Python3巧用百度翻译打造属于自己的终端翻译,极易版
查文献或看网站遇到英文单词简直是头疼,打开网页用百度翻译慢吞吞,瞬间失去阅读兴趣,有道翻译等软件是好用,但万一你是Linux系统呢,万一你只有小黑窗呢?
昨天晚上恰巧看到一篇相关文章,萌发自己写个命令行翻译小trick的想法,文末给出那篇文章链接。
先看看实现效果:

fanyi是自己设定的快速命令(原本命令很长,可以设定别名替代)
输入你要翻译的内容,结果会在下面一行显示
废话不多说,直接上代码(有注释)
baidu_translate.py
import json
import os
import requests
import sys
def translate(sentence):
"""
主要的翻译函数,通过post提交请求,解析得到的json数据得到翻译结果
:param sentence: 你需要翻译的内容
:return: 翻译的结果
"""
# 判断中译英还是英译中
# 只根据句子第一个词判读
# 这里一定要加encode,不然中文也会被识别为英文字符
if sentence[0].encode('utf-8').isalpha():
# 分别赋值的意思
from_, to_ = 'en', 'zh'
else:
from_, to_ = 'zh', 'en'
# 这个url是根据百度翻译页面的请求得来的
url = 'http://fanyi.baidu.com/basetrans'
# 请求头假装自己是手机,因为手机页面比较简单好处理
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Mobile Safari/537.36',
}
# 这个是根据浏览器F12查看得到一个叫basetrans文件里面的请求参数
# 用的是post提交方法,get似乎得不到结果
data = {
'query': sentence,
'from': from_,
'to': to_,
}
respone = requests.post(url, headers=headers, data=data)
# 提取返回的那个basetrans文件,里面有翻译的结果等各种参数
result = json.loads(respone.content.decode('utf-8'))
# 用了json包加载之后直接简单处理字典即可
result = result['trans'][0]['dst']
# 这里打印翻译结果,不换行,方便看结果
print(result)
return result
def translate_in_local_file(sentence):
"""
构建一个本地的词汇库文件,如果所查词汇在这个文件中,直接返回查询结果
否则就去百度翻译那里进行翻译
个人喜好加的词汇库,主要有时候断网了,查的词汇又是经常查的比较方便
:param sentence: 翻译内容
:return: 无
"""
# 把词汇库放在哪,os.getcwd默认就是这个py文件目录,在下面再创建一个vocabulary文件
dir = os.getcwd()
vocabulary = os.path.join(dir,'vocabulary.txt')
# 以添加方式打开文件,当然也可以写入内容
f = open(vocabulary, 'a+', encoding='utf-8')
# 因为一开始文件指针是在文件末尾,我们把它移动到文件开头,这样才能从头开始读取
# 如果不懂文件指针是什么,请具体百度
f.seek(0, 0)
# 羡慕就是简单的判断文件保存过你查询的关键词没
lines = f.readlines()
if len(lines) > 0:
for line in lines:
kw, tr = line.split('\t')
if sentence == kw:
print(tr, end='')
f.close()
return
result = translate(sentence)
# 保存的方式是以"关键词 翻译结果"这种格式一行行保存的
f.write((sentence + '\t' + result + '\n'))
f.close()
def main():
# 这个sys.argv是命令行参数
# 就是你在cmd或者其他命令窗口输入的所有命令
if len(sys.argv) < 2:
# 这个文件需要在命令行下执行,不能直接在ide中运行
print('使用方式:\npython3 %s 你要查的中英文单词or句子\n'% sys.argv[0])
print('或你自己设定的别名 你要查的中英文单词or句子')
return
# 可以不仅仅只查一个词,可以在命令行输入多个词
keywords = sys.argv[1:]
# 把所有输入的词拼接成一个句子
sentence = ' '.join(keywords)
#####################################
# 1 # 如果不需要构建本地词汇库,直接注释掉这句,用下面那句即可
translate_in_local_file(sentence)
# 2 # 全是在线查询,#1 和#2注释掉一个即可
# translate(sentence)
#####################################
# 就几个词的时候
# 时间测试可以用time.time()进行,具体百度
# 离线耗时:0.0004999637603759766
# 在线耗时:0.4414076805114746
if __name__ == '__main__':
main()写完代码,再来做一下最开始提到的那个别名的设置方法
Linux下
这里只给出ubuntu系统的参考方案:
进入到py文件保存的地方
pwd/home/ubuntu/python/spider_learning/baidu_translate
打开设置别名的文件
vi ~/.bashrc用光标移动到一个空行
![]()
先按下字母i进入编辑模式,填写如上面那串
alias fanyi='python3/home/ubuntu/python/spider_learning/baidu_translate/baidu_translate.py'注意,前面大部分路径都是通过之前pwd代码得到的,只有.py的那个文件名字是自己手填的
写完之后按下esc键,然后在编辑界面输入:wq 就可以保存文件了(如果不熟悉linux的文件编辑器,详查百度的vim相关内容)
保存完毕之后输入下面命令更新配置文件:
source ~/.bashrc来检验一下成果:
![]()

效果还是可以的,而且配合离线搜索,效率快了不少,如果更加追求效率,可以设定一些缓存,不过这个就太难了,在这里不做展开
关于怎么获取json和怎么查看该如何向百度发起查询请求,请参考
https://blog.csdn.net/xu_xuekai/article/details/79883819
我也是看到他的文章,觉得有趣,然后就强化了一下他的功能。
windows下
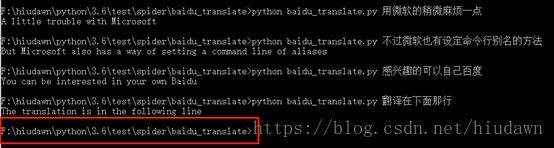
比较麻烦,没配置环境变量的话要进入py文件所在目录输入那一串。
当然,微软也可以设置命令行别名,让你不用输入python baidu_translate.py这串,可以用诸如一个fanyi这样的简短命令代替,这需要配置环境变量和设定一些东西,但这里我就不展开了,有兴趣的可以查查相关内容。
更正
这个代码编辑器改代码真是操蛋,上面有个地方再稍微优化一下
vocabulary.txt保存位置会不固定。如果有用到,找到:
dir = os.getcwd()
vocabulary = os.path.join(dir,'vocabulary.txt')
改成
dir = os.path.split(os.path.realpath(__file__))[0]
vocabulary = os.path.join(dir,'vocabulary.txt')
于20180509