Golang中的defer关键字的用法、原理以及它的坑
延迟函数调用(deferred function call)是golang中很有特点的一个功能,通过defer修饰的函数调用会在函数退出的时候才被真正调用,它可以用来进行资源释放等收尾工作。
一个普通的函数调用被defer关键字修饰以后,就构成了一个延迟函数调用,和协程调用类似,被延迟的函数调用的所有返回值都会全部被舍弃。
延迟函数调用的用法
首先我们看看延迟函数调用的用法,它的用法其实很简单!
简单是示例代码:
func main(){
defer func() { fmt.Println("延迟调用") }()
fmt.Println("正常调用")
}
代码执行结果:
正常代码
延迟调用
从结果我们可以很直观的发现,被defer修饰的函数调用在后面执行了,也就是被延迟调用了。
多个延迟函数调用的执行顺序
上面的示例代码很简单,输出结果也很好理解,接下来我们看一个稍微复杂一丢丢的代码:
func main(){
defer func() { fmt.Println("延迟调用1") }()
defer func() { fmt.Println("延迟调用2") }()
fmt.Println("正常代码")
}
这段代码和之前的代码唯一的不同之处是多了一个被defer修饰的函数调用,那么这小段代码的输出又会是什么样的呢?
是先输出[延迟调用1]还是先输出[延迟调用2]呢?跑一下程序自然就知道啦!
代码执行结果:
正常代码
延迟调用2
延迟调用1
[延迟调用2]被先输出了,这是为什么呢?
这是因为每一个协程都会维护一个延迟调用堆栈,按照代码顺序把需要延迟调用的函数压入栈中,当函数进入退出阶段后,就会从延迟调用堆栈中取出需要执行的函数调用并执行。
延迟函数调用的实现原理
上面讲了基本的用法,接下来我们再深入到golang源码看看defer关键字是如何实现的。为了便于分析,我用下面的代码进行分析:
func main(){
defer func() {}()
defer func() {}()
}
然后执行如下命令看看这小段代码的执行过程:
GOSSAFUNC=main go build main.go
我们可以得到如下的ssa执行过程:
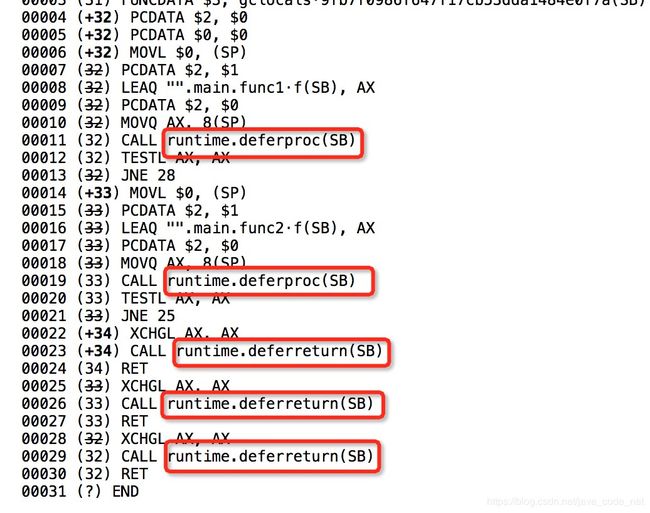
看不懂?没关系!会找关键信息就ok了!通过ssa执行过程我们可以发现defer命令被翻译成了runtime.deferproc命令,并且在退出阶段会调用runtime.deferreturn命令。
首先我们看看deferproc命令的源码:
func deferproc(siz int32, fn *funcval) {
gp := getg()
// ...
// ...
d := newdefer(siz)
// ...
// ...
}
func newdefer(siz int32) *_defer {
// ...
// ...
d = (*_defer)(mallocgc(total, deferType, true))
// ...
// ...
d.siz = siz
d.link = gp._defer
gp._defer = d
return d
}
上面的源码省略了一些细节,留下了主干。deferproc命令会创建一个_defer类型的数据,它实际上是一个链表类型,有一个字段link指向下一个_defer数据。在当前协程上会保存这个_defer链表的头部,每次创建defer的时候就会插入到协程_defer链表的头部,形成一个基于链表的堆栈。
然后我们再看看deferreturn命令的源码:
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
// ...
// ...
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
从上面的代码我们可以看出,当我们进入退出阶段,执行deferreturn命令的时候,会从当前协程的_defer链表中取出头部(前面介绍了是如何往里面存放数据的),并把下一个元素作为_defer链表的头部,然后再使用jmpdefer指令完成跳转调用,jmpdefer完全是使用汇编完成的了,并且各个平台实现的代码也不一样,这里就不再继续分析了。
上面两个部分分析了defer关键字的主要实现逻辑,从中我们可以知道如下的特定:
- 多个defer修饰的延迟调用函数是存放在堆栈中的,满足先进后出的调用规则。
- jmpdefer进行代码跳转并不是普通的函数调用,处于延迟调用堆栈中的任意两个调用之间也不存在调用关系
带参数的延迟函数调用
上面的示例介绍的延迟函数调用都是不带参数的,实际上延迟函数调用是可以带参数的。比如下面的代码,你们知道它的输出吗,知道为什么是这样的输出吗?
func main(){
for i := 0; i < 3; i++ {
defer fmt.Println(i)
}
defer fmt.Println()
for i := 0; i < 3; i++ {
defer func() {
fmt.Println(i)
}()
}
}
我们先跑一跑这段代码,看看它的的输出结果,然后再慢慢分析原因:
3
3
3
2
1
0
第一个for循环中的defer都是带参数的延迟调用,我们可以发现它会记录deferproc命令执行那一刻的变量值。第二个for循环是在延迟函数中使用变量,可以发现它使用的值是for循环完以后的值。
规则很简单,那么是怎么实现的呢?
细心的朋友会发现上面的defer关键字实现源码已经涉及到了这一块的内容。deferproc命令的第一个参数接收一个int32值,它保存了延迟函数的参数内存大小,如果延迟函数有参数,它就会大于0,如果延迟函数没有参数这个值就会为0。前面为了更加直观的分析延迟函数堆栈的逻辑,省略了部分代码,下面这段复制参数的代码也是在deferproc命令中实现的
func deferproc(siz int32, fn *funcval) {
// ...
// ...
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
// ...
// ...
switch siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
// ...
// ...
}
这段代码的作用就是把延迟函数的参数保存在defer对象中,在退出阶段使用jmpdefer进行调用的时候,会把这个参数再传给被调用的延迟函数。
通过上面的分析我们可以知道defer具有下面这些特点:
- 带参数的延迟调用,它的实参是在此调用被推入延迟调用堆栈的时候被估值的,而不是延迟函数被调用的时刻。
延迟函数使用中的坑
前面介绍了defer的基本用法和实现原理,下面我们再介绍以下它在平时使用过程中可能遇到的坑。
- 匿名返回值和命名返回值在延迟函数中使用的表现是不一样的
有时候我们希望在延迟调用函数中对返回值进行修改,这个时候我们就必须特别注意一个点了:延迟函数中对匿名返回值的修改有可能会不成功!
以下面的代码为例:
func test1()(k string){
defer func() {
k = "defer value"
}()
k = "normal value"
return
}
func test2()string{
k := "normal value"
defer func() {
k = "defer value"
}()
return k
}
func main(){
fmt.Println("test1 result: " + test1())
fmt.Println("test2 result: " + test2())
}
这段代码的执行结果是:
test1 result: defer value
test2 result: normal value
也就是说如果想要在延迟函数中修改返回值,就必须使用命名返回值,匿名返回值是无法在延迟函数中进行修改的!
这是为什么呢?
其实查看上面代码的ssa执行过程就能够很快的找到原因了,总结起来就是:
1、每一个函数都会有一个返回值表,这个表中会保存所有的返回值内容。
2、命名返回值会在进入函数的时候就在返回值表上初始化好相应的返回值,上面示例test1函数中使用的变量k实际上是返回值表中的变量。
3、匿名返回值在进入函数的时候不会初始化返回值表上的值,return的时候才会拷贝数据到返回值表中,上面示例test2函数中使用的变量k只是一个临时变量,并不是返回值表中的变量。
4、匿名返回值的情况,return时临时变量拷贝到返回值表发生在调用延迟函数之前,这就解释了为什么延迟函数中修改k的值并不能影响返回值。命名返回值的情况由于一直使用的都是返回值表中的变量k,所以延迟函数中可以修改返回值。
- 调用os.Exit时defer不会被执行
正常退出函数时,该函数中压入延迟调用栈的延迟函数会被调用。通过panic退出函数时,协程的延迟调用栈上的所有延迟调用函数都会被调用,除非某个延迟函数中调用了recover。os.Exit退出的话就不会执行任何延迟调用了,因为这个时候整个程序都退出了,所以没事不要直接调用os.Exit退出程序,这种操作可能导致各种收尾工作得不到执行。
- defer中使用闭包函数的时候,只有最后一次调用是被延迟执行的
有时候为了代码更加的简洁,我们会用defer来修饰连续的函数调用过程,这个时候需要特别注意,并不是这一串的函数调用都会被延迟执行的!
以如下代码为例:
func test() func(){
fmt.Println("1")
return func(){
fmt.Println("2")
}
}
func main(){
fmt.Println("a")
defer test()()
fmt.Println("b")
}
他的输出结果如下:
a
1
b
2
所以defer修饰的延迟函数如果存在连续调用的,一定要注意只有一次调用是延迟的!!!