Python药店销售数据分析
分析目标:根据药店销售数据,分析药品销售关键指标,以及药品销售趋势
1. 导入并清理数据
import pandas as pd
# 以object形式输入数据可保持数据原始形状,之后可用astype()转换数据格式
sale_data=pd.read_excel('药店2018年销售数据.xlsx',0,dtype='object')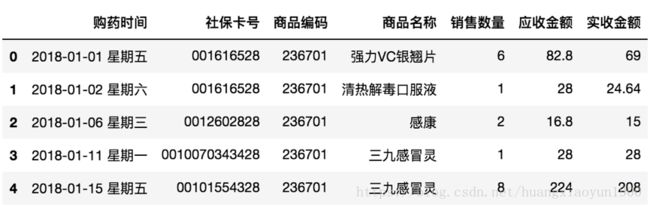
# 1. 列名重置:更改购药时间为销售时间
dfrename = {"购药时间":"销售时间"}
sale_data.rename(columns=dfrename,inplace=True)
# 2. 处理缺失值
# 查找缺失值
sale_data.isnull().sum()
# 删除缺失值
sale_df=sale_data.dropna(subset=['销售时间','社保卡号'],how='any',axis=0)
sale_df.shape
# 删除缺失值后需重设索引,加drop=True可将原索引删除,否则原索引将保存为列名为index的一列
sale_df=sale_df.reset_index(drop=True)
# 3. 提取数据并转换数据格式
# 将销售数量,应收金额,实收金额转换成浮点型
sale_df['销售数量']=sale_df['销售数量'].astype('float')
sale_df['应收金额']=sale_df['应收金额'].astype('float')
sale_df['实收金额']=sale_df['实收金额'].astype('float')
sale_df.dtypes
# 4. 处理日期数据
# 提取销售时间
date = pd.DataFrame(sale_df['销售时间'].apply(lambda s: s.split(" ")).values.tolist(),columns=['日期','星期'])
# 将日期的object类型转换成日期类型
# 加errors='coerce',如果原始数据不符合日期的格式,转换后的值为空值NaT
date['日期']=pd.to_datetime(date['日期'],format='%Y-%m-%d',errors='coerce')
sale_df1 = sale_df
sale_df1['销售日期']=date['日期']
sale_df1['销售星期']=date['星期']
# 转换日期格式时,不符合日期格式的会转换成空值,删除空值行
sale_df1 = sale_df1.dropna(subset=['销售日期'],how='any')
# 重置index
sale_df1=sale_df1.reset_index(drop=True)
# 5. 按日期排序
sale_df1=sale_df1.sort_values(by='销售日期',ascending=True)
# 重置index
sale_df1=sale_df1.reset_index(drop=True)
# 6.异常值处理
# 查看有无异常值
sale_df1.describe()
# “销售数量“,”金额“ 最小值不能低于0
print("删除异常值前:",sale_df1.shape)
querySer = sale_df1.loc[:,'销售数量']>0
sale_df2 = sale_df1.loc[querySer,:]
print("删除异常值后:",sale_df2.shape)2. 分析数据
a. 计算关键指标:每月平均消费次数,每月平均消费金额,客单价
'''
业务指标1:月均消费次数=每月消费次数平均值
条件:同一人同一天发生的所有消费视作一次
方法:”销售日期“和”社保卡号“若同时相同,则只保留一项计数
'''
kpi1 = sale_df2.drop_duplicates(subset=['销售日期','社保卡号'])
# 按时间顺序排序
kpi1 = kpi1.sort_values(by='销售日期',ascending=True)
# 重置索引
kpi1=kpi1.reset_index(drop=True)
kpi1.shape
kpi1['消费次数']=1
kpi = kpi1
kpi.index=kpi['销售日期']
# 用groupby统计每月消费数据
gb=kpi.groupby(kpi.index.month)
MonSales=gb.sum()
# 月均消费次数 kpi_1
kpi_1 = MonSales['消费次数'].loc[:6].mean()
# 月均销售金额 kpi_2
kpi_2 = MonSales['实收金额'].loc[:6].mean()
# 客单价 kpi_3
kpi_3 = MonSales['实收金额'].sum()/MonSales['消费次数'].sum()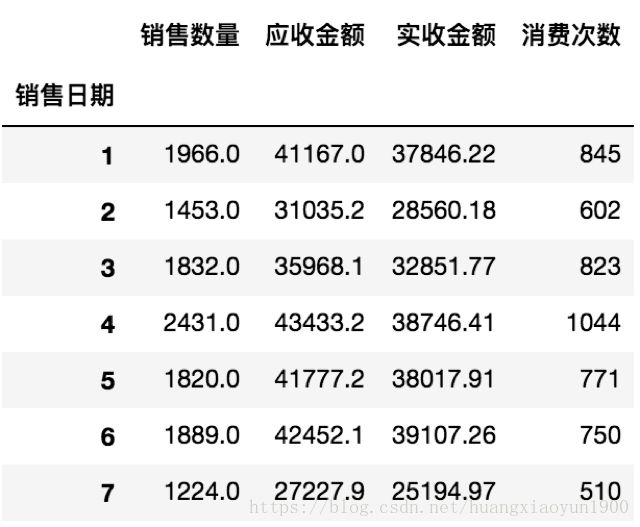
b. 比较各时段消费情况:
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
# 每月消费情况对比
f,ax1 = plt.subplots()
MonSales.plot(x=MonSales.index,y=['消费次数'],ax=ax1)
MonSales.plot(x=MonSales.index,y=['实收金额'],ax=ax1,secondary_y=True)
# 星期数据处理
kpi2 = kpi1
gb2 = kpi2.groupby(by='销售星期')
WeekSales=gb2.sum()
WeekSales.index=[1,3,2,5,6,4,7]
WeekSales.sort_index(inplace = True)
# 星期消费情况对比
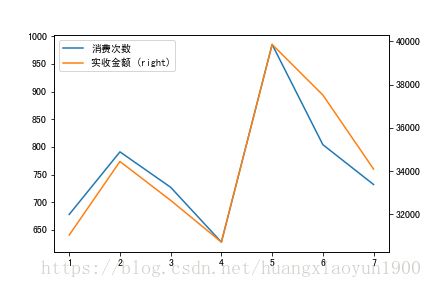
f,ax2 = plt.subplots()
WeekSales.plot(x=WeekSales.index,y='消费次数',ax=ax2)
WeekSales.plot(x=WeekSales.index,y='实收金额',ax=ax2,secondary_y=True)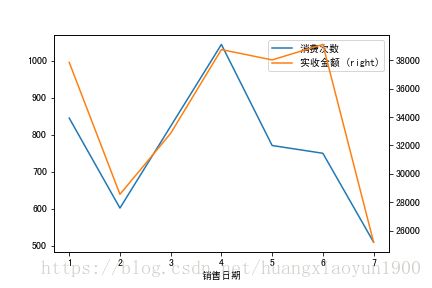
由上图可知:
1. 在月份销售对比中,2月药店销售金额较其他月有明显的下降(7月数据只到7月19日,故不做整体比较),4,5,6月药店销售金额均在38000以上。
2. 在月份销售对比中,4月消费次数最多,但实收金额并不是最高,说明客单次消费相比6月较低。
3. 在星期销售对比中,消费次数和消费金额总体趋势一致,周五为全星期消费次数和消费金额之最,周六次之。周四则消费最少。
c. 销售药品统计
帕累托图
# 根据销售商品名称groupby,排序销售数量,选出Top10
gb3 = pd.DataFrame(sale_df2.groupby(['商品名称']).sum()['销售数量'])
SaleQuantity=gb3.sort_values(by='销售数量',ascending=False)
TotalSales=SaleQuantity['销售数量'].sum()
# 计算百分比
SaleQuantity['Percentage']=SaleQuantity['销售数量']/TotalSales
SaleQuantity['AcmPerc'] = -1
# 计算累计百分比
for i in range(len(SaleQuantity.index)):
if i == 0:
SaleQuantity['AcmPerc'].iloc[0]=SaleQuantity['Percentage'].iloc[0]
else:
SaleQuantity['AcmPerc'].iloc[i]=SaleQuantity['Percentage'].iloc[i]+SaleQuantity['AcmPerc'].iloc[i-1]
Top_Sales=SaleQuantity[:10]
f,ax3=plt.subplots()
Top_Sales.plot(x=Top_Sales.index,y='销售数量',ax=ax3,kind='bar',title='销售前十',grid=True,rot=70)
ax4 = ax3.twinx()
Top_Sales.plot(x=Top_Sales.index,y='AcmPerc',kind='line',ax=ax4,secondary_y=True,marker='o',rot=70)
for a,b in zip(range(10),Top_Sales['AcmPerc']):
plt.text(a,b,'%.2f%%'%(b*100),ha='center',va='bottom')
ax3.legend(loc='upper center')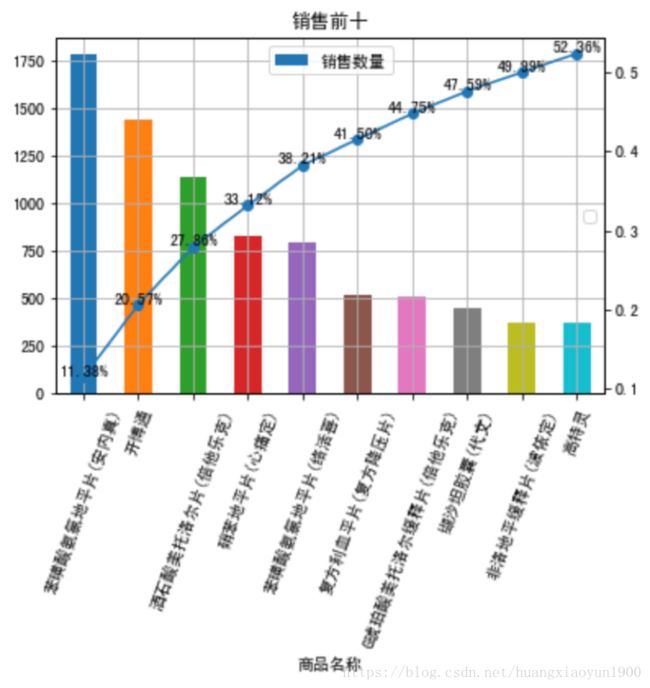
销售前十的药品如上图所示,且销售前十的药品销售数量占总销售数量的52%。
针对以上数据,还有很多可分析的内容,例如,是否有某药品集中在某一时期被购买的情况,哪些药品通常会被大规模购买,哪些药品在近一年内销售非常少可以适当减少采购量,需根据具体需求具体分析,在此就不再赘述。