前程无忧python爬虫
前程无忧python爬虫
实践要求做一个数据分析以及处理的实验,我负责的是爬取数据的这一块任务。做爬虫的话,python是比较好用的,于是学习了一小段时间,专门学着写了一个小爬虫。爬取的是一些静态网页上的内容。
环境
语言:python 3.8
工具:PyCharm 2019
操作系统:win10
前言
我主要学习的是C++,对于python语言并没有学习过,但是就爬虫这一块,我去了解的时候发现,并没有什么多大的障碍。
就我的了解,python做爬虫实际上也是使用封装好的模块做。所以掌握一些基本的语法即可。
准备
- python下载
去官网上下载对应环境的版本安装即可。
python下载地址 - 编辑器ide(pycharm)下载
同样的可以去官网上下载安装,如果只是简单用的话,社区版本即可。
pycharm下载地址
实际上pycharm自带的有python解释器。这个具体在新建项目的时候可以选择对应想用的python解释器。
当然这样下来,所需要的模块是不存在的。
也可以去下载那种集成了所有开发所需要的开发包,模块和python解释器都弄好了的。
所需要用到的模块:
- requests
- lxml(主要是用其中的etree,xpath),或者是re(正则表达式)
- csv(最后把爬取到的结果存入excel表格)
如果不是集成开发包的话,需要自己安装对应的模块,那么安装命令一般是:
pip install xxx
爬取前程无忧网页数据
由于我之前自己写过一个小型简单的服务器,加上我接触过web项目,所以对于前端页面数据的一些概念是有基础的。
在参考爬虫资料时,我印象最为深刻的就是将爬虫就说成是模仿浏览器的行为。
对于输入url,然后显示网页在网络中的过程可以参考计算机网络。
那么我们先导入需要的模块:
import requests
from lxml import etree
import csv
既然是模仿浏览器,那么我们需要一个网址是吧,实际上就是url。这个url代表的是我们要爬取哪个网页。
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,1.html?'.format(job)
爬虫脱离不了那你想要爬取网页本身,开发过程中可以一边对着网页F12,一边撸码。
找到想要爬取的网页,在浏览器中找到url,可以分析出网页的一些特点,比如说,想要爬虫的岗位、页数在url中是哪个位置,如何变化,这些都是有规律的。
上面代码中job是一个变量,用于输入一个想要爬取的岗位。
有了url,主要用到的就是requests中的get方法。
response = requests.get(url)
这个方法返回到response,如果我们输出的话,会打印200,200是成功的状态码。
获取页面:response.text
当然,我们最好转换一下。
html = etree.HTML(response.text)
这个时候的html跟我们在浏览器F12出来的html源码别无二样,那里面的数据只要我们提取出来不就OK了吗?
爬虫实际上就是在一堆源码中提取想要的数据,并且在代码中实现反复提取。
requests模块基本上就使用完了,接下来就是怎么提取的问题。
一般有两种,一种是xpath,一种是正则表达式。
我主要用的是xpath。
在想要网页中F12选中想要的元素可以查看其在源码中的位置。这个时候,我们就容易去获取(静态网页是如此)。
我们要爬取前程无忧某一个岗位的所有相关信息。比如说,C++,有900多页。
那么我们需要将900多页中我们需要的数据都爬取下来,可以写成一个for循环,也就是说,我们只需要爬取一页,对应的,同样的模版也能爬取900多页,90000多页。
比如下面这个页面:

关于C++岗位有900多页。我们要写for循环之前需要知道具体岗位的页数,所以我们选中页面中想要的元素,如下图:
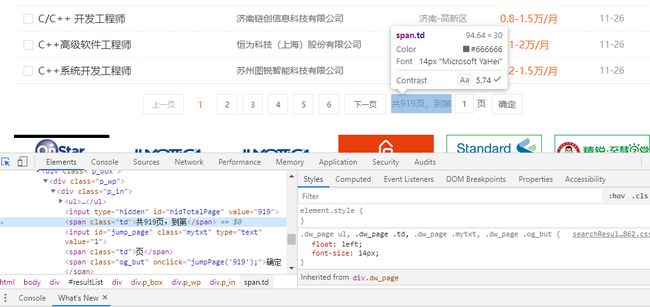
我们可以看到,919在一个标签中的value属性中。
我们可以使用xpath很轻松的获取这个value属性的值,如下:
sum_page = html.xpath('//div[@class="dw_page"]/div/div/div/input[@id="hidTotalPage"]/@value')[0]
- “//”意思是,(我的理解)选中的第一个标签,一般来说选一个源码中唯一的,有独特属性的。
- “/”就是下一个节点。
- “@”就是取哪一个属性。
最后[0]的意思是,xpath返回的是一个列表。我们需要取其中的元素,用数组思考即可。
获取到sum_page之后还是一个字符串,python中转换:
sum_page = int(sum_page)
基本上核心的东西就是这么多,非常简单。接着就可以愉快的爬取了。
最后数据的持久化可以存成excel表格,也可以存入数据库中。
excel表格即是导入csv模块,操作文件,参考最后源码。
在这个过程中所遇到的问题以及一些想说的总结
- 在爬取过程中,写入excel的情况下,如果源网页上提取的数据中本身就有一些是不符规则的,就会造成写入失败,程序就会终止。
比如说一些乱码字符啥的。这个时候一种解决方法是在写入的代码中这样处理:
with open(temp1 + '.csv', 'a', newline='', encoding='gbk', errors='ignore') as f1:
解释下:a是每次写都追加写,newline=’'是消除写入时的空行,encoding是编码问题,errors='ignore’就是在遇到错误时忽略。
- 在爬取的过程中如果不考虑多种情况的话,会出现比如说要爬取一个网页中的链接,紧接着要进入这个链接,爬取这个链接页面的数据。如果在前程无忧原网站维护时,突然将某个链接页面直接弄成是公司招聘官网,而不是前程无忧自己的网页就会出现错误,程序终止,解决方法:
public_str = 'https://jobs.51job.com/'
#str(new_url).find(public_str)
print(str(new_url).find(public_str) >= 0)
if(str(new_url).find(public_str) >= 0):
加一个判断。如果不是前程无忧自己的网页,就跳过。
- 在爬取公司对岗位要求时,想要的元素全在一个标签属性中。
我的一个解决方法是,分别取返回的列表中的对应的元素,如下:
company_info = new_html.xpath('//div[@class="tCompany_sidebar"]/div/div/p/@title')
company_nature = company_info[0]
company_size = company_info[1]
company_scope = company_info[2]
有些返回的字符串中可能有空格,python去除空格方法:
experience = experience.strip() #去除左右两边的空格
-
对于获取到的一个页面的所有岗位链接,对应的是一个岗位的公司信息,目前我还没有做到将岗位信息和公司信息整合在一起。也就是说我爬取到一个页面的所有岗位链接之后,再用一个for循环爬取每一个链接对应的公司信息,存入公司信息表。
这个过程,我要打开每一个链接,爬取再进行写入。 -
对于数据,到后面都是具体要求是C++,岗位却不是C++,所以这种大多都是无效数据。
-
前程无忧并没有任何的反爬措施,比如请求头,或者是封IP。
源码
import requests
from lxml import etree
import csv
print("hello world")
job = input('输入想要爬取的岗位:\n')
temp = r'C:\Users\10184\Desktop' + '\\' + job + "公司信息"
temp1 = r'C:\Users\10184\Desktop' + '\\' + job + "岗位信息"
with open(temp + '.csv', 'a', newline='', encoding='gbk') as f:
csvwriter = csv.writer(f, dialect='excel')
csvwriter.writerow(['公司名称','工作经验','学历要求','公司性质','公司规模','经营范围'])
with open(temp1 + '.csv', 'a', newline='', encoding='gbk') as f1:
csvwriter1 = csv.writer(f1, dialect='excel')
csvwriter1.writerow(['岗位名称','公司名称','公司地址','薪资','发布时间','链接'])
#url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,C%252B%252B,2,1.html?'
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,1.html?'.format(job)
response = requests.get(url)
html = etree.HTML(response.text)
sum_page = html.xpath('//div[@class="dw_page"]/div/div/div/input[@id="hidTotalPage"]/@value')[0]
sum_page = int(sum_page)
print(sum_page)
start_page = input('请输入你想要开始爬取的页数:\n')
start_page = int(start_page)
for i in range(start_page, sum_page):
#url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,C%252B%252B,2,{}.html?'.format(i)
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,{},2,{}.html?'.format(job, i)
response = requests.get(url)
response.encoding = 'gbk' # 编码格式
# response.encoding = response.apparent_encoding # 自动转换编码格式
response1 = response.text
# print(response.text)
html = etree.HTML(response1) # 将网页源代码转换成elements格式,好用xpath。
job_name = html.xpath('//div[@id="resultList"]/div[@class="el"]/p/span/a/@title')
#print(job_name)
company = html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t2"]/a/@title')
#print(company)
link = html.xpath('//div[@id="resultList"]/div[@class="el"]/p/span/a/@href')
#print(link)
#new_url = link
for linki in link:
new_url = linki
print(new_url)
public_str = 'https://jobs.51job.com/'
#str(new_url).find(public_str)
print(str(new_url).find(public_str) >= 0)
if(str(new_url).find(public_str) >= 0):
new_response = requests.get(new_url)
new_response.encoding = new_response.apparent_encoding
new_html = etree.HTML(new_response.text)
company_name = new_html.xpath('//div[@class="tHeader tHjob"]/div/div/p[@class="cname"]/a[@class="catn"]/@title')[0]
experience = new_html.xpath('//div[@class="tHeader tHjob"]/div/div/p[@class="msg ltype"]/text()')[1]
degree = new_html.xpath('//div[@class="tHeader tHjob"]/div/div/p[@class="msg ltype"]/text()')[2]
company_info = new_html.xpath('//div[@class="tCompany_sidebar"]/div/div/p/@title')
company_nature = company_info[0]
company_size = company_info[1]
company_scope = company_info[2]
#for a, b in zip(experience, degree):
#print(a, b)
#print(experience.strip()) #去除左右两边的空格
#print(degree.strip())
#print(company_name)
experience = experience.strip()
degree = degree.strip()
print([company_name, experience, degree, company_nature, company_size, company_scope])
print(i)
with open(temp+'.csv', 'a', newline='', encoding='gbk', errors='ignore') as f:
csvwriter = csv.writer(f, dialect='excel')
#csvwriter.writerow(['工作名字','公司名字',''])
csvwriter.writerow([company_name, experience, degree, company_nature, company_size, company_scope])
adrees = html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t3"]/text()')# text()取本文
#print(adrees)
salary = html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t4"]/text()')
#print(salary)
time = html.xpath('//div[@id="resultList"]/div[@class="el"]/span[@class="t5"]/text()')
for a,b,c,d,e,f in zip(job_name, company, adrees, salary, time, link):
print(a, b, c, d, e, f)
with open(temp1 + '.csv', 'a', newline='', encoding='gbk', errors='ignore') as f1:
csvwriter1 = csv.writer(f1, dialect='excel')
csvwriter1.writerow([a, b, c, d, e, f])