【技术分享】知微探秘:可视化如何解读北京交通状况
本文整理自DTCC2016主题演讲内容,录音整理及文字编辑IT168@田晓旭@老鱼。如需转载,请先联系本公众号获取授权!



演讲嘉宾

陆旻
北京大学博士研究生
现就读于信息科学技术学院,师从可视化与可视分析实验室袁晓如研究员。研究方向为时空数据的可视化与可视分析、人机交互,有多篇关于城市轨迹数据可视分析工作发表于可视化领域顶级期刊与重要会议。
分享内容
大家好,我叫陆旻,来自北京大学可视化与可视分析实验室,今天我跟大家交流的主题是城市移动数据的知微探秘。

因为我本身不是做数据库领域的,所以来参加这个大会我是有些忐忑的,就提前做了一些功课,为大会做了一个简单的可视化。从这个可视化里面我们可以看到,这次大会大家主要讨论的是数据库及背后的技术,有一些比较著名的数据库像Oracle、MongoDB都比较高频率的被提到。那么我讲的主题在哪里呢?就是下面被黑笔圈起来的部分,其实我讲的主题能够找到,还应该感谢一个讲师,那就是来自阿里云数据可视化的架构师,如果不是她的演讲题目里面包含了可视化这三个字,大家可能都找不到可视化这三个字。
可视化是近年来提出的一种对数据进行分析的技术和学科,其实它跟大会的关联很大,因为它是对数据的分析手段。下面,我就从这个角度来和大家一起分享一下我们做的一些工作,
如果你把可视化作为关键词键入到谷歌图像,你可能就会得到类似上图的截图。图中的有一些可视化结果是艺术家设计的,也有一些是计算机自动产生的。从专业的角度来看,这些可视化有好有坏,但是无论好坏都传达了可视化的核心思想,那就是把枯燥的数据变成图像呈现在用户面前,让用户通过图像去进行视觉理解,进而从数据中发现价值。
基于可视化的数据分析叫可视分析,可视分析的核心思想是用户通过视觉感知图像,同时为用户提供一些交互手段来操纵图像背后的模型。借助于这种人机交互式的分析方法和交互技术,帮助人们更为直观和高效地洞悉大数据背后的信息、知识与智慧。

中国计算机协会每年都会对大数据发展趋势做一个预测。从2014年开始,可视化逐渐越入了大数据委员会专家的视野,特别是2016年,可视化推动大数据平民化的论断,被六十几名大数据委员会的专家推选到了第一位。
前段时间有一个新闻,习大大访英之旅,到访帝国理工大学,我们的一个华人教授,郭毅可教授向习大大展示了一个可视化系统,系统里展现了可视化的比特币交易和一带一路的策略。所以也有可能是在这样的背景下,可视化才变得比较热门。
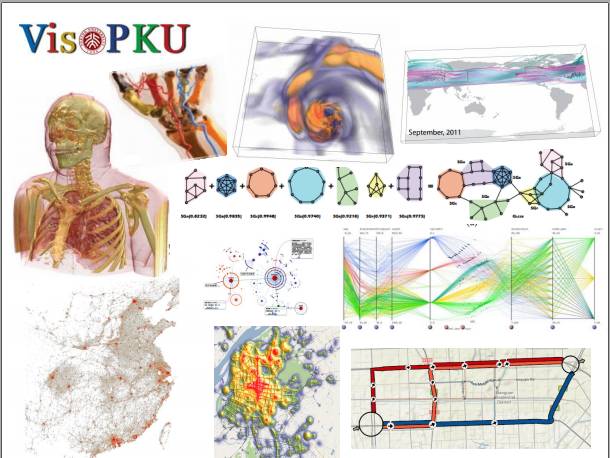
北京大学的可视化与可视分析实验室是袁晓如研究员在2008年回国创建的。当时,可视化还不是很热门,但是现在随着大家对可视化的认识越来越深,我们的工作也逐渐被同行所认可。
我们对一些医学数据进行可视化,将医学的扫描数据通过渲染方式展现出来,这样科学家就可以直观的对背后的医学模型进行观察。
我们还对科学模拟数据进行可视化,图上有飓风和全球湍流的模拟。同时我们也会对基本的可视化方法进行测评,然后提出一些新的方法。
我们也比较关心社交媒体上的应用,我们组有一系列关于微博数据的可视化,这幅图背后其实是没有地图的,我们组的同学是直接通过带有地理标签的微博数据把它打在图片上,自然就形成我们祖国的轮廓。从图中可以看到北上广是微博用户非常密集的地方,而一些内陆的地区也有很多微博的用户。所以数据是可以告诉我们一些背后的信息。

今天我要来分享的是我和我的同伴这几年一直在做的一个数据,就是交通数据。说到交通数据可能会涉及到地理空间的可视化,那么就不可避免的要提一个人。他就是Charies Joseph Minard,法国很有设计天赋的建筑设计师。

这幅图在可视化领域非常有名,是他在十八世纪对拿破仑军队进军俄国的可视化。这幅图不是电脑产生的,而是他通过收集资料手绘设计出来的。
可视化中的两个端点分别是拿破仑军队从欧洲出发的地方和他最终的目的地莫斯科。两种不同的颜色分别描述了拿破仑在进军和撤回时的人数变化,条带宽度表示人数多少。从图中可以很明显的看到他的军队在行进过程中是怎么样一步一步损失的。底下还有关于温度的可视化,可以看到在每一个温度剧烈变化的结点上,军队人数都是锐减的。再看的仔细一些,这个图里还有河流的信息,每经过一个河流,军队人数也是剧烈减少的。
这是十八世纪大家对于数据的一种描述方法,现在我们的移动轨迹也被各种各样的技术记录着。比如说,你在这里发了一条带有地理信息的微博,新浪微博就获得了你的位置;你出门坐了一辆出租车,那辆出租车上有GPS设备,你的轨迹也被记录下来了;你到超市买东西,刷了银行卡,那么可能你在超市的地理位置也被记录了。有这么多先进的移动采集设备帮助我们收集轨迹,我们对城市里的每一个移动物体都能够进行运动行为的描述。

这是我们进行的最直接的可视化,上面的每一个点都表示一辆出租车,颜色表示当前速度,图中有一个颜色的映射表。从图中我们可以看到机场高速的车基本都是绿色,在国贸以及中关村这一带的车大多是红色的。如果我们对数据稍微加整理,就可以得到北京市的一天,我们可以看到早上整个城市是怎么活跃起来的。整个城市就好像是一个生命体,随着时间不断的蓬勃,再渐渐衰弱。

今天我主要介绍我比较擅长的出租车移动轨迹,每个出租车都有一个GPS设备,它会定时采集出租车的运动轨迹,并把运动轨迹收集起来。为什么会选择出租车,因为出租车是城市交通的一个很好的采样,空间分布很广,每个人都有搭乘出租车的需求,而且它不会像私家车那样有既定的路线;时间分布也非常广,因为出租车可能二十四小时都在行驶,所以选用出租车数据来研究城市的交通是比较合理的。
我们使用的数据比较早,是2009年北京市的一个月数据,大概有两万多辆出租车,整个数据集是30GB。从刚才的动画里面我们大概可以看到在某个区域的出租车随着时间的一天的变化情况,但是很难看到细节。所以我们基于出租车数据进行了一些细节的探索。
区域

这是关于我们这次会议的一个例子,我们的会议是在北京国际会议中心召开,那么在出发之前我会考虑这个地方的交通怎么样,应该采取什么样的通行方式。我可以从历史的数据中获得一些关于这个区域交通模式的信息。我去数据库里找一些和这个区域相关的数据,然后写一条空间查询的SQL语句来描述。这样的语言描述可能对非空间数据是比较合理的,但是对于空间数据来说,也许只需要这样一个圆环就可以设定好我们想要的条件。基于这样的思想我们开发了一个出租车轨迹的查询界面。

我们在地图上放一个圆环,通过动态改变圆环的半径,实现对轨迹的动态查询。另外,可以设定一些条件,比如说载客或者是不载客,也可以交互式的改变圆环和轨迹之间的几何关系,同时还可以进行多个圆环的复合查询,指定两个区域之间的方向,就可以过滤出你感兴趣的交通流。这样就完成了一个比较便捷的交互式探索,同时可以支持多个独立查询。
我们的设计思想就是基于圆环,用户在不同区域可以激活不同的功能。比如你在中心,就可以动态的去移动圆环,如果你在右下角,就会出现用于指定轨迹和圆环相交关系的一个条件。可能现在在大家看来这只是前台界面,但是其实我们还是设计了它背后的过滤方案。我们整个数据集是34GB,刚刚的演示是在一个单机上,大概是4GB的内存,我们常做的事情就是数据库和数据访问。我们的思路就是先建立一个空间索引,它是自适应的空间划分,把所有的轨迹都考虑进去。然后建立出一棵索引树,用户在查询的时候会放这个圆环。查询会分三个基本的步骤,第一个步骤是先找到圆环所在的结点,从硬盘中把这些结点的轨迹读到内存里,第二步就是怎么显示的问题,因为用户在交互的过程中是需要很快的反馈,不允许有延迟。所以我们在这里做了一个策略,先显示满足条件的前一百或者前一千条轨迹,特别是在用户移动的过程中,我们会一直查询前一百条轨迹。这个步骤看似没有道理,但是有很大的应用价值,因为交通轨迹是沿着路走的,如果你的路确实是有一些车辆经过,那么你在前一百条的时候就都已经查到显示在界面上,其实采样后的结果和最后的结果从视觉上看并没有存在太大的差距。第三步,在用户得到结果之后,我们会在后台同步的进行查询,对内存里所有数据进行遍历,查找到所有满足条件的轨迹,这时候得到的结果就是完全正确的。

有了流量统计工具我们就可以做很多事情,比如,我们可以查看哪些出租车会到北京国际会议中心,哪些出租车从北京国际会议中心出发,下面我们做了两个简单的统计。
这个统计是一个比较有意思的可视化,大家也可应用到自己的工作中。我们统计了一天的轨迹,这样的流量分布理论上来说应该是折线图,但是折线图会在高度上会浪费很多空间,所以我们把折线图分成很多等高的层,然后叠加到同一个水平线上,颜色越深层数越高。这样我们可以看出北京国际会议中心是很典型的工作区域,它是有早晚高峰的。而出发的车辆分布比较随意,每个时间段都有车辆从这里出发。
流量统计的工具除了做简单的统计,还可以看地理的分布,比如说在这里我们把中心的过滤器放置在北京西站,大家可以想想和北京西站相关的出租车都来自于哪里,去到哪里。
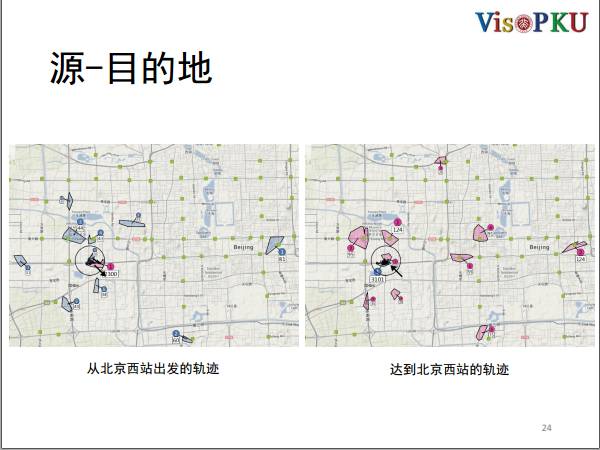
图上左边是从北京西站出发,右边是到达北京西站。这里有几个很有意思的现象,第一个就是北京站和北京南站以及北京西站,它们之间有一个比较常规的交通流,很可能是有人赶火车,他要从北京站到北京西站,或者是从北京西站到北京站。
第二个是北京西站的人有一部分是从西单过来的,而且人数比较多。西单是一个购物中心,很有可能是来旅游的人在走之前去血拼,所以从西单直接打车到北京西站。
第三个是有两个路口离北京站很近,但是仍然有很多人选择打车。这边有两个地铁站,绿色的点是表示地铁口,有人坐地铁下车之后再打车到北京西站,又或者是从北京西站打车到地铁口。从这些移动数据中,我们可以看出人的移动模式。
路段
研究完区域之后,我们来看看路段的情况。我们还是以北京国际会议中心为例,看看这附近的车况怎么样。我在昨天晚上两点钟从百度上截取了该路段的实时路况,我发现在中韩国际大厦的路况不是特别良好,昨天晚上回家的路上我看到鸟巢那边是有活动的,可能是这个原因导致了路段的拥堵。
我预测了一下明天早上的路况如何,不出意料,主路拥堵严重。有了这样的实时的工具我就能对北京国际会议中心附近的交通有很好的理解吗?其实并不是这样,因为每次获得的都是不同的情况,很难从图片中获得北京国际会议中心附近的路段有什么规律。

我们组做了关于路段速度的可视化。我们选定了一条路段,每一行是表示一天,每一个小方格表示一天中每十分钟的速度情况,其中灰色的是当前没有数据,绿色到红色是速度由快到慢逐步递减。从这个可视化中我们就可以看到这段路在夜晚的时候基本上没有什么车,早上的时候有一些红色的方格,代表着这段路在这段时间拥堵,下午的时候路况基本比较好,只是偶尔会有一些红色的方格。
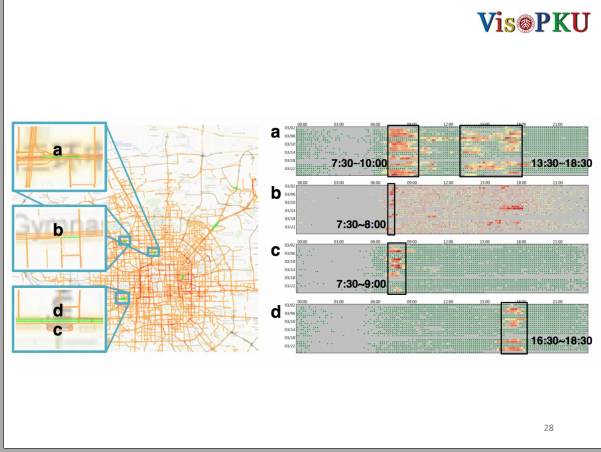
有了这样的可视化,我们就可以对不同的道路进行对比了。这里选择了四条路,A路是典型的北三环路段,它有很明显的早晚高峰现象,仔细看早上七点半到十点的时候有两行是绿色的,这两行是周末的时候,所以,不建议工作日的早上在七点三十或者是十点走A路。
看B路是四环上的一个路,这个路的状况更不好,因为它很少有绿色。但是它在七点半到八点是有一个比较明显的红块。其实,B路接近一个小学,家长要送小孩上学,导致这个时间段有了特定的拥堵。
C路和D路是连接北京西站和城内的路,C和D分别表示进城和出城的方向。C路平时是很畅通的,但是在早上七点半到九点的时候有很明显的拥堵情况,D路在傍晚会出现拥堵的情况,所以可以断定这条路是连接人们从生活区到工作区的一条很重要的路。
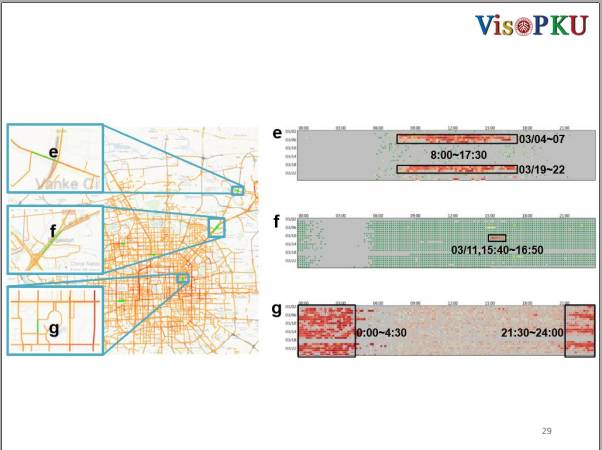
我们还可以来看一些其它的例子,比如,E是北京国际会展中心,可以看到在E基本上都是灰色的,因为平时很少出租车司机会去那里。有时候会有很密集的红色块出现,那是因为在这些天会有展览。所以,建议大家在有展览的时候,尽量不要去E路,除非你去看展。
F是北京首都机场的高速路,这条路一般状况是非常良好的,但是在3月11号的下午三点四十到四点五十发生拥堵事件。很明显,这是在整个交通运行的过程中出现的一次异常。
G是北京三里屯附近的一个路段,这个路段发现在晚上九点半以后到凌晨四点三十之间是非常拥堵的,很有可能是刚刚去完酒吧的人打车回家。
路段可能是我走了一步,而路径是我从这里走到另外一个地方,路径是由路段组成的,下面我们来研究一下路径的情况。
路径
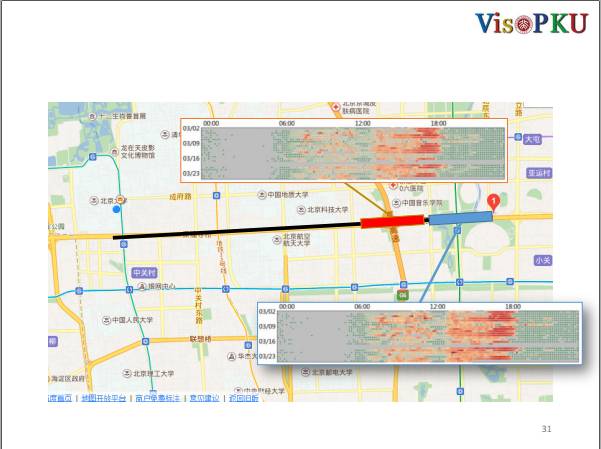
还是以北京国际会议中心为例,我从北大过来需要走一条路,我很关心这一条路在平时的状况是怎么样的,我应该考虑哪些路段的交通情况。刚刚我们获得了每个路段的交通可视化,那么我们把路径中每个路段的可视化叠加起来不就可以得到路径可视化?不,实际情况并不是这样的,路径可视化并不是路段可视化直接累加的结果。

我用过滤器可以很快的从数据库中查询到从北京国际会议中心到北大这条路上有哪些类型的出租车经过,然后我把整条路分成一段一段的,看出租车司机在每条路上的表现,对每个路段的通行时间进行统计。蓝色表示路段的平均通行时间,灰色是通行时间的方差。在这十个路段里面,二和三路段的通行时间的方差很大,而所有路段的平均通行时间是一样的。这个时候经过二三路段,时间是不确定的,时间分布的散度也很大。
为了对所有的轨迹经过的路段进行仔细分析,我们做了可视化。我们把北京国际会议中心到北大的一条路分成十份,每个竖线表示每个路段上的时间的分布。从上图可以看出异常值的分布,以及平均的高度。

我们把每一条轨迹表达成了一个条带,每个条带在每个路段上都有一个表现,所以每条轨迹在每根轴上都有一个位置,从高往下表示时间由少到多。绿色的整个条有很多轨迹,这个轨迹经过的每根轴都是最靠上的,也就是说这是一个最优的通行模式,越往下通行模式越差。红色可能是在有一些路段上位置比较靠下,最后的三个路段大家几乎是在一起的,无论你前面走的有多差,最后三个路段大家花费的时间是差不多的。
之后,我们可能想看什么时间段最好,什么时间段最差。这个可视化和上边的颜色是一样的,绿色是最好,红色是最差,竖着的轴是表示从凌晨到二十四小时,底下是早上,上面是晚上,因为我想对比工作日和周末,所以我分隔了两个区域,其中每一个小方格表示是一次通行的情况。红色大部分出现在早上七点到十点之间,但是周末很少有红色的色块出现。
我们现在选择的是早上七点到十点,回放每个点的每个出租车是怎么经过这个区域的。然后和历史数据进行验证,绿色的车每个路段都跑的很快,而红色的车在前面几个路段都堵住了,很慢才到达目的地。通过这种分析和验证的方式就可以获得对一条道路交通情况的理解。

刚刚那个例子是整个系统怎么交互式的对路段进行探索,现在我们只选择了中关村,从北四环和西四环到中关村的最后两个路段的方差很大,我们播放动画可以发现,前面大家差不多快,但是最后,这些车在这两个路段卡住了。通过时间分布我们可以看到工作日的早上,走到最后两个路段是没有问题的,但是这后面两条路最好还是选择改道吧。

有了可视化,我们就可以对整个北京市的道路做一个经验性的总结。在这里我们选了六条路,分别是图上显示的ABCDEF。因为北京是一个放射型的路网布局,它的环与环之间呈放射型,支路像毛细血管一样来连接北京交通。我们可以根据路段的宽窄来判断经过这个路段时间的不确定性,很多路都是从一个支路到主路上,这样的路花费时间的不确定性是很大的。
D是机场高速的一个路径,刚刚我们看过一个异常路段,在分析这段路的时候我们发现它灰色的条带宽度比较宽,时间花费不确定的。这是为什么呢?机场高速有一个收费站的闸口,你可能在那儿被卡住。如果运气好,没有什么车经过,你就可以顺利通过,如果你被卡住,那你可能要等很久。

D路段的每个时间段都有从绿色到红色的一个分布,为什么这条路在每个时间段都可能是最好也可能是最坏的?因为收费站卡的时间段和早晚高峰的关系不大,它是间歇性的卡一下,所以会导致在每个时间段都可能是最好也可能是最差。
拥堵传播
做完对道路路径的路况分析,我们来看看路与路之间的拥堵情况。
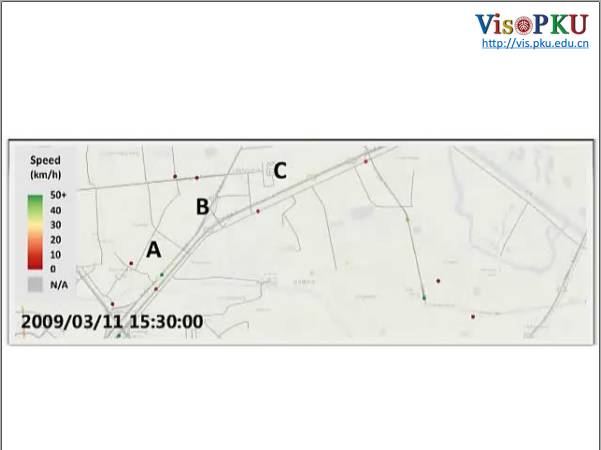
这段路有很多出租车经过,红色的点是由前往后蔓延的,但是逐渐到了后面,就变成了绿色的点,这就是一个拥堵传播。
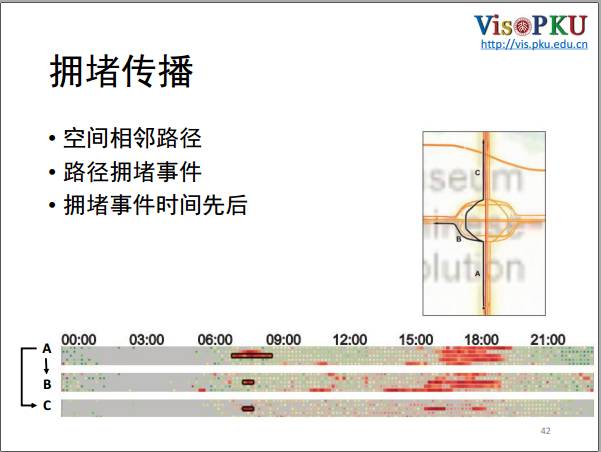
从算法上怎么检测拥堵的事件?拥堵很直观,首先要找到几段相邻的路,它们拓扑上是联通的。例如ABC三个路段,先找到相邻的路段,之后我们对每个路段的速度进行一个统计,找出它的拥堵事件,这里用黑色的框框起来的是我们检测到的拥堵事件。检测完拥堵事件之后,根据拥堵发生的时间先后顺序来确定路段之间拥堵传播的顺序,如果A路段是最早发生的,而BC是晚于A,那么就可以构建出一次拥堵传播关系,是由A到C,也是由A到B的。

思路很简单,但是实际情况会比上述的情况要复杂的多。图上是一个立交桥的路面,在这个路面上我们发现了两个拥堵的源头,一个是H,另一个是D,F路段同时受到了H和D两个源头的影响。通过这样的可视化工具就可以帮助专家发现拥堵的源头在哪里,如果我们把拥堵的源头治理一下,也许就能改善交通状况。
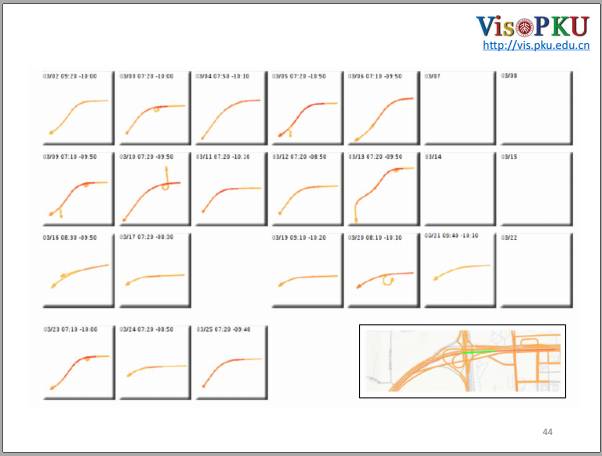
刚刚是一次拥堵事件,这是一个周期的拥堵事件,这段路是中关村万泉河桥,是去往中关村方向的一个路段。我们选定这个路段作为观察路段,根据提取出来的拥堵事件做了上面的图,每个方格表示拥堵事件,如果它有方格,就表示有拥堵传播事件,没有就表示没有检测到。
图上每一行的数据都是从周一到周末,总共是一个月的数据。虽然这条路每天的情况有些许不同,但是毫无疑问每天这条路都会拥堵。这个拥堵基本都发生在早上,因中关村的拥堵导致本身拥堵,之后蔓延到其它路段。
拥堵是有一个时间上的规律,出租车司机是很了解路面情况的,他们在选择路径时都有自己的打算,下面来分析一下多路径选择的行为。
路径选择因果分析
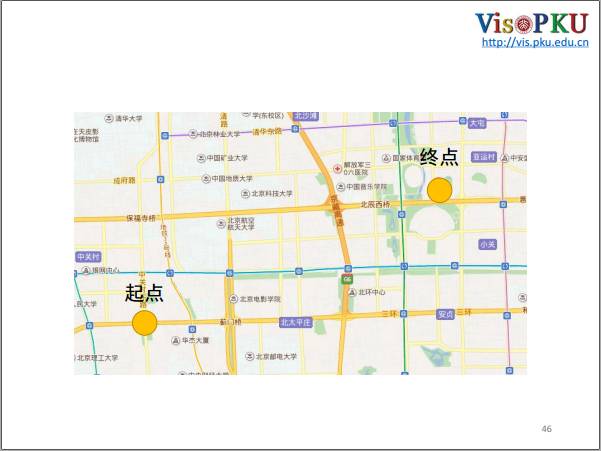
还是以北京国际会议中心为例,从地图上看,从起点到终点有很多条路可以选择,那么出租车司机会怎么选择呢?
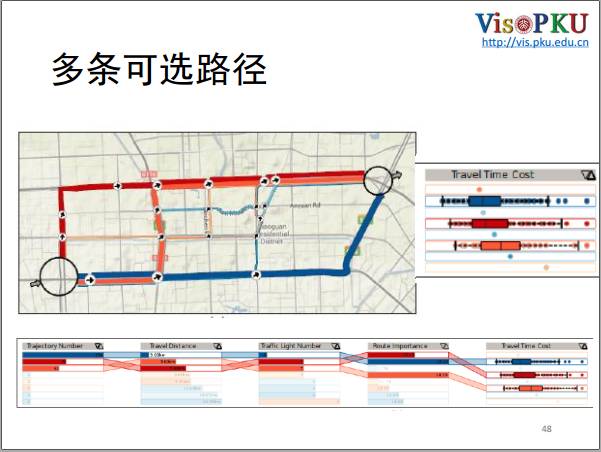
根据我们抓取到的数据,大部分的人选择了三条路,其它一小部分的司机会选择一些小路。
我们有一个路径抽取算法,抽取出来之后发现路的结构如上图所示,每一个条带都表示一种走法,宽度表示选这个走法的出租车司机数量。可以看到从四环直接开过去是比较主流的走法,按照紫色的路线一直开到四环口也是一种走法,第三种是先走三环,然后找机会开到四环再开到那个路口。这三条路的中间也会有一些变化,也就是橘色表示的路。
我们对这些路径进行了对比,得到了上面的柱形图,它表示的是选择这些路的数量分布,大概有一百五十六个出租车司机会选择紫色这条路,是最主流的路径。

我们对比了它的距离,发现紫色的距离最小,和橘色相差几百米。但是在地图上测试深蓝色的路是最短的。红绿灯数表示经过的路岔口,紫色的红绿灯是最少的,如果你走的小路越多,那么红绿灯就会越多。还有一个叫路的重要程度,我们认为主路是最重要的,因为主路的路面比较宽,行驶起来比较方便,所以走主路的评分比较高。从刚才对静态因素的分析和最后时间花费的统计发现,出租车司机有很丰富的经验,刚刚的一百七十六个出租车司机的平均的时间花费最小。
现在我们允许用户对不同的路径按照上述五个因素进行排序。蓝色这条路的选择最多,路程也是最短,红绿灯数也是相对比较少,重要程度也很高,并且平均时间分布也很短。通过可视化对路进行对比,就可以探究出出租车司机选择路的背后考虑因素。

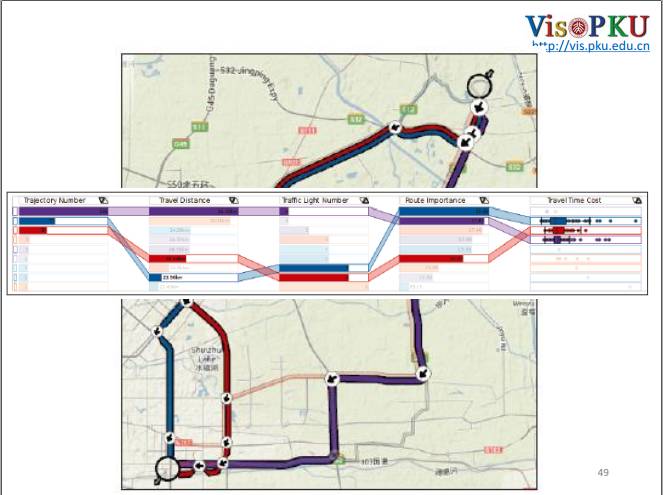
这是从北京机场到国贸的一个例子,通过数据过滤抽取出了三条主要的路。其中紫色,蓝色,橙色分别是一二三名,虽然紫色的路是最长的,但是它的红绿灯数少、路的重要程度是很高的,时间分布很集中,也就是说你在选择这条路的时间花费是比较确定的,不会像橙色和蓝色会有很大的方差。

我们把北三环到北四环的三条路进行对比。一般情况下,大家会选择蓝色这条路,我把他们的出发时间以及选择的路径画了一个柱形图。从左到右分别是零点到第二天零点,从形状上大概看出一个早晚高峰流量的分布。在早晨九点的时候,这段有很多橙色的路,为什么会有这么多橙色的路?我利用了一个交通领域的离散选择分析模型,把这段路作为因子输入到模型里,就可以看到在早上七点到十点这个时间段,人们会更倾向于选择橙色,而不是蓝色的路。通过可视化我可以直接过滤出这段路的轨迹,然后会发现在早上出发的时候,如果你走蓝色的路,它时间分布的散度是很大的,而橙色和红色都要小一点。所以在早上出发的时候,出租车司机会选择走橙色的路。
小结

我们通过规模分析了一个区域、路段和路径,路径之间的拥堵传播以及多条路的选择。我们在这方面发表了很多论文,如果大家对可视化感兴趣,可以去查看我们的论文。
关于DTCC
中国数据库技术大会(DTCC)是目前国内数据库与大数据领域最大规模的技术盛宴,于每年春季召开,迄今已成功举办了七届。大会云集了国内外顶尖专家,共同探讨MySQL、NoSQL、Oracle、缓存技术、云端数据库、智能数据平台、大数据安全、数据治理、大数据和开源、大数据创业、大数据深度学习等领域的前瞻性热点话题与技术,吸引IT人士参会5000余名,为数据库人群、大数据从业人员、广大互联网人士及行业相关人士提供了极具价值的交流平台。
