类执行机制
在完成将class文件信息加载到JVM并产生Class对象后,就可执行Class对象的静态方法或实例化对象进行调用了。
字节码解释执行方式 在源码编译阶段将源码编译为JVM字节码,JVM字节码是一种中间代码的方式,要由JVM在运行期对其进行解释并执行。
字节码解释执行
由于采用的为中间码的方式,JVM有一套自己的指令,对于面向对象的语言而言,最重要的是执行方法的指令,JVM采用四个指令来执行不同的方法调用:
-
invokestatic对应的是调用static方法 -
invokevirtual对应的是调用对象实例的方法 -
invokeinterface对应的是调用接口的方法 -
invokespecial对应的是调用private方法和编译源码后生成的方法,此方法为对象实例化时的初始化方法
下面一段代码经过javac 编译后,查看其字节码可以看到上面四种方法的调用。
public class Demo {
public void execute() {
A.execute();
A a = new A();
a.bar();
IFoo b=new B();
b.bar();
}
// Class A
static class A {
public static int execute() {
return 1+2;
}
public int bar() {
return 1+2;
}
}
// Class B
class B implements IFoo {
public int bar(){
return 1+2;
}
}
public interface IFoo {
public int bar();
}
}
javac Demo.java # 生成class文件
javap -c Demo # 查看execute执行的字节码
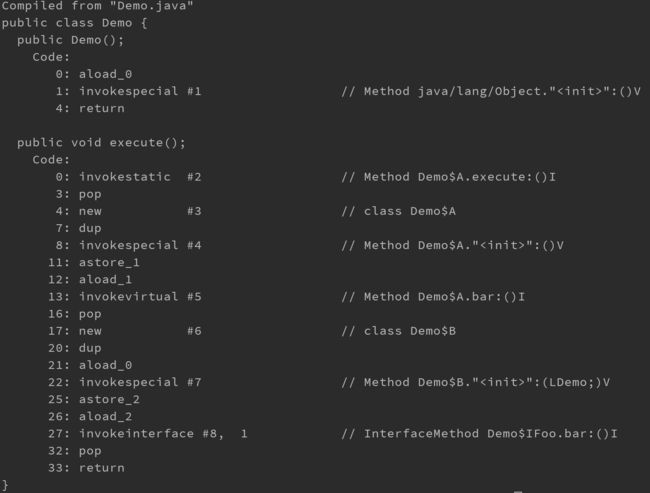
JDK 是基于栈的体系结构来执行字节码,我们在创建线程的时候,都会产生程序计数器(PC)(或称为PC registers)和栈(Stack)。
- PC存放了下一条要执行的指令在方法内的偏移量;
- 栈中存放了栈帧(StackFrame);
每个方法每次调用都会产生栈帧。栈帧主要分为局部变量区和操作数栈两部分:
- 局部变量区用于存放方法中的局部变量和参数
- 操作数栈中用于存放方法执行过程中产生的中间结果
- 栈帧中还会有一些杂用空间,例如指向方法已解析的常量池的引用、其他一些VM内部实现需要的数据
例如下面的代码:
public class DemoTwo {
public static void execute() {
int a = 1;
int b = 2;
int c = (a+b)*5;
}
}
方法执行的过程如下:
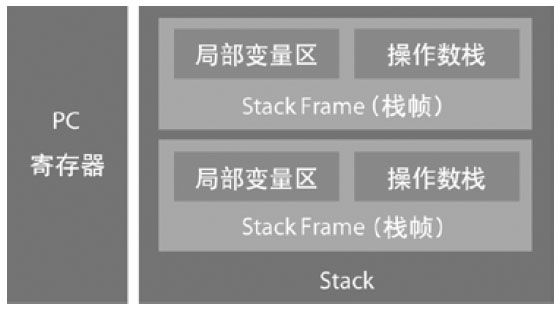
Compiled from "DemoTwo.java"
public class DemoTwo {
public DemoTwo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: return
public static void execute();
Code:
0: iconst_1 // 将类型为int、值为1的常量放入操作数栈;
1: istore_0 // 将操作数栈中栈顶的值弹出放入局部变量区;
2: iconst_2 // 将类型为int、值为2的常量放入操作数栈;
3: istore_1 // 将操作数栈中栈顶的值弹出放入局部变量区;
4: iload_0 // 装载局部变量区中的第一个值到操作数栈;
5: iload_1 // 装载局部变量区中的第二个值到操作数栈;
6: iadd // 执行int类型的add指令,并将计算出的结果放入操作数栈;
7: iconst_5 // 将类型为int、值为5的常量放入操作数栈;
8: imul // 执行int类型的mul指令,并将计算出的结果放入操作数栈;
9: istore_2 // 将操作数栈中栈顶的值弹出放入局部变量区;
10: return
}
编译执行
解释执行的效率较低,为提升代码的执行性能,Sun JDK提供将字节码编译为机器码的支持,编译在运行时进行,通常称为JIT编译器。
Sun JDK在执行过程中对执行频率高的代码进行编译,对执行不频繁的代码则继续采用解释的方式,因此SunJDK又称为Hotspot VM。
在编译上Sun JDK提供了两种模式:
- client compiler (-client)
- server compiler (-server)
client compiler (C1)
又称为C1,较为轻量级,只做少量性能开销比高的优化,它占用内存较少,适合于桌面交互式应用。在寄存器分配策略上,JDK 6以后采用的为线性扫描寄存器分配算法,在其他方面的优化主要有:方法内联、去虚拟化、冗余削除等。
方法内联
方法执行时,要经历多次参数传递、返回值传递及跳转等,于是C1采取了方法内联的方式,即把调用到的方法的指令直接植入当前方法中。
如下代码:
public void bar() {
…
bar2();
…
}
private void bar2() {
// do something
}
当编译时,如bar2代码编译后的字节数小于等于35字节,那么,会演变成类似这样的结构:
35K这个值可通过在启动参数中增加-XX:MaxInlineSize=35来进行控制。
public void bar() {
…
// do something
…
}
去虚拟化
去虚拟化是指在装载class文件后,进行类层次的分析,如发现类中的方法只提供一个实现类,那么对于调用了此方法的代码,也可进行方法内联,从而提升执行的性能。
如下代码:
public interface IFoo {
public void bar();
}
public class Foo implements IFoo {
public void bar() {
// do something
}
}
public class Demo {
public void execute(IFoo foo) {
foo.bar();
}
}
当整个JVM中只有Foo实现了IFoo接口,Demo execute方法被编译时,就演变成类似这样的结构:
public void execute() {
// do something
}
冗余消除
冗余削除是指在编译时,根据运行时状况进行代码折叠或削除。
例如一段这样的代码:
private static final Log log = LogFactory.getLog(“BLUEDAVY”);
public void execute(){
if(log.isDebugEnabled()){
log.debug(“enter this method: execute”);
}
// do something
}
如log.isDebugEnabled返回的为false,在执行C1编译后,这段代码就演变成类似下面的结构:
public void execute() {
// do something
}
这是为什么会在有些代码编写规则上写不要直接调用log.debug,而要先判断的原因。
server compiler(C2)
又称为C2,较为重量级,C2采用了大量的传统编译优化技巧来进行优化,占用内存相对会多一些,适合于服务器端的应用。
和C1不同的主要是寄存器分配策略及优化的范围,寄存器分配策略上C2采用的为传统的图着色寄存器分配算法;由于C2会收集程序的运行信息,因此其优化的范围更多在于全局的优化,而不仅仅是一个方法块的优化。收集的信息主要有:分支的跳转/不跳转的频率、某条指令上出现过的类型、是否出现过空值、是否出现过异常。
逃逸分析 是C2进行很多优化的基础,逃逸分析是指根据运行状况来判断方法中的变量是否会被外部读取。如不会则认为此变量是逃逸的,基于逃逸分析C2在编译时会做标量替换、栈上分配和同步削除等优化。
在6.0的逃逸分析实现上有些影响性能,因此在update 18里临时禁用了,在Java 7中则默认打开。
标量替换
标量替换的意思简单来说就是用标量替换聚合量。
例如如下代码:
Point point=new Point(1,2);
System.out.println(“point.x=”+point.x+”; point.y=”+point.y);
当point对象在后面的执行过程中未用到时,经过编译后,代码会变成类似下面的结构:
int x=1;
int y=2;
System.out.println(“point.x=”+x+”; point.y=”+y);
之后基于此可以继续做冗余削除。这种方式能带来的好处是,如果创建的对象并未用到其中的全部变量,则可以节省一定的内存。而对于代码执行而言,由于无须去找对象的引用,也会更快一些。
栈上分配
在上面的例子中,如果p没有逃逸,那么C2会选择在栈上直接创建Point对象实例,而不是在JVM堆上。在栈上分配的好处一方面是更加快速,另一方面是回收时随着方法的结束,对象也被回收了,这也是栈上分配的概念。
同步削除
同步削除是指如果发现同步的对象未逃逸,那也没有同步的必要了,在C2编译时会直接去掉同步。
例如如下代码:
Point point=new Point(1,2);
synchronized(point){
// do something
}
经过分析如果发现point未逃逸,在编译后,代码就会变成下面的结构:
Point point=new Point(1,2);
// do something
除了基于逃逸分析的这些外,C2还会基于其拥有的运行信息来做其他的优化,例如编译分支频率执行高的代码等。
OSR编译
OSR编译和C1、C2最主要的不同点在于OSR编译只替换循环代码体的入口,而C1、C2替换的是方法调用的入口,因此在OSR编译后会出现的现象是方法的整段代码被编译了,但只有在循环代码体部分才执行编译后的机器码,其他部分则仍然是解释执行方式。
默认情况下,Sun JDK根据机器配置来选择client或server模式,当机器配置CPU超过2核且内存超过2GB即默认为server模式,但在32位Windows机器上始终选择的都是client模式时,也可在启动时通过增加-client或-server来强制指定
Sun JDK之所以未选择在启动时即编译成机器码,有几方面的原因:
- 静态编译并不能根据程序的运行状况来优化执行的代码,C2这种方式是根据运行状况来进行动态编译的,例如分支判断、逃逸分析等,这些措施会对提升程序执行的性能会起到很大的帮助,在静态编译的情况下是无法实现的。给C2收集运行数据越长的时间,编译出来的代码会越优;
- 解释执行比编译执行更节省内存;
- 启动时解释执行的启动速度比编译再启动更快。
但程序在未编译期间解释执行方式会比较慢,因此需要取一个权衡值,在Sun JDK中主要依据方法上的两个计数器是否超过阈值,其中一个计数器为调用计数器,即方法被调用的次数;另一个计数器为回边计数器,即方法中循环执行部分代码的执行次数。
调用计数器:CompileThreshold
该值是指当方法被调用多少次后,就编译为机器码。在client模式下默认为1 500次,在server模式下默认为10000次,可通过在启动时添加-XX:CompileThreshold=10 000来设置该值。
-XX:CompileThreshold=10 000
回边计数器:OnStackReplacePercentage
该值为用于计算是否触发OSR编译的阈值,默认情况下client模式时为933,server模式下为140,该值可通过在启动时添加-XX:OnStackReplacePercentage=140来设置。
client模式下计算规则:
CompileThreshold*(OnStackReplacePercentage/100)
server模式下计算规则:
(CompileThreshold*(OnStackReplacePercentage-InterpreterProfilePercentage))/100
Interpreter-ProfilePercentage的默认值为33,当方法上的回边计数器到达这个值时,即触发后台的OSR编译,并将方法上累积的调用计数器设置为Com-pileThreshold的值,同时将回边计数器设置为CompileThreshold/2的值,一方面是为了避免OSR编译频繁触发;另一方面是以便当方法被再次调用时即触发正常的编译,当累积的回边计数器的值再次达到该值时,先检查OSR编译是否完成。