Leetcode高频 SQL 50 题(基础版)(二)
一、员工奖金
表:Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | empId | int | | name | varchar | | supervisor | int | | salary | int | +-------------+---------+ empId 是该表中具有唯一值的列。 该表的每一行都表示员工的姓名和 id,以及他们的工资和经理的 id。
表:Bonus
+-------------+------+ | Column Name | Type | +-------------+------+ | empId | int | | bonus | int | +-------------+------+ empId 是该表具有唯一值的列。 empId 是 Employee 表中 empId 的外键(reference 列)。 该表的每一行都包含一个员工的 id 和他们各自的奖金。
编写解决方案,报告每个奖金 少于 1000 的员工的姓名和奖金数额。以 任意顺序 返回结果表。
结果格式如下所示:
示例 1:
输入: Employee table: +-------+--------+------------+--------+ | empId | name | supervisor | salary | +-------+--------+------------+--------+ | 3 | Brad | null | 4000 | | 1 | John | 3 | 1000 | | 2 | Dan | 3 | 2000 | | 4 | Thomas | 3 | 4000 | +-------+--------+------------+--------+ Bonus table: +-------+-------+ | empId | bonus | +-------+-------+ | 2 | 500 | | 4 | 2000 | +-------+-------+ 输出: +------+-------+ | name | bonus | +------+-------+ | Brad | null | | John | null | | Dan | 500 | +------+-------+
sql:
SELECT
name,bonus
FROM
Employee e LEFT JOIN Bonus b
ON
e.empId = b.empId
WHERE
bonus < 1000 OR bonus IS NULL;
注释:在进行左连接时,对于 Bonus 表中没有的 empId 在 Employee 表中会用 NULL 代替。所以再通过 bonus < 1000 OR bonus IS NULL 即可查询题目所给要求。
二、学生们参加各科测试的次数
学生表: Students
+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 在 SQL 中,主键为 student_id(学生ID)。 该表内的每一行都记录有学校一名学生的信息。
科目表: Subjects
+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 在 SQL 中,主键为 subject_name(科目名称)。 每一行记录学校的一门科目名称。
考试表: Examinations
+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这个表可能包含重复数据(换句话说,在 SQL 中,这个表没有主键)。 学生表里的一个学生修读科目表里的每一门科目。 这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。
查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示。
示例 1:
输入: Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ 输出: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 解释: 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。
sql:
SELECT
s.student_id,
s.student_name,
sub.subject_name,
COUNT(e.subject_name) AS attended_exams
FROM
Students s
JOIN
Subjects sub
LEFT JOIN
Examinations e
ON
s.student_id = e.student_id AND sub.subject_name = e.subject_name
GROUP BY
s.student_id, s.student_name, sub.subject_name
ORDER BY
s.student_id, sub.subject_name;
注释:连接 Students 和 Subjects 表并通过 ORDER BY 排序,展示所有的学生和科目的组合:
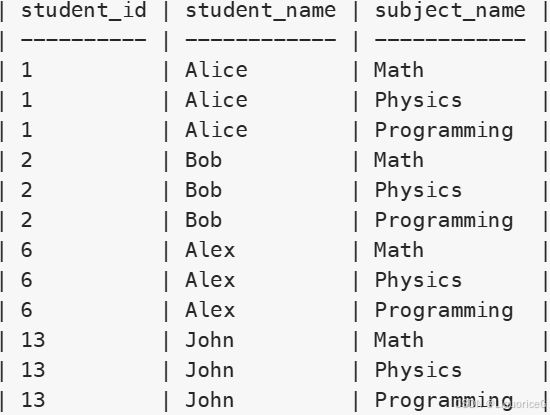
然后通过 LEFT JOIN Examinations 表得到每个学生在每个科目上的考试次数。如果某个学生没有参加某一科目的考试,那么对应的 e.subject_name 会是NULL。
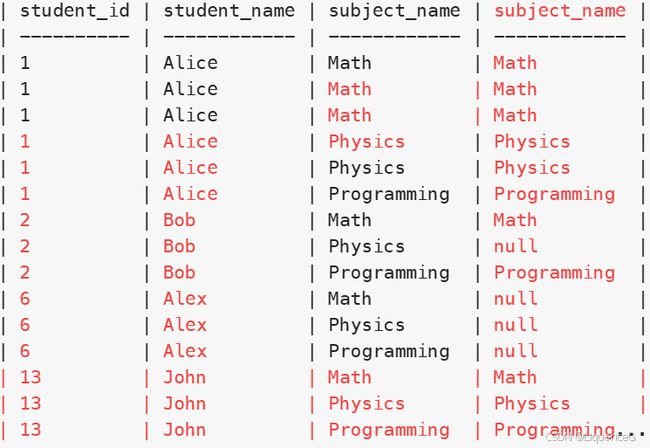
最后用 COUNT 进行统计并使用 ORDER BY 进行分组即可求得所求。
三、至少有5名直接下属的经理
表: Employee
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | | department | varchar | | managerId | int | +-------------+---------+ id 是此表的主键(具有唯一值的列)。 该表的每一行表示雇员的名字、他们的部门和他们的经理的id。 如果managerId为空,则该员工没有经理。 没有员工会成为自己的管理者。
编写一个解决方案,找出至少有五个直接下属的经理。以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入: Employee 表: +-----+-------+------------+-----------+ | id | name | department | managerId | +-----+-------+------------+-----------+ | 101 | John | A | Null | | 102 | Dan | A | 101 | | 103 | James | A | 101 | | 104 | Amy | A | 101 | | 105 | Anne | A | 101 | | 106 | Ron | B | 101 | +-----+-------+------------+-----------+ 输出: +------+ | name | +------+ | John | +------+
sql:
SELECT
m.name
FROM
Employee e
JOIN
Employee m ON e.managerId = m.id
GROUP BY
m.id
HAVING
COUNT(e.id) >= 5;
注释:通过自连接按照 Employee id 分组找出有下属的经理,再通过使用 HAVING 子句筛选出符合条件的经理。
四、确认率
表: Signups
+----------------+----------+ | Column Name | Type | +----------------+----------+ | user_id | int | | time_stamp | datetime | +----------------+----------+ User_id是该表的主键。每一行都包含ID为user_id的用户的注册时间信息。
表: Confirmations
+----------------+----------+
| Column Name | Type |
+----------------+----------+
| user_id | int |
| time_stamp | datetime |
| action | ENUM |
+----------------+----------+
(user_id, time_stamp)是该表的主键。
user_id 是一个引用到注册表的外键。
action 是类型为('confirmed', 'timeout')的ENUM。
该表的每一行都表示ID为user_id的用户在time_stamp请求了一条确认消息,该确认消息要么被确认('confirmed'),要么被过期('timeout')。
用户的 确认率 是 'confirmed' 消息的数量除以请求的确认消息的总数。没有请求任何确认消息的用户的确认率为 0 。确认率四舍五入到 小数点后两位 。
编写一个SQL查询来查找每个用户的 确认率 。以 任意顺序 返回结果表。
查询结果格式如下所示。
示例1:
输入: Signups 表: +---------+---------------------+ | user_id | time_stamp | +---------+---------------------+ | 3 | 2020-03-21 10:16:13 | | 7 | 2020-01-04 13:57:59 | | 2 | 2020-07-29 23:09:44 | | 6 | 2020-12-09 10:39:37 | +---------+---------------------+ Confirmations 表: +---------+---------------------+-----------+ | user_id | time_stamp | action | +---------+---------------------+-----------+ | 3 | 2021-01-06 03:30:46 | timeout | | 3 | 2021-07-14 14:00:00 | timeout | | 7 | 2021-06-12 11:57:29 | confirmed | | 7 | 2021-06-13 12:58:28 | confirmed | | 7 | 2021-06-14 13:59:27 | confirmed | | 2 | 2021-01-22 00:00:00 | confirmed | | 2 | 2021-02-28 23:59:59 | timeout | +---------+---------------------+-----------+ 输出: +---------+-------------------+ | user_id | confirmation_rate | +---------+-------------------+ | 6 | 0.00 | | 3 | 0.00 | | 7 | 1.00 | | 2 | 0.50 | +---------+-------------------+ 解释: 用户 6 没有请求任何确认消息。确认率为 0。 用户 3 进行了 2 次请求,都超时了。确认率为 0。 用户 7 提出了 3 个请求,所有请求都得到了确认。确认率为 1。 用户 2 做了 2 个请求,其中一个被确认,另一个超时。确认率为 1 / 2 = 0.5。
sql:
SELECT
Signups.user_id,ROUND(AVG(IF(Confirmations.action = 'confirmed',1,0)),2) confirmation_rate
FROM
Signups
LEFT JOIN
Confirmations
ON
Signups.user_id=Confirmations.user_id
GROUP BY
Signups.user_id;
注释:求比率问题可以用函数 AVG + IF (或者使用函数AVG + CASE WHEN) 解决。当 action = 'confirmed' 时,计为1;其它情况会被记为0,此时再通过 AVG 函数与 GROUP BY 分组就可以求得每个 id 在 action = 'confirmed' 时占取得比例。
五、有趣的电影
表:cinema
+----------------+----------+ | Column Name | Type | +----------------+----------+ | id | int | | movie | varchar | | description | varchar | | rating | float | +----------------+----------+ id 是该表的主键(具有唯一值的列)。 每行包含有关电影名称、类型和评级的信息。 评级为 [0,10] 范围内的小数点后 2 位浮点数。
编写解决方案,找出所有影片描述为 非 boring (不无聊) 的并且 id 为奇数 的影片。
返回结果按 rating 降序排列。结果格式如下示例。
示例 1:
输入: +---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 1 | War | great 3D | 8.9 | | 2 | Science | fiction | 8.5 | | 3 | irish | boring | 6.2 | | 4 | Ice song | Fantacy | 8.6 | | 5 | House card| Interesting| 9.1 | +---------+-----------+--------------+-----------+ 输出: +---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 5 | House card| Interesting| 9.1 | | 1 | War | great 3D | 8.9 | +---------+-----------+--------------+-----------+ 解释: 我们有三部电影,它们的 id 是奇数:1、3 和 5。id = 3 的电影是 boring 的,所以我们不把它包括在答案中。
sql:
SELECT
id,movie,description,rating
FROM
cinema
WHERE
description <> 'boring' AND id % 2 = 1
ORDER BY
rating DESC;
注释:降序关键词为 DESC,此题 id % 2 = 1 部分还有一种巧妙的解法,即 id & 1。当 id 为偶数时,进行运算结果都为0,所以也可以排除掉 id 为偶数的情况。
六、平均售价
表:Prices
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | start_date | date | | end_date | date | | price | int | +---------------+---------+ (product_id,start_date,end_date) 是prices表的主键(具有唯一值的列的组合)。 prices表的每一行表示的是某个产品在一段时期内的价格。 每个产品的对应时间段是不会重叠的,这也意味着同一个产品的价格时段不会出现交叉。
表:UnitsSold
+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | purchase_date | date | | units | int | +---------------+---------+ 该表可能包含重复数据。 该表的每一行表示的是每种产品的出售日期,单位和产品 id。
编写解决方案以查找每种产品的平均售价。average_price 应该 四舍五入到小数点后两位。如果产品没有任何售出,则假设其平均售价为 0。返回结果表 无顺序要求 。
结果格式如下例所示。
示例 1:
输入: Prices table: +------------+------------+------------+--------+ | product_id | start_date | end_date | price | +------------+------------+------------+--------+ | 1 | 2019-02-17 | 2019-02-28 | 5 | | 1 | 2019-03-01 | 2019-03-22 | 20 | | 2 | 2019-02-01 | 2019-02-20 | 15 | | 2 | 2019-02-21 | 2019-03-31 | 30 | +------------+------------+------------+--------+ UnitsSold table: +------------+---------------+-------+ | product_id | purchase_date | units | +------------+---------------+-------+ | 1 | 2019-02-25 | 100 | | 1 | 2019-03-01 | 15 | | 2 | 2019-02-10 | 200 | | 2 | 2019-03-22 | 30 | +------------+---------------+-------+ 输出: +------------+---------------+ | product_id | average_price | +------------+---------------+ | 1 | 6.96 | | 2 | 16.96 | +------------+---------------+ 解释: 平均售价 = 产品总价 / 销售的产品数量。 产品 1 的平均售价 = ((100 * 5)+(15 * 20) )/ 115 = 6.96 产品 2 的平均售价 = ((200 * 15)+(30 * 30) )/ 230 = 16.96
sql:
SELECT
p.product_id,
IFNULL(ROUND(SUM(p.price * u.units) / SUM(u.units), 2), 0) AS average_price
FROM
prices p
LEFT JOIN
unitssold u
ON
p.product_id = u.product_id
AND u.purchase_date BETWEEN p.start_date AND p.end_date
GROUP BY
p.product_id;
注释:通过左连接获取所需的列然后通过 BETWEEN AND 关键字选取在指定时间范围的purchase_date。得到结果如下:

然后通过 ROUND、SUM 函数对产品的平均售价进行计算。因为可能没有销量为空的情况。所以还要通过 IFNULL 关键字将为空的替换为0进行计算。最后通过 GROUP BY 分组即可求得答案。
七、项目员工I
项目表 Project:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | project_id | int | | employee_id | int | +-------------+---------+ 主键为 (project_id, employee_id)。 employee_id 是员工表 ,Employee 表的外键。 这张表的每一行表示 employee_id 的员工正在 project_id 的项目上工作。
员工表 Employee:
+------------------+---------+ | Column Name | Type | +------------------+---------+ | employee_id | int | | name | varchar | | experience_years | int | +------------------+---------+ 主键是 employee_id。数据保证 experience_years 非空。 这张表的每一行包含一个员工的信息。
请写一个 SQL 语句,查询每一个项目中员工的 平均 工作年限,精确到小数点后两位。
以 任意 顺序返回结果表。查询结果的格式如下。
示例 1:
输入: Project 表: +-------------+-------------+ | project_id | employee_id | +-------------+-------------+ | 1 | 1 | | 1 | 2 | | 1 | 3 | | 2 | 1 | | 2 | 4 | +-------------+-------------+ Employee 表: +-------------+--------+------------------+ | employee_id | name | experience_years | +-------------+--------+------------------+ | 1 | Khaled | 3 | | 2 | Ali | 2 | | 3 | John | 1 | | 4 | Doe | 2 | +-------------+--------+------------------+ 输出: +-------------+---------------+ | project_id | average_years | +-------------+---------------+ | 1 | 2.00 | | 2 | 2.50 | +-------------+---------------+ 解释:第一个项目中,员工的平均工作年限是 (3 + 2 + 1) / 3 = 2.00;第二个项目中,员工的平均工作年限是 (3 + 2) / 2 = 2.50
sql:
SELECT
p.project_id,ROUND(AVG(experience_years),2) AS average_years
FROM
Project p
LEFT JOIN
Employee e
ON
p.employee_id = e.employee_id
GROUP BY
p.project_id
注释:通过左连接获取需要的列,然后通过 GROUP BY 对 project_id 进行分组。最后通过 AVG 求平均值以及 ROUND 进行四舍五入。
八、各赛事的用户注册率
用户表: Users
+-------------+---------+ | Column Name | Type | +-------------+---------+ | user_id | int | | user_name | varchar | +-------------+---------+ user_id 是该表的主键(具有唯一值的列)。 该表中的每行包括用户 ID 和用户名。
注册表: Register
+-------------+---------+ | Column Name | Type | +-------------+---------+ | contest_id | int | | user_id | int | +-------------+---------+ (contest_id, user_id) 是该表的主键(具有唯一值的列的组合)。 该表中的每行包含用户的 ID 和他们注册的赛事。
编写解决方案统计出各赛事的用户注册百分率,保留两位小数。
返回的结果表按 percentage 的 降序 排序,若相同则按 contest_id 的 升序 排序。
返回结果如下示例所示。
示例 1:
输入: Users表: +---------+-----------+ | user_id | user_name | +---------+-----------+ | 6 | Alice | | 2 | Bob | | 7 | Alex | +---------+-----------+
Register表: +------------+---------+ | contest_id | user_id | +------------+---------+ | 215 | 6 | | 209 | 2 | | 208 | 2 | | 210 | 6 | | 208 | 6 | | 209 | 7 | | 209 | 6 | | 215 | 7 | | 208 | 7 | | 210 | 2 | | 207 | 2 | | 210 | 7 | +------------+---------+ 输出: +------------+------------+ | contest_id | percentage | +------------+------------+ | 208 | 100.0 | | 209 | 100.0 | | 210 | 100.0 | | 215 | 66.67 | | 207 | 33.33 | +------------+------------+ 解释: 所有用户都注册了 208、209 和 210 赛事,因此这些赛事的注册率为 100% ,我们按 contest_id 的降序排序加入结果表中。 Alice 和 Alex 注册了 215 赛事,注册率为 ((2/3) * 100) = 66.67% Bob 注册了 207 赛事,注册率为 ((1/3) * 100) = 33.33%
sql:
SELECT
r.contest_id,
ROUND(COUNT(DISTINCT r.user_id) * 100.0 / (SELECT COUNT(user_id) FROM Users), 2) AS percentage
FROM
Register r
GROUP BY
r.contest_id
ORDER BY
percentage DESC,
r.contest_id;
注释:首先从 Register 表中读取数据分组:

SELECT COUNT(user_id) FROM Users 用于获取不同用户人数,对 r.contest_id 进行分组后采用 DISTINCT r.user_id 对每一个比赛类型获取注册的不同的用户人数。将两者相除再通过四舍五入就得到题目所求的用户注册率。
九、查询结果的质量和占比
Queries 表:
+-------------+---------+ | Column Name | Type | +-------------+---------+ | query_name | varchar | | result | varchar | | position | int | | rating | int | +-------------+---------+ 此表可能有重复的行。 此表包含了一些从数据库中收集的查询信息。 “位置”(position)列的值为 1 到 500 。 “评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 定义为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写解决方案,找出每次的 query_name 、 quality 和 poor_query_percentage。
quality 和 poor_query_percentage 都应 四舍五入到小数点后两位 。
以 任意顺序 返回结果表。
结果格式如下所示:
示例 1:
输入: Queries table: +------------+-------------------+----------+--------+ | query_name | result | position | rating | +------------+-------------------+----------+--------+ | Dog | Golden Retriever | 1 | 5 | | Dog | German Shepherd | 2 | 5 | | Dog | Mule | 200 | 1 | | Cat | Shirazi | 5 | 2 | | Cat | Siamese | 3 | 3 | | Cat | Sphynx | 7 | 4 | +------------+-------------------+----------+--------+ 输出: +------------+---------+-----------------------+ | query_name | quality | poor_query_percentage | +------------+---------+-----------------------+ | Dog | 2.50 | 33.33 | | Cat | 0.66 | 33.33 | +------------+---------+-----------------------+ 解释: Dog 查询结果的质量为 ((5 / 1) + (5 / 2) + (1 / 200)) / 3 = 2.50 Dog 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33 Cat 查询结果的质量为 ((2 / 5) + (3 / 3) + (4 / 7)) / 3 = 0.66 Cat 查询结果的劣质查询百分比为 (1 / 3) * 100 = 33.33
sql:
SELECT
query_name,
ROUND(AVG(rating / position), 2) AS quality,
ROUND(AVG(IF(rating < 3, 1, 0)) * 100, 2) AS poor_query_percentage
FROM
Queries
GROUP BY
query_name;
注释:
计算 quality:每个查询结果的评分与其位置之间的比率的平均值 (AVG(rating / position))
计算 poor_query_percentage:评分小于 3 的查询结果占全部查询结果的百分比。同理,使用 AVG 与 IF 函数来计算比率。检查 rating 是否小于 3,如果是则返回 1,否则返回 0。然后计算这些值的平均值,四舍五入到小数点后两位。
十、每月交易1
表:Transactions
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | country | varchar | | state | enum | | amount | int | | trans_date | date | +---------------+---------+ id 是这个表的主键。 该表包含有关传入事务的信息。 state 列类型为 ["approved", "declined"] 之一。
编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:Transactions table: +------+---------+----------+--------+------------+ | id | country | state | amount | trans_date | +------+---------+----------+--------+------------+ | 121 | US | approved | 1000 | 2018-12-18 | | 122 | US | declined | 2000 | 2018-12-19 | | 123 | US | approved | 2000 | 2019-01-01 | | 124 | DE | approved | 2000 | 2019-01-07 | +------+---------+----------+--------+------------+ 输出:
| month | country | trans_count | approved_count | trans_total_amount | approved_total_amount |
|---|---|---|---|---|---|
| 2018-12 | US | 2 | 1 | 3000 | 1000 |
| 2019-01 | US | 1 | 1 | 2000 | 2000 |
| 2019-01 | DE | 1 | 1 | 2000 | 2000 |
sql:
SELECT
DATE_FORMAT(trans_date, '%Y-%m') AS month,
country,
COUNT(*) AS trans_count,
SUM(IF(state = 'approved', 1, 0)) AS approved_count,
SUM(amount) AS trans_total_amount,
SUM(IF(state = 'approved', amount, 0)) AS approved_total_amount
FROM
Transactions
GROUP BY
month,country;
注释:不是很难,但是需要计算的列很多。
计算 month:DATE_FORMAT(date, format) 用来转换日期格式。常见的格式化符如下:
| 格式化说明符 | 描述 | 示例 |
|---|---|---|
%Y |
四位数表示的年份 | 2023 |
%y |
两位数表示的年份 | 23 |
%m |
两位数表示的月份(01 到 12) | 07 |
%c |
月份(1 到 12),不带前导零 | 7 |
%d |
两位数表示的月份中的天数 | 05 |
%e |
月份中的天数(1 到 31),不带前导零 | 5 |
%H |
小时(00 到 23) | 14 |
%h |
小时(01 到 12) | 02 |
%i |
分钟(00 到 59) | 30 |
%s |
秒(00 到 59) | 45 |
计算 approved_count(当前年月批准的事务):使用 IF 将已批准变为1,未批准变为0再用 SUM 相加即可。
计算 approved_count(当前年月批准的金额):同样使用 IF 判断赋值再用 SUM 累加即可。