解决Spark窗口统计函数rank()、row_number()、percent_rank()的OOM问题
目录
1. 窗口函数功能介绍
一个简单的例子
一个复杂的例子
2.数据量过大时的OOM问题
问题及原因
解决方法1:用SQL处理
解决方法2:转为rdd进行处理
解决方法3:将数据量过多的分组进行随机打散,从而近似排序
1. 窗口函数功能介绍
在利用Spark SQL按分组统计每个组内topN,或者相对某个指标归一化到[0,1]区间上时,可以使用spark的窗口函数:
(1) rank: 分数相同的行,排序编号也一致。当有2行数据排序并列第一时,它们的编号都是1,排第三的编号是3
(2) dense_rank:分数相同的行,排序编号也一致。当有2行数据排序并列第一时,它们的编号都是1,排第三的编号是2
(3) row_number: 每一行的编号唯一,当有2行数据相同时,随机分配编号
(4) percent_rank:结果可以视作为rank()的结果,除以最大的编号
一个简单的例子
package high_quality._history
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
object test {
def main(args: Array[String]) {
val spark = SparkSession.builder().master("local[2]").appName("test").config("spark.hadoop.validateOutputSpecs", "false").getOrCreate()
import spark.implicits._
Seq("22", "27", "37", "47", "57")
.toDF("x1")
.withColumn("x2", percent_rank().over(Window.orderBy($"x1"))).show()
}
}
结果为:

一个复杂的例子
假设有数据如下表(例子转自https://blog.csdn.net/kwame211/article/details/81325261):
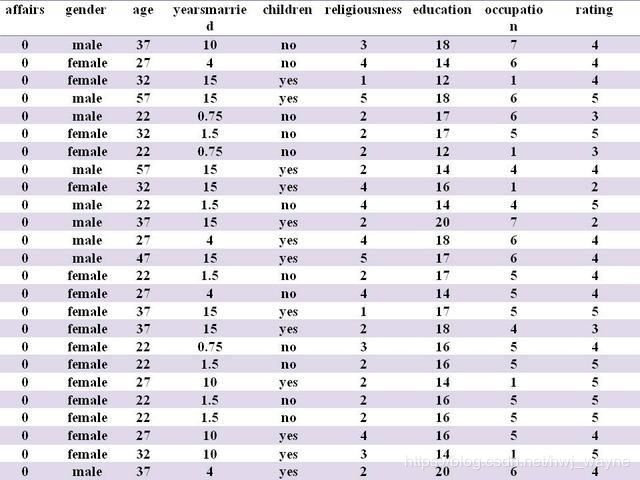
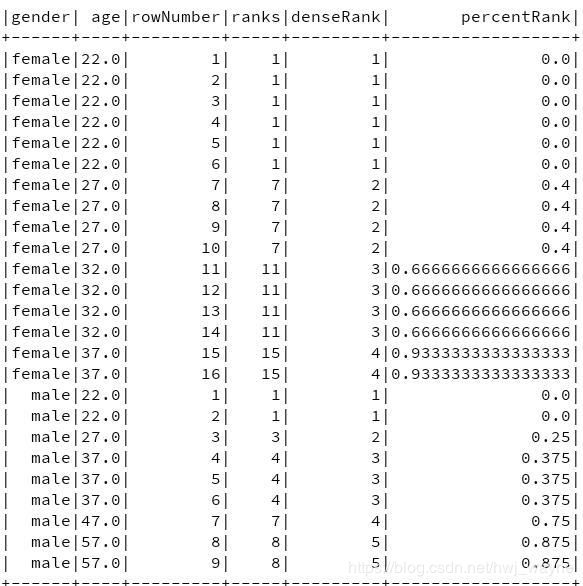
执行以下代码:

结果如图:
2.数据量过大时的OOM问题
问题及原因
以上提及的排序函数在数据量过大时将会导致spark任务失败,据本人经验而言数据量超过100w时失败概率较大。具体原因是因为在窗口函数中指定partitionBy(key)时,会把同一个key的数据放到单个节点上进行计算,不指定key时会把全部数据放到单个节点,当单个节点数据量过大时就会造成OOM问题。
为解决这个问题,有3种解决方案(此处针对row_number作为例子,其余三个函数大家可以灵活变通)。先举个例子:假设已经有一个用户分数表,字段为 user_id,group,score。一共有50个group,每个group有50w~5亿条数据不等,目标是要求每个分组下的用户排名。
解决方法1:用SQL处理
先将数据保存到SQL表中,然后利用SQL的排序函数得到排序编号。SQL的排序函数能处理上亿级的数据。
SELECT *, ROW_NUMBER() OVER(PARTITION by group order by score desc) user_rank
FROM tmp_table
解决方法2:转为rdd进行处理
RDD的orderBy函数能处理几十亿的数据量,可以借助这个函数实现分组排序。具体思路是:
(1)先把数据转为rdd
(2)根据key * k + value进行排序, 确保最小的key * k能大于最大的value,这样就能实现key相同的数据排序是连续的,且同key内value是从小到大排序的。
(3)利用zipWithIndex为排序结果增加序号
(4)通过groupBy(key)求min来计算每个key的offset,原序号减去offset就是每个value在当前key的排序序号了。
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
object test {
case class data_schema(user_id: String, group: Int, score: Double, rank: Int)
def main(args: Array[String]) {
val spark = SparkSession.builder().master("local[2]").appName("test").config("spark.hadoop.validateOutputSpecs", "false").getOrCreate()
import spark.implicits._
val data = Seq(("22", "27", "37")).toDF("user_id","group","score")
// data的结构是user_id,group,score
val rank = data.rdd
.map(x => x.mkString("_")) // 将数据合并为一行
.keyBy(x => x.split("_")(1).toDouble * 1000000 + x.split("_")(2).toDouble) // 制造排序指标,通过放大group来实现分组排序,同一个group的数据排序编号将会连续
.sortByKey() // 根据key排序
.zipWithIndex() // 增加index
.map(x => data_schema( // 将数据转换回dataframe格式
x._1._2.split("_")(0), x._1._2.split("_")(1).toInt,
x._1._2.split("_")(2).toDouble, x._2.toInt))
.toDF()
rank.persist()
val group_max = rank // 计算每个group的basic,用于把每个分组的最小编号调整为1
.groupBy("group")
.agg(min("rank") as "group_basic")
val final_rank = rank
.join(group_max,Seq("group"))
.withColumn("rank",$"rank"-$"group_basic"+1)
}
解决方法3:将数据量过多的分组进行随机打散,从而近似排序
根据前面分析的问题原因,若key的数据量超过指定阈值,如100w,那么可以把这个key进行随机打散,具体实现方式为额外增加一个随机值作为辅助key。针对所举的例子,当一个组有5亿用户,而分组函数只支持100w数据排序时,可以把这个5亿个用户随机划分为500个小组,每个小组单独进行排序,最后再将每个组的结果进行合并例如第一个组的第一名最终序号是1,第三组第一名最终序号是3,第五组第十名的最终序号是(10-1)*500+5。这种排序方法得到的结果并不是100%准确的,但是总体上的数据分布与真实情况不会有太大差异。
对数据进行分小组(打散)的思路就是:
(1)先将数据缓存起来
(2)计算每个key下的数据量,然后计算每个key要分多少组
(3)为每条数据增加一个[1,n]的随机整数,其中n为这个key要划分的组数,作为rand_key
(4)在执行窗口函数时,partitionBy()把rand_key也加进去
例子:
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object test {
def main(args: Array[String]) {
val spark = SparkSession.builder().master("local[*]").getOrCreate()
import spark.implicits._
val data = Seq(("22", "27", "37")).toDF("user_id", "group", "score") // 构造一个DF
val subgroup_size = 1000000 // 每个key大小的限制
val subgroup_info = data
.groupBy("group")
.agg(count(lit(1)) as "group_cnt") // 计算每个key的数据量
.withColumn("subgroup_amount", ($"group_cnt" / subgroup_size + 1).cast(IntegerType)) // 计算每个key要分多少组
val rank = data
.join(subgroup_info, Seq("group"))
.withColumn("rand_key", (rand() * 1000000 % $"subgroup_amount").cast(IntegerType)) // 赋予分组id
.withColumn("rank", row_number().over(Window.partitionBy("group", "rand_key").orderBy($"score"))) // 在小组内排序
.withColumn("rank", ($"rank" - 1) * $"subgroup_amount" + $"rand_key") // 整合个组的排序结果
.select("user_id", "group", "rank")
}
}