Python爬虫的小白学习笔记1-批量下载图片
目录
零、先定一个小目标
一、 获得地址
二、 一个简单的爬虫
三、 获取需要的信息
四、 将信息保存下来
五、 批量保存
六、 多线程
七、 程序打包
零、 先定一个小目标
最近在自学python,根据以往的学习经验来看,学习一门新技术最好是能学以致用,在实践过程中学习的效率是最高的,那么就先从创建一个爬虫程序来开始吧。
Lofter是网易出品的一个图片博客网站,上面的博主会收集很多好看的图片,我们就先定一个小目标,先做一个可以批量下载指定博主的全部图片的爬虫程序。
根据我们的思路,整个程序的流程应该是下面的:

每一个步骤可能都需要一定的相关的知识,我们分步骤来说,每一步学一点基础知识。
一、 获得地址
第一个步骤是获得目标网站的网址。
我们可以通过浏览器打开LOFTER的网站,观察一下每一个博主的网址的特点,比如“摄影精选”这个博主的网址为:http://photopick.lofter.com/
翻页后的地址为:
http://photopick.lofter.com/?page=2&t=1486174267091
http://photopick.lofter.com/?page=3&t=1486141435525
http://photopick.lofter.com/?page=4&t=1486097971577
…
乍一看倒是挺有规律的,前面的是主域名” http://photopick.lofter.com/”,问号”?”后面的是两个参数,第一个参数page很明显是页码,但是第二个参数t是什么鬼?!参数值完全没有啥规律可循啊。
单纯的我以为是LOFTER为了防止被爬做的url加密的措施,好在我测试了一下,不加第二个参数去访问也是没有问题的,所以所以我们的地址就可以很有规律的获得了,即主域名+?+page=i(不管第二个参数是啥了,反正不影响我们爬数据)。
对于地址无规律的网站,后续的地址也可以根据当前页的下一页按钮去获得,在这里我们先用上面的方法获得批量地址。
二、 一个简单的爬虫
根据上面的方法,地址已经有了,怎么获得内容呢,这里我们需要用到urllib2这个库,里面有现成的方法可以获得网页内容,代码如下:
import urllib2#引入urllib2库
class Spider:#声明一个爬虫类
def __init__(self,url):#构造函数进行初始化,第二个参数是我们要抓的网页url
self.url=url
def getPage(self):#获取网页内容的方法
url = self.url
requests = urllib2.Request(url)#构造Request实例
response = urllib2.urlopen(requests)
return response.read()#读取获得的网页内容
url = 'http://photopick.lofter.com/'#目标网页的地址
spider = Spider(url)#创建一个爬虫实例
print spider.getPage()#获得目标网页内容
其中用到了urllib2中的两个方法:Requests()和urlopen()
urllib2用一个Request对象来映射我们提出的网络请求,创建Request可以传入很多参数,我们这里只使用最简单的形式,只传入我们要请求的地址url来创建一个Request对象,再调用urlopen这个方法打开Request对象,将返回一个相关请求放入response对象,再调用.read()读取其中的内容。
如果没问题的话,我们会获得这个网页的整个代码文本,如下面的截图所示,但是。。乱糟糟的一堆代码,一脸懵逼!我们怎么才能从这些内容当中获得所需要的信息呢?
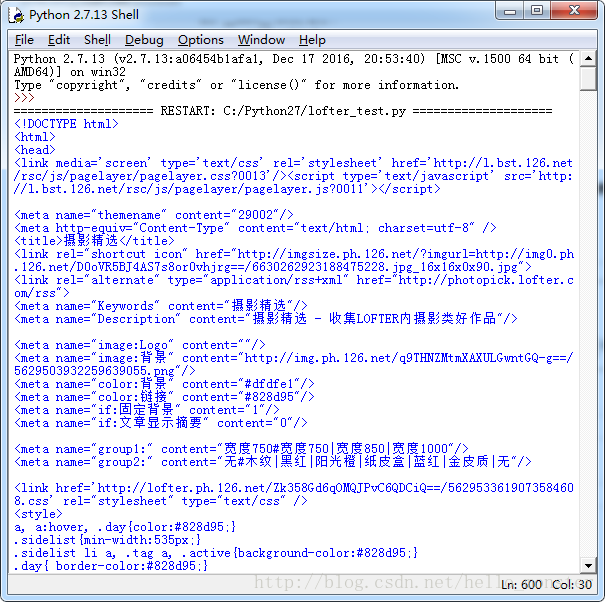
关键词:urllib2、Request、urlopen
三、获取需要的信息
在上一步骤中,我们已经获得了目标网页的文本编码信息,但是信息太多,我们需要从中筛选出我们需要的信息。
用chrome或者其他能查看网页源码的浏览器打开目标地址,按F12调出源码窗口:
可以看到,标签img_src=后面的就是图片地址,我们只要提取到这个页面中的地址,就能够获取到对应的图片数据啦!而且这些定位图片地址的字符串是有规律的,有规律就好办啦,程序本身就是用来处理一些有规律的事情的嘛~
下面我们引入一个概念:正则表达式
正则表达式是搜索、替换和解析复杂字符串的一种强大而标准的方法,我们可以用正则表达式去筛选出我们所需要的信息,要用正则表达式,我们需要引入re这个库。
简单来说,正则表达式就是用来代表一定规律的字符串的字符串,感觉好绕。。举个栗子:
import re
pattern = re.compile(r'hello')
text = 'hello world!'
m = re.match(pattern,text)
if m:
print m.group()
else:
print 'not match'这里用到了re里面的match函数,re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。Pattern不能直接实例化,必须使用re.compile()进行构造。
上面的例子很简单,就是再hello world里面精确匹配到hello。
关于正则表达式,并不是python独有的,功能非常强大,网上的资料很多,详细学习可以参考这个:http://deerchao.net/tutorials/regex/regex.htm,这里不展开说了,只介绍一下我们这次要用到的几个。
“.”在正则表达式中表示除换行符以外的任意字符;
“*”匹配前一个字符0次或者无限次;
“?”匹配前一个字符0次或者1次;
.*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配, (.*?)代表一个分组。
回过头来,我们观察一下我们要提取图片地址的这部分代码:
我们可以构建符合这段字符串的正则表达式去匹配,如下所示:
pattern = re.compile('',re.S)
然后我们将上次写的那个很简单的小爬虫再拿出来修改一下,加入筛选内容的部分,代码如下:
import urllib2#引入urllib2库
import re
class Spider:#声明一个爬虫类
def __init__(self,url):#构造函数进行初始化,第二个参数是我们要抓的网页url
self.url=url
def getPage(self):#获取网页内容的方法
url = self.url
requests = urllib2.Request(url)#构造Request实例
response = urllib2.urlopen(requests)
return response.read()#读取获得的网页内容
url = 'http://photopick.lofter.com/'#目标网页的地址
spider = Spider(url)#创建一个爬虫实例
content = spider.getPage()#获得目标网页内容
pattern = re.compile('',re.S)#创建符合图片地址格式的正则表达式
picUrls = re.findall(pattern,content)#在网页内容中查询符合要求的字符串
print len(picUrls)#看一下抓到几个符合要求的地址
for picUrl in picUrls:#查看具体的图片地址
print picUrl如果没有问题,我们就获得了这个页面所要抓取的图片地址,可以看到一共有10个,和我们在网页上看到的数量一致。
关键词:正则表达式 re
四、 将信息保存下来
有了地址之后,我们就可以获得图片数据了,这一步我们要把数据存到本地。
这里涉及到的知识点是写文件,一共需要三步:打开文件,写入内容,关闭文件
打开一个文件的代码很简单:file(‘filename’),比如我们用file(‘test.txt’)可以打开一个叫做test.txt的文档。也可以用open(),用法和file()一致。
可以用read()读取文件内容,也可以用write()函数将数据写入文件中,举例如下,我们将字符写入文件中,并读取了里面的内容。
myFile = file('test.txt','w')
text = 'hello world'
myFile.write(text)
myFile.close()
newFile = open('test.txt','r')
fileContent = newFile.read()
newFile.close()
print fileContent
file()和open()第一个参数为文件名,第二个参数为打开的模式,打开的模式有以下几种:
w 以写方式打开,
a 以追加模式打开 (从 EOF 开始, 必要时创建新文件)
r+ 以读写模式打开
w+ 以读写模式打开 (参见 w )
a+ 以读写模式打开 (参见 a )
rb 以二进制读模式打开
wb 以二进制写模式打开 (参见 w )
ab 以二进制追加模式打开 (参见 a )
rb+ 以二进制读写模式打开 (参见 r+ )
wb+ 以二进制读写模式打开 (参见 w+ )
ab+ 以二进制读写模式打开 (参见 a+ )
现在回到我们的小目标当中,再上一步当中我们已经获得了图片的地址,下面我们就将图片写入到本地中,代码如下:
import urllib
import urllib2#引入urllib2库
import re
class Spider:#声明一个爬虫类
def __init__(self,url):#构造函数进行初始化,第二个参数是我们要抓的网页url
self.url=url
def getPage(self):#获取网页内容的方法
url = self.url
requests = urllib2.Request(url)#构造Request实例
response = urllib2.urlopen(requests)
return response.read()#读取获得的网页内容
url = 'http://photopick.lofter.com/'#目标网页的地址
spider = Spider(url)#创建一个爬虫实例
content = spider.getPage()#获得目标网页内容
pattern = re.compile('',re.S)#创建符合图片地址格式的正则表达式
picUrls = re.findall(pattern,content)#在网页内容中查询符合要求的字符串
print len(picUrls)#看一下抓到几个符合要求的地址
num = 1
for picUrl in picUrls:
pic = urllib.urlopen(picUrl)#打开图片网址
picData = pic.read()#读取图片数据
picFile = open('pic-'+str(num)+'.jpg','wb')#打开本地图片文件
picFile.write(picData)#写入图片数据
picFile.close()#关闭文件
num +=1
没问题的话,我们就能将这个网页的符合要求的图片批量下载下来啦
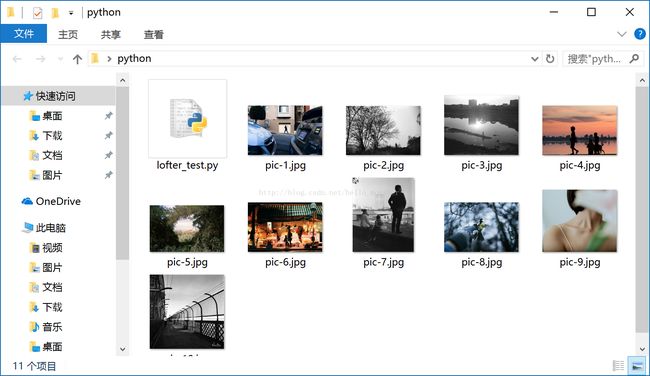
未完待续...