常用编码:Shift_JIS, GBK,EUCKR,Big5,UTF8,CP1252
(1) Shift_JIS
Shift_JIS是一个日本电脑系统常用的编码表。它能容纳全角及半角拉丁字母、平假名、片假名、符号及日语汉字。
它被命名为Shift_JIS的原因,是它在放置全角字符时,要避开原本在0xA1-0xDF放置的半角假名字符。
在微软及IBM的日语电脑系统中,即使用了这个编码表。这个编码表称为CP932。
目录[隐藏]
|
[编辑]字节结构
以下字符在Shift_JIS使用一个字节来表示。
- ASCII字符 (0x20-0x7E),但“\”被“¥”取代
- ASCII 控制字符(0x00-0x1F、0x7F)
- JIS X 0201标准内的半角标点及片假名(0xA1-0xDF)
- 在部分操作系统中,0xA0用来放置“不换行空格”。
以下字符在Shift_JIS使用两个字节来表示。
-
JIS X 0208字集的所有字符
- “第一位字节”使用0x81-0x9F、0xE0-0xEF(共47个)
- “第二位字节”使用0x40-0x7E、0x80-0xFC(共188个)
-
使用者定义区
- “第一位字节”使用0xF0-0xFC(共13个)
- “第二位字节”使用0x40-0x7E、0x80-0xFC(共188个)
在Shift_JIS编码表中,并未使用0xFD、0xFE及0xFF。
在微软及IBM的日语电脑系统中,在0xFA、0xFB及0xFC的两字节区域,加入了388个JIS X 0208没有收录的符号和汉字。
[编辑]Shift_JIS编码表
| Shift_JIS | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | ¥ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ‾ | DEL |
| 8x | ||||||||||||||||
| 9x | ||||||||||||||||
| Ax | 。 | “ | ” | 、 | ・ | ヲ | ァ | ィ | ゥ | ェ | ォ | ャ | ュ | ョ | ッ | |
| Bx | ー | ア | イ | ウ | エ | オ | カ | キ | ク | ケ | コ | サ | シ | ス | セ | ソ |
| Cx | タ | チ | ツ | テ | ト | ナ | ニ | ヌ | ネ | ノ | ハ | ヒ | フ | ヘ | ホ | マ |
| Dx | ミ | ム | メ | モ | ヤ | ユ | ヨ | ラ | リ | ル | レ | ロ | ワ | ン | ゙ | ゚ |
| Ex | ||||||||||||||||
| Fx | ||||||||||||||||
上图粉红色为JIS X 0207定义的控制字符;浅蓝色为JIS X 0201一字节符号的所在范围;紫色为JIS X 0208两字节汉字和全角符号的所在范围;黄色为JIS X 0201以“¥”替换了“\”、以“‾”替换了“~”;绿色为未编码。
[编辑]JIS转换方法
由JIS X 0208转换至Shift_JIS的方法:
-

-
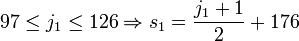
-
 是 奇数
是 奇数
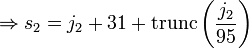
-
是 偶数

[编辑]参看
- ASCII
- JIS X 0201
- JIS X 0208
- ISO/IEC 2022
- EUC
- 日本工业标准(JIS, Japan Industrial Standard)
[编辑]外部链接
- 微软CP932编码表
- Ping: Japanese text encoding
- Shift_JIS中,非ASCII部分的编码表
- Shift_JIS的发展
|
|||||||||||||||||||||||||||||||||||||||||||||||
(2) GBK
GBK是汉字编码标准之一,全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification).
我们经常使用各种编码标准的汉字,编码到底是什么呢?所谓编码,是以固定的顺序排列字符,并以此做为记录、存贮、传递、交换的统一内部特征,这个字符排列顺序被称为“编码”。和中文字库有关的编码标准有:国标GB码、GBK码、港台BIG-5码等,不同编码的汉字字库都与汉字的应用有密切关系。
很多人在使用过程中,发现字不够用,因为目前大家使用的主要是GB编码字库,此编码标准只收录了6763个常用汉字,而GB字库以外大量汉字,只能通过方正女娲补字软件拼字或其它造字程序补字。尽管补出的汉字在字形上满足需要,但在字体风格、大小、结构方面难以协调统一,而采用手工贴图的方式补字,更不雅观。进而言之,如果用户建立信息系统,或需要查询新闻、出版内容时,靠补字是无法实现的。方正开发的GBK字库,将极大地缓解缺字现象。
从GB字库扩充到GBK字库,增加了1万4千多字。北大方正从1996年投入大量人力,开始做黑、宋、仿、楷GBK字库,并于1998年4月成为第一家通过国家权威部门组织的GBK字库鉴定的专业厂商。到现在为止,北大方正已将全部字体转换成GBK字库,共46款,其中18款字数达21003个,是拥有GBK字库款数最多的厂商。
ISO 10646 是一个包括世界上各种语言的书面形式以及附加符号的编码体系。其中的汉字部分称为“CJK 统一汉字”(C 指中国,J 指日本,K 指朝鲜)。而其中的中国部分,包括了源自中国大陆的 GB 2312、GB 12345、《现代汉语通用字表》等法定标准的汉字和符号,以及源自台湾的 CNS 11643 标准中第 1、2 字面(基本等同于 BIG-5 编码)、第 14 字面的汉字和符号。
(3) EUCKR
朝鲜语编码
(4) Big-5
BIG-5码是通行于台湾、香港地区的一个繁体字编码方案,俗称“大五码”。地区标准号为:CNS11643,这就是人们讲的BIG-5码。
大五码(Big5),又称为五大码,是使用繁体中文社群中最常用的电脑汉字字符集标准,共收录13,060个中文字,其中有二字为重覆编码,Big5属中文内码(中文码分为中文内码及中文交换码两类)。Big5虽普及于中国的台湾、香港与澳门等繁体中文通行区,但长期以来并非当地的国家标准,而只是业界标准(de facto standard)。倚天中文系统、Windows等主要系统的字符集都是以Big5为基准,但厂商又各自增删,衍生成多种不同版本。
(5) UTF8
UTF-8是UNICODE的一种变长字符编码又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言.
如果UNICODE字符由2个字节表示,则编码成UTF-8很可能需要3个字节。而如果UNICODE字符由4个字节表示,则编码成UTF-8可能需要6个字节。用4个或6个字节去编码一个UNICODE字符可能太多了,但很少会遇到那样的UNICODE字符。 UTF-8转换表表示如下:
| UNICODE | bit数 | UTF-8 | byte数 | 备注 |
| 0000 0000 ~ 0000 007F |
0~7 | 0XXX XXXX | 1 | |
| 0000 0080 ~ 0000 07FF |
8~11 | 110X XXXX 10XX XXXX |
2 | |
| 0000 0800 ~ 0000 FFFF |
12~16 | 1110 XXXX 10XX XXXX 10XX XXXX |
3 | 基本定义范围:0~FFFF |
| 0001 0000 ~ 001F FFFF |
17~21 | 1111 0XXX 10XX XXXX 10XX XXXX 10XX XXXX |
4 | Unicode6.1定义范围:0~10 FFFF |
| 0020 0000 ~ 03FF FFFF |
22~26 | 1111 10XX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
5 | |
| 0400 0000 ~ 7FFF FFFF |
27~31 | 1111 110X 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX 10XX XXXX |
6 | |
示例
UNICODE uCA(11001010) 编码成UTF-8将需要2个字节:
uCA -> C3 8A
UNICODE uF03F (11110000 00111111) 编码成UTF-8将需要3个字节:
u F03F -> EF 80 BF
| Unicode 16进制 | Unicode 2进制 | bit数 | UTF-8 2进制 | UTF-8 16进制 |
| CA | 1100 1010 | 8 | 1100 0011 1000 1010 | C3 8A |
| F0 3F | 1111 0000 0011 1111 | 16 | 1110 1111 1000 0000 1011 1111 | EF 80 BF |
(6) cp1252
Eclipse的default编码是cp1252.
以下是所有编码说明:
| armscii8 (ARMSCII-8 Armenian) | |
| armscii8_bin | 亚美尼亚语, 二进制 |
| armscii8_general_ci | 亚美尼亚语, 不区分大小写 |
| ascii (US ASCII) | |
| ascii_bin | 西欧 (多语言), 二进制 |
| ascii_general_ci | 西欧 (多语言), 不区分大小写 |
| big5 (Big5 Traditional Chinese) | |
| big5_bin | 繁体中文, 二进制 |
| big5_chinese_ci | 繁体中文, 不区分大小写 |
| binary (Binary pseudo charset) | |
| binary | 二进制 |
| cp1250 (Windows Central European) | |
| cp1250_bin | 中欧 (多语言), 二进制 |
| cp1250_croatian_ci | 克罗地亚语, 不区分大小写 |
| cp1250_czech_cs | 捷克语, 区分大小写 |
| cp1250_general_ci | 中欧 (多语言), 不区分大小写 |
| cp1251 (Windows Cyrillic) | |
| cp1251_bin | 西里尔语 (多语言), 二进制 |
| cp1251_bulgarian_ci | 保加利亚语, 不区分大小写 |
| cp1251_general_ci | 西里尔语 (多语言), 不区分大小写 |
| cp1251_general_cs | 西里尔语 (多语言), 区分大小写 |
| cp1251_ukrainian_ci | 乌克兰语, 不区分大小写 |
| cp1256 (Windows Arabic) | |
| cp1256_bin | 阿拉伯语, 二进制 |
| cp1256_general_ci | 阿拉伯语, 不区分大小写 |
| cp1257 (Windows Baltic) | |
| cp1257_bin | 巴拉克语 (多语言), 二进制 |
| cp1257_general_ci | 巴拉克语 (多语言), 不区分大小写 |
| cp1257_lithuanian_ci | 立陶宛语, 不区分大小写 |
| cp850 (DOS West European) | |
| cp850_bin | 西欧 (多语言), 二进制 |
| cp850_general_ci | 西欧 (多语言), 不区分大小写 |
| cp852 (DOS Central European) | |
| cp852_bin | 中欧 (多语言), 二进制 |
| cp852_general_ci | 中欧 (多语言), 不区分大小写 |
| cp866 (DOS Russian) | |
| cp866_bin | 俄语, 二进制 |
| cp866_general_ci | 俄语, 不区分大小写 |
| cp932 (SJIS for Windows Japanese) | |
| cp932_bin | 日语, 二进制 |
| cp932_japanese_ci | 日语, 不区分大小写 |
| dec8 (DEC West European) | |
| dec8_bin | 西欧 (多语言), 二进制 |
| dec8_swedish_ci | 瑞典语, 不区分大小写 |
| euckr (EUC-KR Korean) | |
| euckr_bin | 朝鲜语, 二进制 |
| euckr_korean_ci | 朝鲜语, 不区分大小写 |
| gb2312 (GB2312 Simplified Chinese) | |
| gb2312_bin | 简体中文, 二进制 |
| gb2312_chinese_ci | 简体中文, 不区分大小写 |
| gbk (GBK Simplified Chinese) | |
| gbk_bin | 简体中文, 二进制 |
| gbk_chinese_ci | 简体中文, 不区分大小写 |
| geostd8 (GEOSTD8 Georgian) | |
| geostd8_bin | 乔治亚语, 二进制 |
| geostd8_general_ci | 乔治亚语, 不区分大小写 |
| greek (ISO 8859-7 Greek) | |
| greek_bin | 希腊语, 二进制 |
| greek_general_ci | 希腊语, 不区分大小写 |
| hebrew (ISO 8859-8 Hebrew) | |
| hebrew_bin | 希伯来语, 二进制 |
| hebrew_general_ci | 希伯来语, 不区分大小写 |
| hp8 (HP West European) | |
| hp8_bin | 西欧 (多语言), 二进制 |
| hp8_english_ci | 英语, 不区分大小写 |
| keybcs2 (DOS Kamenicky Czech-Slovak) | |
| keybcs2_bin | 捷克斯洛伐克语, 二进制 |
| keybcs2_general_ci | 捷克斯洛伐克语, 不区分大小写 |
| koi8r (KOI8-R Relcom Russian) | |
| koi8r_bin | 俄语, 二进制 |
| koi8r_general_ci | 俄语, 不区分大小写 |
| koi8u (KOI8-U Ukrainian) | |
| koi8u_bin | 乌克兰语, 二进制 |
| koi8u_general_ci | 乌克兰语, 不区分大小写 |
| latin1 (cp1252 West European) | |
| latin1_bin | 西欧 (多语言), 二进制 |
| latin1_danish_ci | 丹麦语, 不区分大小写 |
| latin1_general_ci | 西欧 (多语言), 不区分大小写 |
| latin1_general_cs | 西欧 (多语言), 区分大小写 |
| latin1_german1_ci | 德语 (字典), 不区分大小写 |
| latin1_german2_ci | 德语 (电话本), 不区分大小写 |
| latin1_spanish_ci | 西班牙语, 不区分大小写 |
| latin1_swedish_ci | 瑞典语, 不区分大小写 |
| latin2 (ISO 8859-2 Central European) | |
| latin2_bin | 中欧 (多语言), 二进制 |
| latin2_croatian_ci | 克罗地亚语, 不区分大小写 |
| latin2_czech_cs | 捷克语, 区分大小写 |
| latin2_general_ci | 中欧 (多语言), 不区分大小写 |
| latin2_hungarian_ci | 匈牙利语, 不区分大小写 |
| latin5 (ISO 8859-9 Turkish) | |
| latin5_bin | 土耳其语, 二进制 |
| latin5_turkish_ci | 土耳其语, 不区分大小写 |
| latin7 (ISO 8859-13 Baltic) | |
| latin7_bin | 巴拉克语 (多语言), 二进制 |
| latin7_estonian_cs | 爱沙尼亚语, 区分大小写 |
| latin7_general_ci | 巴拉克语 (多语言), 不区分大小写 |
| latin7_general_cs | 巴拉克语 (多语言), 区分大小写 |
| macce (Mac Central European) | |
| macce_bin | 中欧 (多语言), 二进制 |
| macce_general_ci | 中欧 (多语言), 不区分大小写 |
| macroman (Mac West European) | |
| macroman_bin | 西欧 (多语言), 二进制 |
| macroman_general_ci | 西欧 (多语言), 不区分大小写 |
| sjis (Shift-JIS Japanese) | |
| sjis_bin | 日语, 二进制 |
| sjis_japanese_ci | 日语, 不区分大小写 |
| swe7 (7bit Swedish) | |
| swe7_bin | 瑞典语, 二进制 |
| swe7_swedish_ci | 瑞典语, 不区分大小写 |
| tis620 (TIS620 Thai) | |
| tis620_bin | 泰语, 二进制 |
| tis620_thai_ci | 泰语, 不区分大小写 |
| ucs2 (UCS-2 Unicode) | |
| ucs2_bin | Unicode (多语言), 二进制 |
| ucs2_czech_ci | 捷克语, 不区分大小写 |
| ucs2_danish_ci | 丹麦语, 不区分大小写 |
| ucs2_estonian_ci | 爱沙尼亚语, 不区分大小写 |
| ucs2_general_ci | Unicode (多语言), 不区分大小写 |
| ucs2_icelandic_ci | 冰岛语, 不区分大小写 |
| ucs2_latvian_ci | 拉脱维亚语, 不区分大小写 |
| ucs2_lithuanian_ci | 立陶宛语, 不区分大小写 |
| ucs2_persian_ci | 波斯语, 不区分大小写 |
| ucs2_polish_ci | 波兰语, 不区分大小写 |
| ucs2_roman_ci | 西欧, 不区分大小写 |
| ucs2_romanian_ci | 罗马尼亚语, 不区分大小写 |
| ucs2_slovak_ci | 斯洛伐克语, 不区分大小写 |
| ucs2_slovenian_ci | 斯洛文尼亚语, 不区分大小写 |
| ucs2_spanish2_ci | 传统西班牙语, 不区分大小写 |
| ucs2_spanish_ci | 西班牙语, 不区分大小写 |
| ucs2_swedish_ci | 瑞典语, 不区分大小写 |
| ucs2_turkish_ci | 土耳其语, 不区分大小写 |
| ucs2_unicode_ci | Unicode (多语言), 不区分大小写 |
| ujis (EUC-JP Japanese) | |
| ujis_bin | 日语, 二进制 |
| ujis_japanese_ci | 日语, 不区分大小写 |
| utf8 (UTF-8 Unicode) | |
| utf8_bin | Unicode (多语言), 二进制 |
| utf8_czech_ci | 捷克语, 不区分大小写 |
| utf8_danish_ci | 丹麦语, 不区分大小写 |
| utf8_estonian_ci | 爱沙尼亚语, 不区分大小写 |
| utf8_general_ci | Unicode (多语言), 不区分大小写 |
| utf8_icelandic_ci | 冰岛语, 不区分大小写 |
| utf8_latvian_ci | 拉脱维亚语, 不区分大小写 |
| utf8_lithuanian_ci | 立陶宛语, 不区分大小写 |
| utf8_persian_ci | 波斯语, 不区分大小写 |
| utf8_polish_ci | 波兰语, 不区分大小写 |
| utf8_roman_ci | 西欧, 不区分大小写 |
| utf8_romanian_ci | 罗马尼亚语, 不区分大小写 |
| utf8_slovak_ci | 斯洛伐克语, 不区分大小写 |
| utf8_slovenian_ci | 斯洛文尼亚语, 不区分大小写 |
| utf8_spanish2_ci | 传统西班牙语, 不区分大小写 |
| utf8_spanish_ci | 西班牙语, 不区分大小写 |
| utf8_swedish_ci | 瑞典语, 不区分大小写 |
| utf8_turkish_ci | 土耳其语, 不区分大小写 |
| utf8_unicode_ci | Unicode (多语言), 不区分大小写 |