新兴XML处理方法VTD-XML介绍
通常当我们提起XML的使用时,最头痛的部分便是XML的verbosity与XML的解析速度,当需要处理大XML文件时这个问题便变得格外严重。我在这里提及的,便是如何优化XML处理速度的话题。
当我们选择处理XML文件的时候,我们大致上有两种选择:
DOM,这是W3C的标准模型,它将XML的结构信息以树形的方式构建,提供了遍历这颗树的接口与方法。
SAX,一种低级的parser,逐元素的向前只读处理,不含有结构信息。
以上两种选择都各有利弊,但是都不是特别好的解决方案,它们的优缺点如下:
DOM
优点:易用性强,因为所有的XML结构信息都存在于内存中,并且遍历简单,支持XPath。
缺点:Parsing速度太慢,内存占用过高(原文件的5x~10x),对于大文件来说几乎不可能使用。
SAX
优点:Parsing速度快,内存占用不与XML的大小相联系(可以做到XML涨内存不涨)。
缺点:易用性差,因为没有结构信息,并且无法遍历,不支持XPath。如果需要结构的话只能读一点构造一点,这样的可维护性特别的差。
我们可以看出,基本上DOM与SAX是正好相反的两个极端,但是任何一个都不能很好的满足我们的大部分要求,我们需要找出另外一种处理方法来。注意XML的效率问题并不是XML本身的问题,而是处理XML的Parser的问题,就像我们在上面看到的两种方法有不同的效率权衡一样。
思考
我们很喜欢类似DOM的使用方法,因为我们可以遍历,这意味着可以支持XPath,大大增强了易用性,但是DOM的效率很低。就像我们已经知道,效率问题出在处理机制上。那么,DOM到底有哪些方面影响了它的效率呢?下面让我们来做一个全面的解剖:
在当今大多数基于虚拟机(托管,或任何类似机制)技术的平台下,对象的创建销毁是一个耗时的作业(这里值得主要是Garbage Collection的耗时),DOM机制中所运用的大量的对象创建销毁无疑是影响其效率的原因之一(会引发过多的Garbage Collection)。
每个对象都会额外有32bits用来存储它的内存地址,当像DOM一样拥有大量对象的时候这个额外开支也是不小的。
引起以上两个问题的最主要的效率问题在于,DOM与SAX都是extractive parsing模式,这种解析模式注定了DOM与SAX都需要大量的创建(销毁)对象,引起效率问题。所谓的extractive parsing就是说在解析XML时,DOM或SAX会提取一部分原文件(一般来说是一个字符串),然后在内存中进行解析构建(输出自然就是一个或一些对象了)。拿DOM这个例子来说,DOM会将每一个element, attribute, processing-instruction,comment等等都解析成对象并给与结构,这就是所谓的extractive parsing。
由extractive的问题带来的另一个问题便是更新效率,在DOM中(SAX因为不支持更新所以根本不提它),每一次需要做改动时,我们要做的就是将对象的信息再解析回XML的字符串,注意这个解析是个完整的解析,也就是说,原文件并没有被利用,而是直接将DOM模型重新完整解析成XML字符串。换句话讲,也就是DOM并不支持Incremental Update(增量更新)。
另一个很可能不被注意到的“小”问题便是XML的编码,无论是何种解析方法都需要能够处理XML的编码,也就是说,在读取的时候解码,在写入的时候编码。DOM的另一个效率问题便是当我对于一个大XML只想做很小的一块儿修改的时候它也必须首先将整个文件进行解码,然后构建结构。无形中又是一个开销。
让我们来总结一下问题,简单的讲DOM的效率问题主要出在它的extractiveparsing模式上(SAX也是一样,有同样的问题),由此引发了一系列相关问题,如果可以击破这些效率瓶颈的话那么可以想象XML的处理效率将进一步的得到提高。如果XML的易用性与处理效率得到飞跃性的提高的话,那么XML的应用范围,应用模式将得到更一步的升华,或许由此可以产生出许许多多精彩的以前连想都没有想过的基于XML的产品来。
出路
VTD-XML便是对以上问题的思考后给出的答案,它是一个non-extractive XML parser,由于它出色的机制,很好的解决(避免)了上面所提出的各种问题,并且还“顺便”带来了non-extractive的其他好处,像快速的解析与遍历、XPath的支持、IncrementalUpdate等等。我这里有一组数据,取自于VTD-XML的官方网站:
VTD-XML的解析速度是SAX(with NULLcontent handler)的1.5x~2.0x。With NULL content handler的意思就是说SAX解析中没有插入任何额外的处理逻辑,也就是SAX的最高速度。
VTD-XML的内存占用是原XML的1.3x~1.5x(其中1.0x的部分是原XML,0.3x~0.5x是VTD-XML占用的部分),而DOM的内存占用则是原XML的5x~10x。举一个例子,如果一个XML的大小是50MB,那么用VTD-XML读取进来内存占用会在 65MB~75MB之间,而DOM的内存占用则会在250M~500MB之间。基于这个数据用DOM处理大的XML文件几乎是不可能的选择。< /li>
你可能会觉得不可思议,真的可以做出比DOM易用性还好,比SAX还快的XML解析器吗?别急着下定论,还是来看看VTD-XML的原理吧!
基本原理
就像大多数好的产品一样,VTD-XML的原理并不复杂,而是很巧妙。为了实现non-extractive这个目的,它将原XML文件原封不动的以二进制的方式读进内存,连解码都不做,然后在这个byte数组上解析每个element的位置并把一些信息记录下来,之后的遍历操作便在这些保存下来的record上进行,如果需要提取XML内容就利用record中的位置等信息在原始byte数组上进行解码并返回字符串。这一切看起来都很简单,但是,这个简单的过程确有多个性能细节在里边,并且隐藏了若干个潜在的能力。下面我们首先来描述一下各个性能细节:
为了避免过多的对象创建,VTD-XML决定采用原始的数值类型作为record的类型,这样就可以不必用heap。VTD-XML 的record机制就叫做VTD(Virtual Token Descriptor),VTD将性能瓶颈在tokenization阶段就解决掉了真的是很巧妙很用心的做法。VTD是一个64bits长度的数值类型,记录了每个element的起始位置(offset),长度(length),深度(depth)以及token的类型(type)等信息。
注意VTD是固定长度的(官方决定用64bits),这样做的目的就是为了提高性能,因为长度固定,在读取,查询等操作的时候格外的高效(O(1)),也就是可以用数组这种高效的结构来组织VTD大大减少了因为大量使用对象而产生的性能问题。
VTD的超能力(一点都不夸张地说)就在于它能够将XML这种树形的数据结构简单的变换成对一个byte数组的操作,任何你能想象到的对于byte数组的操作都可以应用在XML上了。这是因为读取进来的XML是二进制的(byte数组),而VTD则记录了每个element的位置等访问用信息,当我们找到要操作的VTD的时候,只要用offset与length等信息就可以对原始byte数组进行任何操作,或者可以直接对VTD进行操作。举例来说,我想在一个大XML中找出一个element并删除它,那么我只需要找到这个element的VTD(遍历方法稍候再讲),将这个VTD从 VTD数组中删除,然后再利用所有的VTD写出到另一个byte数组中就可以了,因为删除的VTD标明了要删除的element的位置,所以在新写入的 byte数组中就不会出现这段element了,用VTD 写入新的byte数组实际上就是一个byte数组的拷贝,其效率相当的高,这就是所谓的增量更新(incrementalupdate)。
关于VTD-XML的遍历方式,它采用了LC (Location Cache),简单地说就是将VTD以其深度作为标准构建的一个树形的表结构。LC的entry也是64bits长的数值类型,前32bits代表一个 VTD的索引(index),后32bits代表了这个VTD的第一个child的索引。利用这些信息就可以计算出任何一个你想要到达的位置了,关于具体的遍历方法请参看官方网站的文章。基于这种遍历方式的VTD-XML有与DOM不同的操作接口,这是可以理解的,并且,VTD-XML的这种遍历方式可以在最少的几步内将你带到你所需要的地方去,遍历的性能十分突出。
总结
就像你上面看到的,VTD-XML有着迷人的特性,而如今的1.5版本中已经加入了XPath的支持(只要可以遍历,就可以支持 XPath,这是早晚的事:-)),它的实用性已经超越了当今我们所想象的范围了。另一个VTD-XML的超能力,就是基于它现在的处理方式,完全可以支持将来的BinaryXML标准,并通过Binary化将XML的应用推向更高一层楼!这也是我目前所期待的!:-)
不过,VTD-XML仍然有许多需要改进与完善的地方,这方面值得我们努力与探讨。
顺便提一下,VTD-XML是开源项目(GPL),目前有Java、C两种平台支持。如果你想在.NET试一试的话建议你使用IKVM(BSD style license)将VTD-XML转换成.NET程序集,相信你会喜欢上它的!;-)
第一部分:XML解析技术简介
XML(eXtensible Markup Language,可扩展标记语言)是由World Wide Web联盟(W3C)定义的元语言,即一种关于语言的语言。 Xml的优势或者说力量源于它的数据独立性,广泛应用在分布式计算领域。
XML解析技术的分类
根据从XML中获取数据的简易性,性能和最终所得到的数据模型的不同,XML解析技术大致可分为以下四类:
1.面向文档的流式解析;
2.面向文档的对象式解析;
3.面向文档的指针式解析;
4.面向应用的对象式解析;
这四类解析技术分别处于不同的抽象层次,适用于不同的应用场景, 针对具体的应用需求,选择合适的解析技术,往往能够减少内存消耗,缩短处理时间,更方便地获取数据,提高应用系统的整体性能。
1.1 面向文档的流式解析
流式解析是解析器顺序读取XML文档,捕获的各种事件,如元素开始和元素结束等,交由程序处理。
流式解析又分为两种解析方式:
1.推式解析(SAX:Simple API for XML)
2.拉式解析(StAX:Streaming API for XML)
这两种方式的主要区别在于是由解析器还是应用程序控制读循环(读入文件的循环)
1.1.1推式解析(SAX)
在这种解析方式中,解析器控制着读循环,在文档结束之前控制权不会返回给应用程序。
SAX是基于事件驱动的,即SAX解析器在读取XML文档的过程中生成一个事件流,并且对于每个事件通过回调事件处理程序中相应的方法来进行处理。比如元素开始和结束标记,元素内容,实体,语法分析错误等事件。
下图表示了一个Xml文件及其对应的文件流格式。
注:如图所示,回车换行也被解析成了一个字符。
1.1.2拉式解析(StAX)
在这种解析方式中,应用程序控制着读循环。反复调用解析器获得下一个事件,直到文档结束。
StAX针对同样的XML文档所获得事件类型和SAX基本相同。
1.2 面向文档的对象式解析
DOM(Document Object Model)是用与平台和语言无关的方式对XML文档进行建模的官方W3C标准 。
DOM的层次化对象模型是一个树形结构,它将一个XML文档看作一棵节点树,每个节点代表一个XML文档中的元素。
DOM的有点在于可以随机访问,但由于DOM在使用数据前需要完整的遍历XML文档,在内存中构建树形结构表示,因此需要消耗大量的内存,尤其是对于大型文档,性能下降的很快。
下图表示了Xml文件预期Dom树的对应关系。
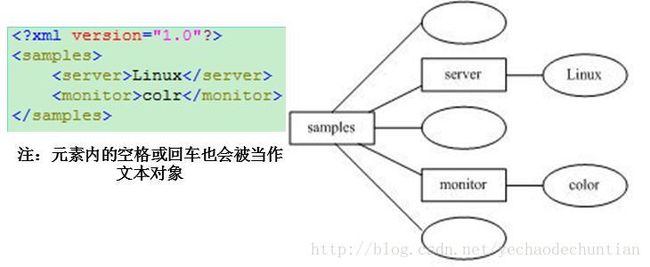
1.3 面向文档的指针式解析
面向文档的流式解析效率较高,但易用性差,而对象式解析易用性强,却效率较低。
这两种方式都是提取式解析(extractive parsing)。拿DOM这个例子来说,DOM会将每一个element,attribute等都在内存中解析成对象并给与一定结构。
更新 效率问题:这种Dom解析模式注定了需要大量的创建和销毁对象(GC问题),在DOM中(SAX并不支持更新),每一次改动都需要将DOM模型重新完整的解析成XML字符串,原文件并没有被利用,即DOM并不支持增量更新。为了解决这些问题,提出了一种较新颖的指针式解析技术,即VTD-XML(一种面向文档的指针式解析)。
二、VTD-XML基本原理介绍
VTD-XML是一种无提取的XML解析方法,它较好的解决了DOM占用内存过大的缺点,并且还提供了快速的解析与遍历、对XPath的支持和增量更新等特性。VTD-XML是一个开源项目,目前有Java、C两种平台支持。
2.1 VTD-XML基本原理
为了实现non-extractive(非提取)这个目的,它将原XML文件原封不动的以二进制的方式读进内存,连解码都不做,然后在这个二进制byte数组上解析每个 element的位置并把一些信息记录下来,这种记录就被成为VTD(Virtual Token Descriptor,虚拟令牌描述符)。
之后的遍历操作便在这些保存下来的记录上进行,如果需要提取XML内容就利用记录中的位置等 信息在原始byte数组上进行解码并返回字符串。
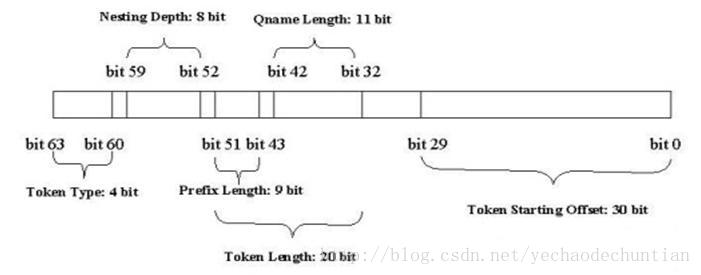
VTD(Virtual Token Descriptor,虚拟令牌描述符)结构:
VTD是一个64bits定长的数值类型,记录了每个元素的起始位置(offset),长度(length),深度(depth)以及令牌(元素标签)的类型(type)等信息。
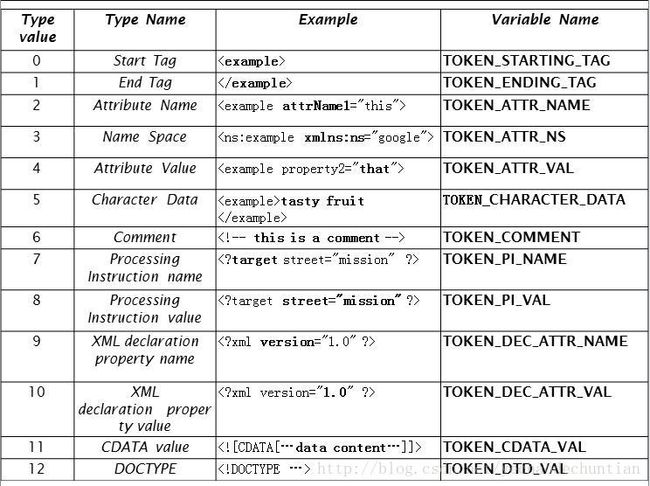
下图表示了VTD目前所支持的所有元素的类型(12种):
查询与更新:
如果需要提取XML内容,就查找VTD数组,利用VTD记录中的位置等信息在原始比特数组上进行解码并返回字符串。
而且VTD-XML还可以高效的实现增量更新,例如,如果想在一个大型XML文档中找出一个节点元素并删除它,那么只需要找到这个元素的VTD,将这个VTD从VTD数组中删除,然后再利用所有的VTD写出到另一个二进制数组中就可以了,这就是所谓增量更新。这个过程实际上就是一个二进制数组的拷贝过程,其效率是非常高的。

第三部分:应用实例
VTD-XML解析xml通常经过以下几步:
1.以一个byte数组开始(存放xml);
2.利用VTDGen进行解析;
3. 利用VTDNav进行导航定位;
4. 节点遍历使用Autopilot;
5. 利用Xpath进行节点选择
6. 增量更新使用XMLModifier
下面的代码主要功能:首先根据Xpath选择某些属性partNum='872-AA' 的item元素并用someting元素替换;替换价格小于40的元素文本为200.
Java代码
/* In this java program, we demonstrate how to use XMLModifier to incrementally
* update an simple XML purchase order.
* a particular name space. We also are going
* to use VTDGen's parseFile to simplify programming.
*/
import java.io.File;
import java.io.FileOutputStream;
import com.ximpleware.AutoPilot;
import com.ximpleware.ModifyException;
import com.ximpleware.NavException;
import com.ximpleware.VTDGen;
import com.ximpleware.VTDNav;
import com.ximpleware.XMLModifier;
public class update {
public static void main(String argv[]){
try {
// open a file and read the content into a byte array
VTDGen vg = new VTDGen();
String path = update.class.getResource("").getPath();
System.out.println(path);
if (vg.parseFile(path + "oldpo.xml", true)){
VTDNav vn = vg.getNav();
File fo = new File("f:/newpo.xml");
FileOutputStream fos = new FileOutputStream(fo);
AutoPilot ap = new AutoPilot(vn);
XMLModifier xm = new XMLModifier(vn);
ap.selectXPath("/purchaseOrder/items/item[@partNum='872-AA']");
int i = -1;
while((i=ap.evalXPath())!=-1){
xm.remove();
xm.insertBeforeElement("修改前的 Xml 文件:
Hurry, my lawn is going wild!
-
Lawnmower
148.95
Confirm this is electric
-
Baby Monitor
1
39.98
1999-05-21
修改后的 Xml 文件,红色字体为修改后的:
Hurry, my lawn is going wild!
-
Baby Monitor
1
200
1999-05-21
官网地址: http://vtd-xml.sourceforge.net/
第四部分:其他解析方式
前面所谈到的三种解析技术都是面向文档的,还有第四种解析技术:面向应用的对象式解析技术。
面向文档的解析技术对主要关心文档的XML结构的应用程序来说是适用的,但是有很多应用程序仅仅将XML作为数据交换的媒介,它们更关心的是文档数据本身,而面向应用的对象式解析技术更适用。
面向应用的对象式解析技术又称为为XML数据绑定,指将数据从一些存储媒介(如XML文档、文本文件和数据库)中取出,并通过应用程序表示这些数据的过程,即把数据绑定到虚拟机能够理解并且可以操作的某种内存中的结构。

常用的绑定框架有:JAXB、Castor、Jbind、Quick和Zeus等