环保监测平台为什么弃用MySQL,而选择时序数据库?
小 T 导读:昆岳互联的“a环保”APP基于自主打造的环保产业互联网平台(INECO平台),对环境基础设施海量数据实时处理与分析,可以秒级实时采集工业大气环保各项监控指标的数据,分别通过年、月、日三个维度,结合不同的采集频率周期,对采集到的海量数据进行分析、展示,在时序数据库的选型中,经过对比,最终选择了TDengine。
程序设计
整个数据采集服务基于MQTT协议开发,通过阿里巴巴的nacos集群实现配置和服务发现,通过feign模式调用其他微服务模块的业务数据,来对上报的数据进行业务解析,并将解析的结果存入对应监控指标对应的点位表中。采集服务采用mybatis-plus的多数据源配置,使用的是目前性能最佳的HikariCP数据连接池,分别配置MySQL和TDengine两个数据库连接,实现了多数据源的无缝切换。整个采集服务基于容器化部署,采用Kubernetes进行容器编排,通过分布式锁方式避免了数据重复入库,提高了数据的解析速度,实现MQTT的分布式分组采集。
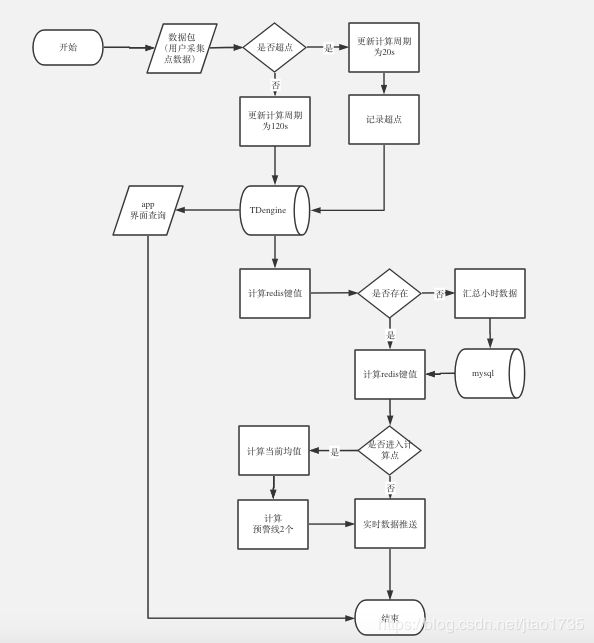
数据库选型
我们公司对比了阿里的时序时空数据库TSDB、传统的 MySQL 以及 TDengine。
与传统数据库对比
-
MySQL :查询效率低,需要按数据时间分库分表,应用场景不合适,没有基于采集频率周期的高效查询。
-
TDengine :查询效率高,不需要分表,具备时间维度聚合、流式计算、缓存等特性。
| 数据库 | 查询效率 | 应用场景 | 流式计算 |
|---|---|---|---|
| MySQL | 低 | 事务型 | 不支持 |
| TDengine | 高 | 时序型 | 支持 |
与其他时序库对比
-
阿里TSDB :闭源,私有化落地比较难
-
TDengine :性价比高,开源,支持云端和本地部署
尤其是TDengine一张设备一张表的建表思路,和我们的程序设计方式非常契合。同时TDengine还有一个超级表的设计,可以给不同的设备打上标签,比如客户ID、设备ID、指标名称等等,管理多条时间线变得非常方便。整个数据库也是SQL交互方式,支持标准JDBC接口,可以无缝对接MyBastis ORM框架,开发起来非常方便。因此我们最终选用了TDengine云服务作为各项监控指标的存储数据库,并且花了大概一周时间就上线了系统。
建表思路
我们目前是通过超级表的模式来进行数据建表,我们子表是point_#{采集点唯一编码} 。标签对应为客户唯一标识、设备唯一标识、采集指标编号、指标名称、计量单位名称。
建立超级表
create table point(ts timestamp,val float,flag bool) tags(cusid bigint, devid bigint, code bigint, pointname binary(20),unitname binary(20));
根据超级表建立子表
create table point_0301 using point tags(10000000, 301, 107, 'DUST', 'mg/Nm3');
create table point_0302 using point tags(10000000, 302, 107, 'DUST', 'mg/Nm3');
...
这样的设计很自然的对采集数据进行了分表。而在查询时,可以从超级表进行查询,无需针对每张子表进行。此外,在超级表查询时,还可以按照客户、采集量等去筛选具体业务需要的子表出来。超级表的标签相当于对子表加了一个索引,非常方便。超级表的标签是支持增删改查的,这对我们目前尚未定型的业务逻辑是个大好消息:在后面业务需要发生变化时,比如需要为各个设备增加一个“城市”的分析维度,我们也不再需要重新更新一遍所有数据,而只用直接为每个表增加一个标签即可。
方便的流式计算
时间维度聚合
业务需要对原始的秒级采集数据进行年、月、日、分钟等的聚合计算和绘图。这个需求可以直接在TDengine中按照时间进行将采样查询解决。在计算超标浓度的时候,需要对每分钟的平均值进行实时计算监控。比如污染排放的监控中,业务要求对NOx的浓度实时监控,并且让用户选择时间范围显示浓度变化曲线以及聚合的窗口长度(5分钟、15分钟、30分钟、日、月、年)。由于传到前端的数据是时序数据库已经计算好的,数据量一般没有那么大,相比把所有原始数据点都拉到前端再处理而言,效率大大提高。
00:00:00.000' and ts>'2020-05-29 00:00:00.000' interval(5m); //每5分钟聚合
select val from point_0301 where ts<'2020-05-30 00:00:00.000' and ts>'2020-05-29 00:00:00.000' interval(15m); //每15分钟聚合
select val from point_0301 where ts<'2020-05-30 00:00:00.000' and ts>'2020-05-29 00:00:00.000' interval(30m); //每30分钟聚合

流式计算
对于每分钟的平均量进行实时计算,只需要简单的定义时间窗口和滑动增量,数据库就能返回每分钟的平均量。对于实时监测、预警的指标,可以专门为这类数据建立流计算,并将计算结果写入新的表(如下strm_pt_0304)中存储,这样整个实时计算的结果也可以做历史回顾。
create table strm_pt_0304 as select avg(val) from point_0304 INTERVAL(1m) SLIDING(1m);//每分钟计算一次每分钟的平均值
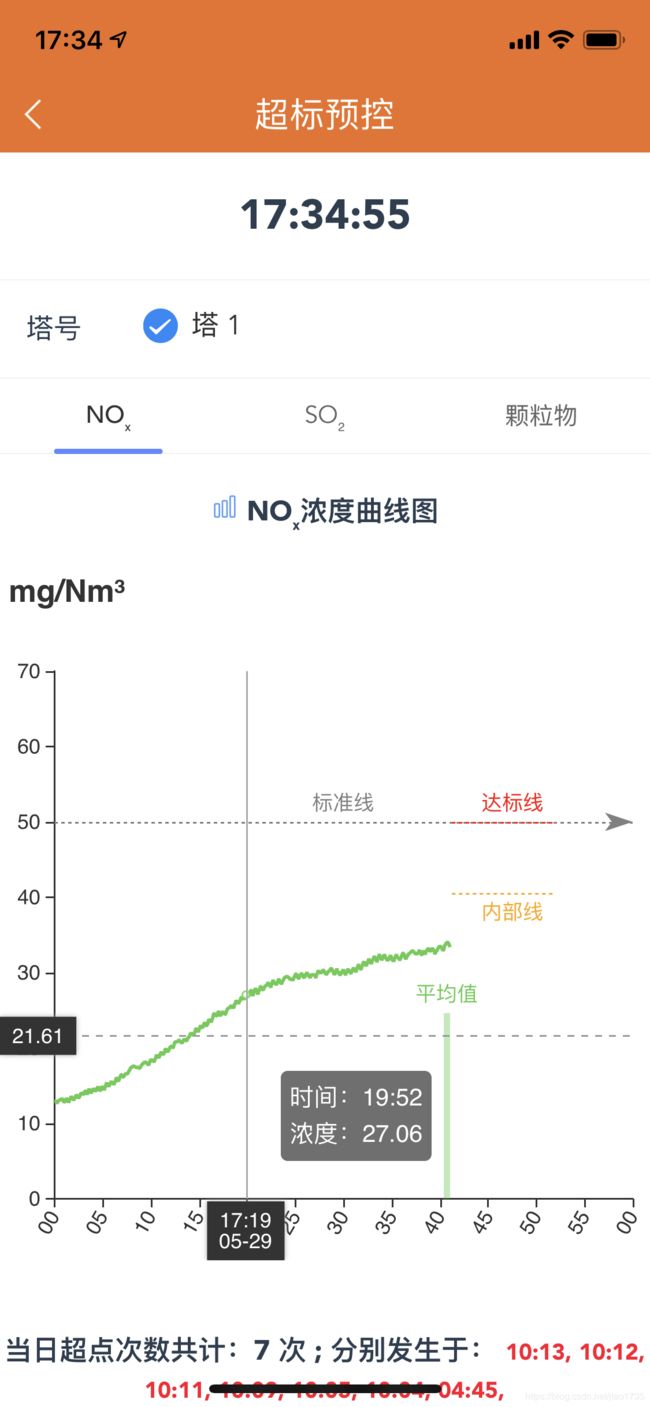
原本很多需要在程序中处理的数值计算,现在完全都由TDengine承担,一方面分担了程序的计算压力,另一方面更重要的是,聚合结果可以自动持久化存储,支持历史数据即时回看。
对TDengine的体验总结
开源版的TDengine可以做本地测试适配,安装包只有5MB,使用非常方便,各种接口也和企业版完全一致。但希望可以对购买企业版的客户,提供一个可以兼容开源版本的web版查询工具,方便调试。
现在TDengine对Java驱动的支持已经相当好,但希望可以提供更多.net core版本的驱动支持。
作者介绍:
王飞,昆岳互联物联网技术专家,有多年.net/Java软件设计开发经验、熟悉工业级监控、环境监控等业务建模,主导了昆岳互联“A环保”项目的整体设计、开发工作。