【学习与理解】:CTPN算法
目录
算法的主要流程
网络结构分析
训练策略
附录链接
算法的主要流程

网络模型主要包括三个部分:卷积层、双向LSTM、全连接层
1、VGG16为base net提取特征,将conv5得到feature map输出
2、用3*3滑窗扫描上面得到的feature map,也即在conv5得到的特征上做3*3的滑动窗口:每个点结合周围3*3的区域得到一个长度为3*3*C的特征向量
具体实现如下图,每个点(feature mao)结合周围3*3的区域得到一个长度为3*3*C的特征向量
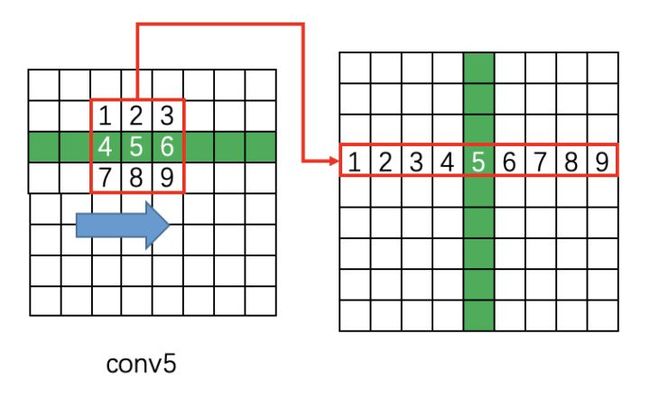
3、将特征reshape后,输入双向LSTM
CNN学习的是感受野内的空间信息,随着网络的深入,CNN学习到的特征会越来越抽象。对于文本序列检测问题,CNN得到的抽象空间特征,或者说文本本身具有一定的序列特征。
双向LSTM就是将2个方向相反的LSTM相连。

4-1、将Bi-LSTM的输出接入全连接层,作者采用的是三个全连接层分支
论文解析说明:引入了anchor的机制,即对每一个点用k个anchor进行预测,每个anchor就是一个盒子,其高度由[273,...,11]逐渐递减,每次除以0.7,总共有10个。
自己算了一下,得到[11, 16, 22, 32, 46, 65, 93, 134, 191, 273]
设置anchor的目的:
一方面保证在x的方向上,anchor可以覆盖每个点但是又不会互相覆盖;
另一方面,由于不同的文本在y方向上高度差距很大,所以设置10个不同的anchor高度,以保证覆盖不同高度的文本

第一个分支:2k个vertical coordinate(垂直坐标)。
因为一个anchor的纵坐标有两部分组成,分别是中心位置的高(y坐标)和矩形框的高度,所以一个用2k个输出。(注意这里输出的是相对anchor的偏移)
一个anchor的纵坐标有两个:中心位置的高(y坐标)和矩形框的高度
其中
 和
和 分别是预测的坐标和真实的坐标
分别是预测的坐标和真实的坐标
 和
和 分别是一个anchor的y坐标中心和高度
分别是一个anchor的y坐标中心和高度
 和
和 分别是预测出来的y坐标中心和高度
分别是预测出来的y坐标中心和高度
 和
和 分别是真实的y坐标中心和高度
分别是真实的y坐标中心和高度
第二个分支:2k个score
因为预测了k个text proposal,所以有2k个分数,text和non-text各有一个分数。(二分类问题,损失函数是softmax)
当分数>0.7,则认为anchor中包含文本
第三个分支:k个side-refinement
这部分主要是用来精修文本行的两个端点的,表示的是每个proposal的水平平移量
其中
 是预测出来的距离anchor水平坐标(左或右坐标)最近的坐标
是预测出来的距离anchor水平坐标(左或右坐标)最近的坐标
 是真实的x坐标
是真实的x坐标
 是anchor的x坐标中心
是anchor的x坐标中心
 是anchor的宽度,也就是16
是anchor的宽度,也就是16
4-2、tensotflow代码版本中
在FC后接入RPN网络(类似faster-rcnn),共有两个分支,获得text proposals
(左分子对应上面的分支一,右分支对应上面提到的分支二)
对于得到的anchor
左分支用bounding box regression修正文本的anchor的中心y坐标和高度
右分支用sotfmax来判断anchor是否包含文本,即选出score大的正anchor

具体回归方式见4-1的分析。
anchor经过softmax和y方向的bounding box regression处理后,会得到一组竖条纹的text proposals。

5、文本线构造算法,把分类得到的proposals(细长矩形,score>0.7)合并成为文本线,确定文本检测框
主要思想:每两个相近的proposal组成一个pair,合并不同的pair直到无法再合并(没有公共元素)
主要的步骤:
A、按水平x坐标排序Anchor
B、按规则计算每个Anchor boxi的pair(boxj),组成pair (boxi,boxj)
C、通过pair (boxi,boxj)建立Connect graph,最终获得文本检测框
判断两个proposal,Bi和Bj组成pair的条件
查看下面正向寻找和反向寻找的思想

固定regression的box的宽度和水平位置导致predict的box的水平位置不准确,所以作者引入side-refinement
文中给出了使用side-refinement(红色线)和不使用side-refinement(黄色线)的效果对比图
参考文献 ‘场景文本检测—CTPN原理与实现’ 里举了一个具体的例子,可以帮助理解。
这里附个截图


网络结构分析
网络参数解析(caffe)
输入:N*3*H*W
操作1:VGG16
| VGG16 |
卷积核个数 |
卷积核大小 |
Stride/pad |
| conv1_1+ReLU |
64 |
3*3 |
1 |
| conv1_2+ReLU |
64 |
3*3 |
1 |
| maxpool1 |
|
2*2 |
2 |
| conv2_1 |
128 |
3*3 |
1 |
| conv2_2 |
128 |
3*3 |
1 |
| maxpool2 |
|
2*2 |
2 |
| conv 3_1 |
256 |
3*3 |
1 |
| conv 3_2 |
256 |
3*3 |
1 |
| conv 3_3 |
256 |
3*3 |
1 |
| maxpool3 |
|
2*2 |
2 |
| conv 4_1 |
512 |
3*3 |
1 |
| conv 4_2 |
512 |
3*3 |
1 |
| conv 4_3 |
512 |
3*3 |
1 |
| maxpool4 |
|
2*2 |
2 |
| conv 5_1 |
512 |
|
|
| conv 5_2 |
512 |
|
|
| conv 5_3 |
512 |
|
|
说明:卷积层不改变输入矩阵大小,池化层将长宽变为1/2
输出:N *C *(H/16)*(W/16) = N*512*H*W
操作2:在conv5上做3*3的滑动窗口:每个点结合周围3*3的区域得到一个长度为3*3*C的特征向量
说明:原版caffe用im2col实现,tensorflow中用conv2d代替
输出:N*(3*3*C)*H*W
Reshape:(NH)*W*9C
操作3:以上输出的每一行(NH行)作为一个Tmax=W的数据流送入双向LSTM(隐层神经元128维),学习每一行的序列特征
说明:lstm_out = tf.reshape(lstm_out, [N * H * W, 2 * hidden_unit_num])
输出:(NH)*W *256
说明:outputs = tf.reshape(outputs, [N, H, W, output_channel])
操作4:连接512维的全连接层
输出:N *H*W*512
操作5:连接RPN网络(类似faster-rcnn)
输出:
左分支:N*20*H*W
右分支:N*20*H*W
训练策略
三个分支对应3部分损失函数,得到模型的损失函数

分析:
第一部分Anchor Softmax loss
用于监督学习每个Anchor中是否包含文本,表示是否是Groud truth
第二部分Anchor y coord regression loss
用于监督学习每个包含文本的Anchor的Bouding box regression y方向offset,类似于Smooth L1 loss
其中 Vj 是 Si 中判定为有文本的Anchor(score>0.7),或者与Groud truth vertical IoU>0.5
第三部分side-refinement
用于监督学习每个包含文本的Anchor的Bouding box regression x方向offset,与y方向同理
(这部分在tf版的代码里面并没有实现)
总结
缺点:
只能用于检测水平方向的文本,竖直方向上会出现字与字的断开,如果存在倾斜,需要修改处理anchor的连接方式;
训练的时候由于有regression和LSTM,需要小心控制梯度爆炸;
anchor的合并问题,何时合并,何时断开,这是一个问题。程序使用的是水平50个像素内合并,垂直IOU>0.7合并。或许由于BLSTM的引入,导致断开这个环节变差。所以对于双栏,三栏的这种文本,ctpn会都当做一个框处理,有时也会分开处理,总之不像EAST效果好。
附录链接
论文:Detecting Text in Natural Image with Connectionist Text Proposal Network
原论文开源代码:[code-caffe]
tensorlfow版代码:
1、 [code-tensorflow-eragonruan/text-detection-ctpn](在win下面运行会有坑)
2、 [code-tensorflow-Li-Ming-Fan/OCR-DETETION-CTPN]
参考博文:
ctpn解读(这篇博客里面附的一些资源有很好的参考)
论文阅读学习 - CTPN-Detecting Text in Natural Image with Connectionist Text Proposal Network(附有完整的网络结构)
CTPN项目部分代码学习(部分的代码解析,帮助理解)
CTPN文本检测与tensorflow实现(对Li-Fang-Ming的代码做了一些规整和改动)
代码2的解析
代码架构
Script_detect.py: 代码运行入口
|-- detect_meta.dir_images_train
|-- detect_data. get_files_with_ext
|-- detect_wrap.train_and_valid
| |-- create_graph_all
| | 调用model_detect_def.py
| | |-- def.conv_feat_layers
| | |-- def.rnn_detect_layers
| | |-- def.detect_loss
| |
validate
| | |-- create_graph_all
| | | 调用model_detect_def.py
| | | |-- def.conv_feat_layers
| | | 调用zoo_layers.py
| | | |--layers.conv_layer # 定义卷积层
| | | |--layers.padd_layer # padding层
| | | |--layers.maxpool_layer # 最大采样层
| | | |--ayers.block_resnet_others # 残差块
| | | |--def.rnn_detect_layers
| | | 调用zoo_layers
| | | |--layers.rnn_layer
| | | |-- def.detect_loss
| | 调用model_detect_data.py
| | |-- detect_data.get_target_txt_file
| | |-- detect_data.get_image_and_targets
| | | |-- detect_data.get_list_contents
| | | |-- detect_data.calculate_targets_at
| | |-- detect_data.trans_results
| | |-- detect_data.draw_text_boxes
| |
|-- detect_wrap.prepare_for_prediction
|-- detect_wrap .predict
| 调用model_detect_data.py
| |-- detect_data.trans_results
| |-- detect_data.do_nms_and_connection
| | |-- overlap
| |-- detect_data.draw_text_boxes
详细分析
|—Script_detect.py: 代码运行入口
| | # [读取数据并进行处理]
| |model_detect_meta.py # 存储数据路径及相关参数
| | |——meta.dir_images_train # 数据格式:角坐标(0-2是宽)|单词
| |model_detect_data.py # 数据处理和读取
| | |——model_data.get_files_with_ext
# 输入:文件路径和格式
# 返回:该路径下该格式的所有文件名列表
| | model_detect_wrap.py # 用于训练和验证
| | # [模型训练]
| | |——model.train_and_valid
# 输入:文件列表(训练和验证)
| | # [模型测试]
| | |——model.prepare_for_prediction
| | |——model.predic
# 输入:文件列表(测试)
|—model_detect_data.py :数据处理、读取等具体操作实现
| |——get_files_with_ext 读取数据
# 输入:文件路径和格式
# 输出file_list:该路径下该格式的所有文件名列表
| |——get_target_txt_file # 获取目标文本内容
# 输入img_file:单张图片的路径
# 输出txt_file:该图片对应的txt文件(存储每张图:角坐标|单词)路径
| |——get_image_and_targets # 得到文本框、目标框、三个分支的anchor
# 输入:img_file单张图片的路径、txt_file图片的对应txt路径、anchor_heights(12, 24, 36, 48) (anchor的宽度固定为8)
# 返回:[img_data] 图片本身的数据信息
[height_feat, width_feat] 图片大小
target_cls 是否包含文本的预测矩阵
target_ver anchor的中心y坐标和高度
target_hor anchor水平方向的信息,每个proposal的水平平移量
| | |——get_list_contents # 获取文本列表
# 输入txt_file:txt文件
# 输出txt_list双层列表,将txt里的内容按列表整理输出
hc = hc_start (18=12+6) + ash 12 * h(0,1,2,3)
wc = wc_start 4 + asw 8 * w(0~99)
| | |——calculate_targets_at # 对得到的txt_list每一个词计算anchor并挑出满足条件的
# 输入:[hc(高度中心), wc_start + asw * w(宽度中心)]、txt_list、anchor_heights(12, 24, 36, 48)
# 返回:cls, ver, hor (针对单张图片的每一个词判断,共48*100)
cls 是否包含文本的预测矩阵
ver anchor的中心y坐标和高度
hor anchor水平方向的信息,每个proposal的水平平移量
| |——trans_results # 得到最终的text proposals
输入:r_cls, r_ver, r_hor, (rnn_detect_layers输出),meta.anchor_heights, meta.threshold=0.5
返回:list_bbox(bbox坐标集合), list_conf(是否含文本)
| |——do_nms_and_connection # 文本线构造,选取水平距离<50,overlap>0.7的anchor
输入:list_bbox(bbox坐标集合), list_conf(是否含文本,没用到)
返回:合并bbox得到的文本线框坐标list
| | |——overlap # 计算overlap
| |——draw_text_boxes # 打开图片,根据文本内容和proposals完成画图
输入:目标图片,合并bbox得到的文本框坐标list
|—model_detect_wrap.py:用于训练和验证(加粗的是被调用到的)
| |——prepare_for_prediction # 加载模型参数文件,加载参数
| |——predict # 预测
返回:conn_bbox(合并bbox得到的文本线框坐标list), text_bbox(bbox坐标集合), conf_bbox(是否含文本)
| | | 调用model_detect_data.py
| | |——model_data.trans_results
输入:r_cls, r_ver, r_hor, (rnn层输出),meta.anchor_heights, meta.threshold=0.5
返回:list_bbox(bbox坐标集合), list_conf(是否含文本)
| | |——model_data.do_nms_and_connection
# 文本线构造(选取水平距离<50,overlap>0.7的anchor)
输入:list_bbox(bbox坐标集合), list_conf(是否含文本,没用到)
返回:conn_bbox合并bbox得到的文本线框坐标list
| | |——model_data.draw_text_boxes # 根据图片和文本框的坐标画出框线并保存
输入:目标图片,合并bbox得到的文本框坐标list
| |——create_graph_all # 完成网络的传参
| | | model_detect_def.py # 网络结构的搭建
| | |——model_def.conv_feat_layers # 定义VGG结构
self.conv_feat, self.seq_len = model_def.conv_feat_layers(self.x, self.w, self.is_train)
输入:inputs单张图片本身的信息, width目标图片的宽度, training
返回:经过类VGG网络处理之后的图片,处理之后图片的宽
| | |——model_def.rnn_detect_layers # 定义双向LSTM结构
self.rnn_cls, self.rnn_ver, self.rnn_hor = model_def.rnn_detect_layers(self.conv_feat, self.seq_len, len(meta.anchor_heights))
输入:上一步的返回值+anchor个数
返回:rnn_cls, rnn_ver, rnn_hor联合预测得到三个(100, 48, 8),reshape:(48, 100, 8)
| | |——model_def.detect_loss # 计算损失
self.loss = model_def.detect_loss(self.rnn_cls, self.rnn_ver, self.rnn_hor, self.t_cls, self.t_ver, self.t_hor)
输入:上一步rnn_detect_layers的三个返回值(预测输出)
+get_image_and_targets输出的三个self.t_cls, self.t_ver, self.t_hor(实际的anchor)
返回:整个的loss(关于loss的计算?)
# 优化器 AdamOptimizer
| |——train_and_valid # 训练和验证
| | |——create_graph_all # 完成网络的传参
| | |——validate # 先验证看是否需要早停,再训练
| | | 调用model_detect_data.py
| | |——model_data.get_target_txt_file
# 输入img_file:单张图片的路径
# 输出txt_file:该图片对应的txt文件(存储每张图:角坐标|单词)路径
| | |——model_data.get_image_and_targets
# 输入:img_file单张图片的路径、txt_file图片对应txt路径、anchor_heights(12, 24, 36, 48) (anchor的宽度固定为8)
hc = hc_start (18=12+6) + ash 12 * h(0,1,2,3)
wc = wc_start 4 + asw 8 * w(0~99)
# 返回:[img_data] 图片本身的数据信息
[height_feat, width_feat] 图片大小
target_cls 是否包含文本的预测矩阵
target_ver anchor的中心y坐标和高度
target_hor anchor水平方向的信息,每个proposal的水平平移量
得到的数据img_data、w_arr、target_cls、target_ver、target_hor喂给形参
| |——validate
# 训练和预测的合并,少了训练阶段对参数的更新(sess.run没有加入train_op)和预测阶段(do_nms_and_connection)对文本框线的构造
| | |——create_graph_all # 完成网络的传参
| | | 调用model_detect_data.py
| | |——model_data.get_target_txt_file
# 输入img_file:单张图片的路径
# 输出txt_file:该图片对应的txt文件(存储每张图:角坐标|单词)路径
| | |——model_data.get_image_and_targets
# 输入:img_file单张图片的路径、txt_file图片对应txt路径、anchor_heights(12, 24, 36, 48)(anchor的宽度固定为8)
hc = hc_start (18=12+6) + ash 12 * h(0,1,2,3)
wc = wc_start 4 + asw 8 * w(0~99)
# 返回:[img_data] 图片本身的数据信息
[height_feat, width_feat] 图片大小
target_cls 是否包含文本的预测矩阵
target_ver anchor的中心y坐标和高度
target_hor anchor水平方向的信息,每个proposal的水平平移量
| | |——model_data.trans_results
输入:rnn_detect_layers的三个返回值r_cls, r_ver, r_hor,meta.anchor_heights, meta.threshold=0.5
返回:list_bbox(bbox坐标集合), list_conf(是否含文本)
| | |——model_data.draw_text_boxes # 根据图片和文本框的坐标画出框线并保存
输入:目标图片,合并bbox得到的文本框坐标list
|—model_detect_def.py:网络结构的搭建
| | ——conv_feat_layers # 定义VGG结构
输入:inputs单张图片本身的信息, width目标图片的宽度, training
返回:经过类VGG网络处理之后的图片,处理之后图片的宽
c1 c2 p1 c3 c4 p2 c5 c6 p3 conv_feat
64 128 128 128 256 256 256 512 512 512
| | |调用zoo_layers.py
| | |——layers.conv_layer # 定义卷积层
| | |——layers.padd_layer # padding层
| | |——layers.maxpool_layer # 最大采样层
| | |——layers.block_resnet_others # 残差块
| |——rnn_detect_layers # 同时完成了模拟三个分支的结果生成
输入:上一步conv_feat_layers的返回值+anchor个数
返回:rnn_cls, rnn_ver, rnn_hor联合预测得到三个(100, 48, 8),reshape:(48, 100, 8)
| | |调用zoo_layers.py # 定义双向LSTM结构
| | |——layers.rnn_layer
| |——detect_loss # 计算损失
输入:上一步rnn_detect_layers的三个返回值(预测输出)+get_image_and_targets输出的三个self.t_cls, self.t_ver, self.t_hor(实际的anchor)
返回:整个的loss(关于loss的计算?)
|—zoo_layers.py:定义网络具体的结构块(加粗的是被调用到的)
| |——conv_layer # 卷积层
输入:输入图片4维信息[batch_size, width, height, channels],参数params,training
其中params = [filters, kernel_size, strides, padding, batch_norm, relu, name]
卷积核个数、尺寸、步长、padding(SAME和VALID)、BN、ReLU
| | |——norm_layer
| |——norm_layer # 归一化层
输入:输入图片4维信息[batch_size, width, height, channels], train, eps=1e-05, decay=0.9, affine=True, name=None
返回:归一化之后的数组
| |——padd_layer # padding层
tf.pad:输入tensor、设置填充大小、填充方式
| |——maxpool_layer # 最大采样层
tf.layers.max_pooling2d:tensor张量、池化窗大小、步长
| |——averpool_layer # 平均采样层
| |——block_resnet_others # 残差块
| |——block_resnet
| |——block_bottleneck # bottle块
| |——block_inception # 类似inception的块
| |——rnn_layer # 双向LSTM层
| |——gru_layer # 双向LSTM层
代码需要改进的点:
- VGG16的结构
- Anchor的设置
注释翻译
在代码里,anchor固定宽度为8,高度为[6, 12, 24, 36]
(in function get_image_and_targets(), model_data_detect.py )
target_cls = np.zeros((height_feat, width_feat, 2 * num_anchors))
target_ver = np.zeros((height_feat, width_feat, 2 * num_anchors))
target_hor = np.zeros((height_feat, width_feat, 2 * num_anchors))
对于最后输出的特征图中的每一个点,都有一个与原始图片相应的锚点中心
对每一个锚点中心,都有四个anchor(有相同的宽度和不通过的高度)
通过一些规则,每个anchor box可以是正的或者负的(即含有文本和不含文本)
在宽度上,如果超过一半有文字,就是正的;在高度上同样;在4个anchor中选择IOU最大的那个anchor
具体model_data_detect.py的calculate_targets_at(anchor_center, txt_list, anchor_heights)
如果anchor是负的,那么target_cls = [0, 0], target_ver = [0, 0], and target_hor = [0, 0];
如果是正的,那么target_cls = [1, 1],并初始化target_ver = [0, 0], target_hor = [0, 0]
假设,anchor坐标是[p_left, p_up, p_right, p_down],最接近的文本框是[t_left, t_t_up, t_right, t_down],那么目标将这样计算:
| ratio_bbox = [0, 0, 0, 0] |
| # |
| ratio = (text_bbox[0]-anchor_bbox[0]) /anchor_width |
| if abs(ratio) < 1: |
| ratio_bbox[0] = ratio |
| # |
| # print(ratio) |
| # |
| ratio = (text_bbox[2]-anchor_bbox[2]) /anchor_width |
| if abs(ratio) < 1: |
| ratio_bbox[2] = ratio |
| # |
| # print(ratio) |
| # |
| ratio_bbox[1] = (text_bbox[1]-anchor_bbox[1]) /ah |
| ratio_bbox[3] = (text_bbox[3]-anchor_bbox[3]) /ah |
| # |
| # print(ratio_bbox) |
| # |
| ver.extend([ratio_bbox[1], ratio_bbox[3]]) |
| hor.extend([ratio_bbox[0], ratio_bbox[2]]) |
| # |
所以,侧边细化(side-refinement)被整合到target_hor,如果target_hor是两端之一,它就是侧边位移和锚宽的比率。如果target_hor在中间位置,那么等于[0, 0]。而target_ver是垂直位移与锚高度之比
在损失函数中,首先分开处理正锚和负锚,正锚的损失值是所有正锚的平均,负锚的损失值是所有负锚的平均。因为一张图片里会有很多负锚,所以会引起不平衡问题。
为了简单拿的区分正锚和负锚,使用了加倍指数(doubled indicator),将正锚的target_cls = [1, 1],负锚为[0, 0];
其次,修改了每个anchor的权重,如果学习到的bbox在文本bbox附近,那么损失值会比较小,这样权重就会变小;如果损失值变大,权重也变大。实质上,这个跟focal loss是一样的,只是实现的方式不一样。