优势,它们考虑到了更多渠道间的互动。正因为如此,这两者并非将每条转化路径归因后求和,而是理清关系后求整体中的每个渠道的影响力。
不管是沙普利还是马尔科夫,积极地参与转化会是提高本身影响力的最佳方法。对于展示媒体这样的 Prospecting 属性的媒体,铺得更开会比投放更密集来得有效。毛评点 GRP = F × A,当 GRP 固定的情况下,提高覆盖率 A,降低播放强度 / 频率 F 将会是您提高功劳的技术途径。
其次,相比沙普利值,马尔科夫链的接触点先后顺序更被突出,而且这种顺序表现在紧邻的两个接触点移动的概率。这里说的紧邻的含义是马尔可夫链就是这样一个任性的过程,它将来的状态分布只取决于现在,跟过去无关。
在这个例子中沙普利值得到的 P:O:S 结果为 25:10:25,而马尔科夫链得到的结果为 25:10:18。S 的贡献更小了。因为 S 虽然能拿到 50% 的起始接触,但是其转化依赖于渠道 P,所以从马尔科夫链的结果来看 P 比 S 更重要。
最后,无论是沙普利值和马尔科夫链哪种方法得到的归因结果都只能代表过去,要应用于未来的预算分配和媒体采购的话,我们还需要进行测试比较变化。从计算成本的角度上讲,沙普利值的计算只要参加的渠道总数不是很多计算还不会太复杂。因此谷歌采用沙普利值也容易理解,而且每天只更新一次。马尔科夫链的计算要复杂很多,现在通常的做法是用超过一百万条随机路径来模拟每一个参加渠道的影响,而不是像我们例子中精确计算,计算成本要大许多。
希望上面的例子可以给你一个直观的认识。篇幅有限,如果有疑问,请通过极诣的公众号留言提问。谢谢阅读。
(鸣谢小伙伴 Michael Zhang,Misaki Zhou 对本文的概念构思进行的指点。)
全文完
沙普利值对媒体进行归因马尔科夫链对媒体归因沙普利值和马尔科夫链归因结果对比