机器学习实战-kNN算法 学习随手记
- 错误解决
python numpy安装 cannot import name 'multiarray'
本身python是3.6.1版本,电脑64位
于是选取轮子 numpy-1.13.1-cp36-none-win_amd64.whl
于是到python的安装路径的scripts下, pipinstall numpy-1.13.1-cp36-none-win_amd64.whl
但是提示不适用
于是下了win32版本的轮子,安装却成功了,但是在尝试import numpy的时候,却提示 cannot import name 'multiarray'
于是一个很trick的做法,我直接先卸载了已安装的numpy: pipuninstall numpy
然后将numpy-1.13.1-cp36-none-win_amd64.whl 重命名为 numpy-1.13.1-cp36-none-win32.whl
安装成功
尝试importnumpy,也OK了,hhh
- Python模块重新加载
Python3可以用下面几种方法:
方法一:基本方法
from imp importreload
reload(module)
方法二:按照套路,可以这样
import imp
imp.reload(module)
方法三:看看imp.py,有发现,所以还可以这样
import importlib
importlib.reload(module)
方法四:根据天理,当然也可以这样
from importlib import reload
reload(module)
- 命令行环境从头开始的输入
>>> import kNN
>>> group, labels =kNN.createDataSet()
>>> kNN.classify0( [0,0],group, labels, 3)
'B'
>>> datingDataMat,datingLabels = kNN.file2matrix('datingTestSet2.txt')
>>> datingDataMat
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]])
>>> datingLabels[0:20]
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3, 1, 1, 2, 1, 1, 1, 1, 1, 2, 3]
>>> import matplotlib
>>> importmatplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax =fig.add_subplot(111)
>>> ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
>>> plt.show()
>>> from numpy import *
>>> ax.scatter(datingDataMat[:,1], datingDataMat[:,2],15.0*array(datingLabels), 15.0*array(datingLabels))
>>>plt.show()后展示图形:
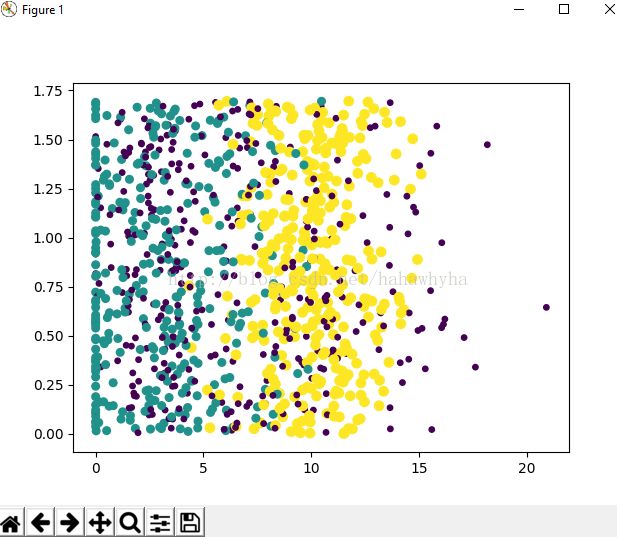
在plt.show()之后
>>> reload(kNN)
>>> normMat, ranges,minVals = kNN.autoNorm(datingDataMat)
>>> normMat
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
>>> ranges
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
>>> minVals
array([ 0. , 0. , 0.001156])
>>> reload(kNN)
>>> kNN.datingClassTest()
the classifier came back with: 3, the real answer is: 3
the classifier came back with: 2, the real answer is: 2
the classifier came back with: 1, the real answer is: 1
the total error rate is : 0.050000
>>> testVector =kNN.img2vector('testDigits/0_12.txt')
>>> testVector[0,0:31]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0.])
>>> testVector[1,0:31] #形成的是一行1024列的向量,因此左边的数只能为0表示取第一行,否则越界
Traceback (most recent call last):
File"
IndexError: index 1 is out of bounds for axis 0 with size 1
>>> kNN.handwritingClassTest()
the classifier came back with: 9, the real answer is: 9
the classifier came back with: 9, the real answer is: 9
the total number of errors is : 10
the total error rate is : 0.010571
#执行效率并不高,因为每次都要为每个测试向量做2000次距离计算(总共有2000个训练样本数据),每个距离计算包括了1024个维度浮点运算(每个样本都是32*32的二进制数字),总共要执行900次(总共900个测试样本数据)。而K决策树就是K近邻算法的优化版,可以节省大量计算开销。
- Shape()
shape函数是numpy.core.fromnumeric中的函数,它的功能是查看矩阵或者数组的维数。
建立一个4×2的矩阵c, c.shape[1] 为第一维的长度,c.shape[0]为第二维的长度。
>>> c = array([[1,1],[1,2],[1,3],[1,4]])
>>> c.shape
(4, 2)
>>> c.shape[0]
4
>>> c.shape[1]
2
- Tile()
格式:tile(A,reps)
* A:array_like
*输入的array
* reps:array_like
* A沿各个维度重复的次数
举例:A=[1,2]
1. tile(A,2)
结果:[1,2,1,2]
2. tile(A,(2,3))
结果:[[1,2,1,2,1,2],[1,2,1,2,1,2]]
3. tile(A,(2,2,3))
结果:[[[1,2,1,2,1,2],[1,2,1,2,1,2]],
[[1,2,1,2,1,2], [1,2,1,2,1,2]]]
reps的数字从后往前分别对应A的第N个维度的重复次数。如tile(A,2)表示A的第一个维度重复2遍,tile(A,(2,3))表示A的第一个维度重复3遍,然后第二个维度重复2遍,tile(A,(2,2,3))表示A的第一个维度重复3遍,第二个维度重复2遍,第三个维度重复2遍。
- Zeros()
创建0矩阵
- K近邻算法的另一个缺陷是无法给出任何数据的基础结构信息,因此我们无法知晓平均实例样本和典型实例样本具有什么特征。
- K近邻算法用不到“训练算法”这一步骤。
典型的过程包括:
- 收集数据:提供文本文件
- 准备数据:编写classify0函数,将图像转换为list格式
- 分析数据:python命令中检查数据,确保符合要求
- 训练算法:此步骤不适用于K近邻算法。(待理解,训练算法的算法是什么样的?待后续学习后对比理解)
- 测试算法:如果预测分类与实际类别不同,则错误数加一
- 使用算法:构建完整的应用程序来使用。如从图像中提取数字,并完成数字识别。
- 代码
from numpy import *
import operator
from os import listdir
def createDataSet():
group = array( [ [1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1] ])
labels = ['A', 'A', 'B','B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #计算矩阵的行数
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistance = sqDiffMat.sum(axis=1)
distance = sqDistance ** 0.5
sortedDistIndicies = distance.argsort() #sort by ascending order array([2, 3, 1, 0], dtype=int64)
classCount = {}
for i in range(k):
votelabel = labels[ sortedDistIndicies[i]]
classCount[votelabel] = classCount.get(votelabel,0) +1 #classCount {'B': 2, 'A': 1}
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0] # sortedClassCount[1][0] is 'A'
def file2matrix(filename):
fr = open(filename)
arrayLines = fr.readlines()
numberOfLines = len(arrayLines) # got the number of the file total lines
returnMat = zeros( (numberOfLines, 3)) #创建以0填充的矩阵
classLabelVector = []
index = 0
for line in arrayLines:
line = line.strip() #截取掉所有的回车字符
listFromLine = line.split('\t') #用tab字符将整行数据分割成一个元素列表
returnMat[index, :] = listFromLine[0:3]
classLabelVector.append( int (listFromLine[-1] )) #将最后一列存在label向量中,存储类型明确为int型,最后一列存储的是约会类型1,2,3
index += 1
return returnMat, classLabelVector
def autoNorm(dataSet): #归一化特征值,将数值转化到0-1区间内
minVals = dataSet.min(0) #所得大小为1*3
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros( shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio= 0.10
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0( normMat[i,:], normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]) )
if (classifierResult != datingLabels[i]): errorCount += 1.0
print ("the total error rate is : %f" % (errorCount/float(numTestVecs)) )
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percenTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("freguent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ ffMiles, percenTats, iceCream])
classifierResult = classify0((inArr-minVals)/ranges, normMat, datingLabels, 3)
print (" You will probably like this person:", resultList[classifierResult -1])
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32*i+j] = int(lineStr[j] )
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print ("the classifier came back with: %d, the real answer is: %d" %(classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount +=1.0
print ("\nthe total number of errors is : %d" % errorCount)
print ("\nthe total error rate is : %f" % (errorCount/float(mTest)))
- Appendix
机器学习实战勘误
Hi, and thanks for taking a look atMachine Learning in Action. If you find any errors that aren'tpublished below, please submit them to the book'sAuthor Online Forum.
On page 17:(not in a code listing)
The line:
myEye = randMat*invRandMat
should appear above the line:
>>> myEye – eye(4)
Listing 2.2,bottom of page 25 thru page26
A better version of thefunction file2matrix() is given below. The code in the book will work.
deffile2matrix(filename):
fr = open(filename)
arrayOLines =fr.readlines()
numberOfLines = len(arrayOLines)
returnMat =zeros((numberOfLines,3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine =line.split('\t')
returnMat[index,:] =listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
Page 26:
datingDataMat, datingLabels =kNN.file2matrix('datingTestSet.txt')
should be:
datingDataMat, datingLabels =kNN.file2matrix('datingTestSet2.txt')
>>>datingLabels[0:20]
['didntLike','smallDoses',……
should be:
>>>datingLabels[0:20]
[3, 2, 1, 1, 1, 1, 3, 3, 1, 3,1, 1, 2, 1, 1, 1, 1, 1, 2, 3]
Listing 2.5,page 32
datingDataMat, datingLabels =file2matrix('datingTestSet.txt')
should be:
datingDataMat, datingLabels =file2matrix('datingTestSet2.txt')
Page 41 (nota code listing)
l(xi) = log2p(xi)
Should be:
l(xi) = -log2p(xi)
Page 42:Listing 3.1
The line:
labelCounts[currentLabel] = 0
should be indented from thelines above and below it. The code in the repo is correct.
Listing 3.3,page 45
bestFeature = I
should be:
bestFeature = i
Page 52 (nota code listing)
>>>treePlotter.retrieveTree(1)
should return:
{'no surfacing': {0: 'no', 1:{'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
Page 92
Before the line:
>>> reload(logRegres)
add the line:
>>> from numpy import*
At the beginning of the book Imention that this should be added to every interactive session, but it will behelpful for people to see this line here if they don't remember that.
Page 104 (nota code listing)
|wTx+b|/ ||w||
should be:
|wTA+b|/||w||
Listing 8.4,page 168
The line:
returnMat = zeros((numIt,n))
Should be added before theline:
ws = zeros((n,1)); wsTest =ws.copy(); wsMax = ws.copy()
Listing 9.5,page 195
yHat = mat((m,1))
Should be:
yHat = mat(zeros((m,1)))
Page 230,second paragraph:
You can't create a set of justone integer in Python. It needs to be a list (try it out).
should be
The frozenset constructorrequires something iterable and won't take a single integer. To accommodatethis, we package each single integer in a list.