- 19. 文件读写
- 19.1 文件操作
- 19.1.1 文件的基本操作
- 19.1.2 读写文件的一般步骤
- 19.1.2.1 打开文件
- 19.1.2.2 具体读写操作
- 19.1.2.3 关闭文件
- 19.1.3 文件对象方法
- 19.1.4 文件对象迭代器
- 19.1.5 使用with简化文件操作
- 19.1.6 字符串与二进制的转化
- 19.1.6.1 将字符串转换为二进制数
- 19.1.6.2 将二进制数转换为字符串
- 19.2 json读写
- 19.2.1 查看json的使用方法
- 19.2.2 json 读取
- 19.2.2.1 json.loads
- 19.2.2.2 json.load
- 19.2.3 json保存
- 19.2.3.1 dumps
- 19.2.3.2 dump
- 19.3 csv读写
- 19.3.1 CSV读取
- 19.3.1.1 常规读取
- 19.3.1.2 字典形式读取
- 19.3.2 CSV写入
- 19.3.2.1 常规写入
- 19.3.2.2 字典形式写入
- 19.3.2.3 自定义分隔符和终止符
- 19.3.3 示例项目
- 19.3.1 CSV读取
- 19.4 YAML读写
- 19.4.1 YAML简介
- 19.4.2 基本语法
- 19.4.3 数据类型
- 19.4.3.1 对象
- 19.4.3.2 数组
- 19.4.3.3 纯量
- 19.4.4 引用
- 19.4.5 应用场景
- 19.4.6 在线验证网址:
- 19.4.7 YAML的Python读写
- 19.4.7.1 YAML库安装
- 19.4.7.2 Python写YAML
- 19.4.7.2.1 将字典写入YAML文件
- 19.4.7.2.2 将列表写入YAML文件
- 19.4.7.3 Python读YAML
- 19.5 Excel读写
- 19.5.1 安装openpyxl模块
- 19.5.2 读取Excel文档
- 19.5.2.1 使用openpyxl打开Excel文档
- 19.5.2.2 从Workbook中获取Sheet
- 19.5.2.3 从sheet页中获取单元格
- 19.5.2.4 从表中取得行和列
- 19.5.3 写入Excel文档
- 19.5.3.1 创建和保存Excel文档
- 19.5.3.2 创建和删除sheet
- 19.5.3.3 将值写入单元格
- 19.5.4 修饰Excel文档
- 19.5.4.1 设置字体和样式
- 19.5.4.2 添加公式
- 19.5.4.3 调整行高和列宽
- 19.6 对象序列化
- 19.6.1 pickle模块方法
- 19.6.2 dumps和dump
- 19.6.2.1 dumps
- 19.6.2.2 dump
- 19.6.3 loads和load
- 19.6.3.1 loads
- 19.6.3.2 load
- 19.6.4 pickle示例
- 19.1 文件操作
19. 文件读写
19.1 文件操作
数据持久化,是将程序中的对象以数据的方式保存到磁盘上,在程序下次运行时,可以将数据从磁盘上恢复到内存中。数据持久化的方式有很多,而最为常见的方式是将数据以文件的形式保存。在Python中,可以通过内置函数的方法进行文件的读、写、删除等操作。
19.1.1 文件的基本操作
文件的基本操作比较多,如创建、删除、修改权限、写入、读取等等。
- 删除、修改权限:作用于文件本身,属于系统级操作
- 读取、写入:是文件最常用的操作,作用于文件内容,属于应用级操作
文件的系统级操作,一般使用Python中的os、sys等模块。
19.1.2 读写文件的一般步骤
读写文件一般常分为3步,每一步可使用相应的方法
- 1.打开文件:使用open方法,返回一个文件对象
- 2.具体的读写操作:使用该文件对象的read/write等方法
- 3.关闭文件:使用该文件对象的close方法
一个文件,必须在打开之后才可以对其进行相应的操作,并在操作完成均完成进行关闭。
19.1.2.1 打开文件
打开文件是读写操作的第一步,其方法open的具体定义如下所示:
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
比较关键的参数如下所示:
- file:打开的文件名,属于字符串类型,但如果文件名含有特殊字符,需要进行转义。
- mode:打开文件的方式,如只读、只写、读写、二进制等等产,默认为只读。
- encoding:如直接保存为文件文本,需要指定编码格式,不然会造成读取文件文件出现乱码
mode的详细介绍如下所示:
| mode | 含义 |
|---|---|
| r | 只读,但文件必须存在 |
| w | 只写,如果文件已经存在,则覆盖,不存在,则重新创建 |
| a | 以只写的文件打开文件,并在文件后追加内容,如果文件不存在,则创建新文件 |
| b | 以二进制形式打开,不能单独使用 |
| + | 以读写形式打开文件, 不能单独使用 |
| r+ | 以读写形式打开文件,文件必须存在,当写入时,会清空原内容 |
| w+ | 以读写形式打开文件,文件不存在则创建文件,如已经存在,当写入时,会清空原内容 |
| a+ | 以读写形式打开文件,文件不存在则创建文件,如已经存在,当写入时,在文件后追加原内容 |
以上仅为常见的一些模式,实际应用还可使用组合模式,即同时使用多种模式来操作文件,如rb、wb、wb+、ab等
另外根据操作系统的不同,又可以分为文本模式和二进制模式,其主要区别如下所示:
- 在Windows系统中,文本模式下Windows平台的末尾换行符为\r\n,在读取时转换为\n,而在写入时又将\n转换为\r\n。这种隐藏的行为对于文本文件是没有问题的,但如果以文本模式打开二进制数据文件(如图片、EXE程序等)则会发生问题,因改变了文件的具体内容。
- 在Unix/Linux系统中,末尾换行符为\n,因此两者没有区别
19.1.2.2 具体读写操作
通过open方法得到文件对象后,就可以对文件进行操作,常用的方式是读和写。
1.读取文件
通过调用文件对象的read方法可以获得文件的内容,示例代码如下所示:
>>> fo=open(r"C:\Surpass\a.txt","r")
>>> s=fo.read()
>>> s
打开文件后,文件对象fo中的read方法,会将文件的全部内容一次性读取到内存中。
2.写入文件
将字符串写入文件,可以调用文件对象的write方法,示例代码如下所示:
>>> fo=open(r"C:\Surpass\a.txt","w")
>>> fo.write("Surpass")
如果文件是以二进制形式打开,则只能以二进制形式写入数据。
>>> fo=open(r"C:\Surpass\a.txt","wb")
>>> fo.write(b"Surpass")
19.1.2.3 关闭文件
直接使用文件对象的close方法即可。在打开文件并全部操作完之后,需要及时关闭。否则会导致其他操作出错,如删除、移动等,则提示文件正在使用。
19.1.3 文件对象方法
常见的文件对象方法如下所示:
| 方法 | 描述 |
|---|---|
| read(size) | 读取指定size的字节数据,然后作为字符串或bytes对象返回,size为可选参数,如未指定,则默认文件所有内容 |
| readline() | 读取一行,并在字符串末尾留下换行符\n,如果到文件尾,则返回空字符串 |
| readlines() | 读取所有行,并保存至列表中,每个元素代表一行,类似于list(fo) |
| writer(string) | 将string写入到文件中,返回写入的字符数,如果以二进制模式,则需要将string转换为bytes对象 |
| tell() | 返回文件对象当前所在位置,从文件开头开始计算字节数 |
| seek(offset,from_what) | 改变文件对象所处的位置。offset是相对参考位置的偏移量,from_what表示参考位置,0-文件头,默认;1-当前位置;2-文件尾 |
19.1.4 文件对象迭代器
文件对象本身也是一个迭代器,可以与for循环配合进行文件的读取。示例如下所示:
>>> f=open("a.txt","wb+")
>>> f.write(b"name is Surpass,age is 28\n")
25
>>> f.write(b"I am learning Python")
20
>>> f.close()
>>> f=open("a.txt","r+")
>>> for content in f:
... print(content)
name is Surpass,age is 28
I am learning Python
>>> f.close()
在for循环中,每循环一次,相当于调用了一次readline方法。
19.1.5 使用with简化文件操作
通过以上你会发现,每次使用文件操作,都需要3个步骤。那有没有简便的办法来简化这些操作了?Python内置了with语句,使用其可以简化这种写法,在调用完成之后,with语句会自动关闭。其语法格式如下所示:
with 表达式 as 变量:
doSomething
针对文件操作而言,表达式就是open函数,as后面的变量就是open返回的文件对象。
示例代码如下所示:
import os
filePath=os.getcwd()
filename="a.txt"
with open(os.path.join(filePath,filename),"wb+") as fo:
try:
fo.write(b"name is Surpass,age is 28\n")
fo.write(b"I am learning Python")
except Exception as ex:
print(f"write error\{ex}")
with open(os.path.join(filePath,filename),"r") as fo:
for content in fo:
print(content)
19.1.6 字符串与二进制的转化
在处理文件操作时,常用的做法是以二进制形式保存,以文件方式使用。一是二进制文件更小,便于网络传输和存储,另外也可以避免保存与读取编码不同造成的乱码情况。
19.1.6.1 将字符串转换为二进制数
bytes定义格式如下所示:
string, encoding[, errors]
示例代码如下所示:
>>> tempA=b"name is Surpass,age is 28"
>>> tempB=bytes("name is Surpass,age is 28","utf8") # 使用utf8编码
>>> print(f"{tempA}\n{tempB}")
b'name is Surpass,age is 28'
b'name is Surpass,age is 28'
19.1.6.2 将二进制数转换为字符串
如果将二进制数转换为字符串,可以调用二进制对象的decode方法,并传入指定的解码格式,示例如下所示:
>>> tempB=bytes("我爱中国,I love China","gb2312")
>>> print(f"{tempB}\n{tempB.decode('utf8')}\n{tempB.decode()}")
Traceback (most recent call last):
File "", line 1, in
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 0: invalid continuation byte
程序报错了,这个问题仔细看看,就知道原因所在了,编码使用gb2312,解码使用了utf8。因此在做转换时,需要避免这种情况发生,
>>> tempB=bytes("我爱中国,I love China","gb2312")
>>> print(f"{tempB}\n{tempB.decode('gb2312')}")
b'\xce\xd2\xb0\xae\xd6\xd0\xb9\xfa\xa3\xacI love China'
我爱中国,I love China
Windows平台与Linux平台编码解码是有区别的,主要如下所示:
- 在Linux平台中,生成的文件默认编码是utf8格式,所以解码需要指定解码格式应为utf8
- 在Windows平台中,中文操作系统生成文件默认为gb2312/gbk格式,所以解码需要指定为相应的编码格式才能正常解码
为避免因操作系统不同,因此在转换时需要显式指定相应的编码和解码格式
19.2 json读写
在日常种类接口测试中,会经常处理JSON格式的请求报文和响应报文等,平时用得最多的也是Python自带的json包,其提供了4个方法dumps、dump、loads、load。
1、JSON不能存储每一种Python值,仅能存储以下数据类型的传下
- 字符串
- 整形
- 浮点型
- 布尔型
- 列表
- 字典
- NoneType
2、JSON不能表示Python对象,如File对象、CSV Reader、Regex对象等
19.2.1 查看json的使用方法
import json
print(json.__all__)
输出结果为:
['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONDecodeError', 'JSONEncoder']
19.2.2 json 读取
json包常用的读取方法为loads、load。
loads:可理解为load string,其功能是将json格式的字符串转换为Python数据类型(字典)
load:读取json文件,将转换为Python类型
以下分别介绍其用法
19.2.2.1 json.loads
loads常用用法如下所示:
json.loads(str,encoding='utf8')
示例如下所示:
import json
jsonStr="""{
"book":"json in action",
"author":"Surpassme",
"isbn":961839721541,
"中文名":"JSON实战"
}"""
print(f"jsonStr type is {type(jsonStr)}")
if isinstance(jsonStr,(str,)):
result=json.loads(jsonStr,encoding="utf8")
print(f"输出的json\n{result}")
else:
print(f"传入的字符类型{type(jsonStr)},不是字符串")
输出结果
jsonStr type is
输出的json
{'book': 'json in action', 'author': 'Surpassme', 'isbn': 961839721541, '中文名': 'JSON实战'}
需要注意两点:
1、传入的数据一定要是字符串格式,如果传入字典则会出错
2、建议增加字符串编码格式,防止出现乱码
19.2.2.2 json.load
load常用用法如下所示:
json.load(jsonfile)
示例如下所示:
import json
import os
def ReadJsonFile(path,strEncode="utf8"):
try:
with open(path,"r",encoding=strEncode) as fr:
return json.load(fr)
except Exception as ex:
raise ex
if __name__=="__main__":
jsonFile=os.getcwd()+"\\jsonfile.json"
data=ReadJsonFile(jsonFile)
print(f"data is\n{data}")
输出结果
data is
{'book': 'json in action', 'author': 'Surpassme', 'isbn': 961839721541, '中文名': 'JSON实战'}
19.2.3 json保存
json包常用的读取方法为dumps、dump。
dumps:可理解为dump string,其功能是将Python数据类型将转换为json格式的字符串
dump:将Pyhon数据保存为json文件
19.2.3.1 dumps
dumps常用用法如下所示:
json.dumps(obj,ensure_ascii=True,indent=None)
- ensure_ascii:输出字符串是否采用ascii编码,如果有中文,需要使用utf8编码
- indent:输出美化功能,一般为正数才有效
示例如下所示:
import json
jsonStr={
"book":"json in action",
"author":"Surpassme",
"isbn":961839721541,
"中文名":"JSON实战"
}
result=json.dumps(jsonStr,ensure_ascii=False,indent=1)
print(result)
运行结果如下所示:
{
"book": "json in action",
"author": "Surpassme",
"isbn": 961839721541,
"中文名": "JSON实战"
}
19.2.3.2 dump
dump常用用法如下所示:
json.dump(obj,file,ensure_ascii=True,indent=None)
示例如下所示:
import json
def SavaAsJsonFile(path,data,strEncode="utf8",ensure_ascii=False,indent=None):
try:
with open(path,"a",encoding=strEncode) as fw:
return json.dump(data,fw,ensure_ascii=ensure_ascii,indent=indent)
except Exception as ex:
raise ex
if __name__=="__main__":
jsonStr={
"book":"json in action",
"author":"Surpassme",
"isbn":961839721541,
"中文名":"JSON实战"
}
path=os.getcwd()+"\\jsonfile.json"
SavaAsJsonFile(path,jsonStr,indent=1)
运行结果如下所示:
{
"book": "json in action",
"author": "Surpassme",
"isbn": 961839721541,
"中文名": "JSON实战"
}
19.3 csv读写
csv(Comma-Separated Values)一般是特指以逗号做为分隔符的文本文件。因使用简单方便,平时在测试过程也会经常用到该类型文件。今天就来学习一下在Python中如何处理csv文件。
19.3.1 CSV读取
19.3.1.1 常规读取
读取CSV文件常用的步骤为,创建一个CSV文件对象,打开文件进行读取
- CSV文件如下所示:

- 示例代码如下所示:
import csv
import os
def ReadCSVFile(path=os.getcwd(),fileName="test.csv",fileEncode="utf8"):
csvFilePath=path+"\\"+fileName
dataValue=[]
if os.path.exists(csvFilePath) and os.path.isfile(csvFilePath):
try:
with open(csvFilePath,"r",encoding=fileEncode) as fr:
dataContent=csv.reader(fr)
for dataRow in dataContent:
dataValue.append(dataRow)
except Exception as ex:
raise ex
return dataValue
if __name__=="__main__":
path=r"C:\Users\Administrator\PycharmProjects\TestProject\PythonIOTest\csvLesson"
fileName="CSVTestFile.csv"
data=ReadCSVFile(path=path,fileName=fileName)
for item in data:
print(item)
- 运行结果如下所示:
['ID', 'Department', 'Employees', 'HireDate']
['1', 'Dev', 'Kevin', '2019-10-30']
['2', 'Prd', 'Lily', '2019-10-31']
['3', 'Test', 'Kate', '2019-11-01']
['4', 'Dev', 'Leo', '2019-11-02']
['5', 'Prd', 'Lucy', '2019-11-03']
['6', 'Test', 'Bruce', '2019-11-04']
['7', 'Dev', 'KK', '2019-11-05']
['8', 'Dev', 'Gaga', '2019-11-06']
['9', 'Dev', 'ABC', '2019-11-07']
['10', 'Dev', 'HBO', '2019-11-08']
19.3.1.2 字典形式读取
如果CSV文件第一行为标题行,余下全部为数据,则可以采用字典形式进行读取。 以此种方式读取时,会默认将第一行(标题)做为Key值,从第二行开始做为数据内容即Value
- 示例代码如下所示:
import csv
import os
def ReadFromDict(path=os.getcwd(),fileName="test.csv",fileEncode="utf8"):
csvFilePath=path+"\\"+fileName
dataValue=[]
if os.path.exists(csvFilePath) and os.path.isfile(csvFilePath):
try:
with open(csvFilePath,"r",encoding=fileEncode) as fr:
dataContent=csv.DictReader(fr)
headers=dataContent.fieldnames
next(dataContent)
for dataRow in dataContent:
dataValue.append(dataRow)
except Exception as ex:
raise ex
return dataValue,headers
if __name__=="__main__":
path=r"C:\Users\Administrator\PycharmProjects\TestProject\PythonIOTest\csvLesson"
fileName="CSVTestFile.csv"
data,headers=ReadFromDict(path=path,fileName=fileName)
print(f"header is {headers}")
for item in data:
outStr=f'ID is {item.setdefault("ID","Exception")},Employee name is {item.setdefault("Employees", "Exception")} \
employees\'s department {item.setdefault("Department","Exception")}'
print(outStr)
- 运行结果如下所示:
header is ['ID', 'Department', 'Employees', 'HireDate']
ID is 1,Employee name is Kevin employees's department Dev
ID is 2,Employee name is Lily employees's department Prd
ID is 3,Employee name is Kate employees's department Test
ID is 4,Employee name is Leo employees's department Dev
ID is 5,Employee name is Lucy employees's department Prd
ID is 6,Employee name is Bruce employees's department Test
ID is 7,Employee name is KK employees's department Dev
ID is 8,Employee name is Gaga employees's department Dev
ID is 9,Employee name is ABC employees's department Dev
ID is 10,Employee name is HBO employees's department Dev
19.3.2 CSV写入
19.3.2.1 常规写入
读取CSV文件常用的步骤为,创建一个CSV文件对象,打开文件进行写入
- 示例代码如下所示:
import csv
import os
def ReadCSVFile(path=os.getcwd(),fileName="test.csv",fileEncode="utf8"):
csvFilePath=path+"\\"+fileName
dataValue=[]
if os.path.exists(csvFilePath) and os.path.isfile(csvFilePath):
try:
with open(csvFilePath,"r",encoding=fileEncode) as fr:
dataContent=csv.reader(fr)
for dataRow in dataContent:
dataValue.append(dataRow)
except Exception as ex:
raise ex
return dataValue
def SaveCSVFile(path=os.getcwd(),fileName="testSave.csv",fileEncode="utf8",content=""):
csvFilePath=path+"\\"+fileName
if os.path.exists(path) and os.path.isdir(path):
try:
with open(csvFilePath,'w+',encoding=fileEncode,newline="") as fw:
dataObj=csv.writer(fw)
for item in content:
dataObj.writerow(item)
except Exception as ex:
raise ex
if __name__=="__main__":
path=r"C:\Users\Administrator\PycharmProjects\TestProject\PythonIOTest\csvLesson"
print("Test save file as csv file")
data=[
['ID', 'Department', 'Employees', 'HireDate'],
['1', 'Dev', 'Kevin', '2019-10-30'],
['2', 'Prd', 'Lily', '2019-10-31'],
['3', 'Test', 'Kate', '2019-11-01'],
['4', 'Dev', 'Leo', '2019-11-02'],
['5', 'Prd', 'Lucy', '2019-11-03']
]
SaveCSVFile(path=path,content=data)
dataFromSaveFile=ReadCSVFile(path=path,fileName="testSave.csv")
for item in dataFromSaveFile:
print(item)
1、如果保存的CSV文件出现空白行,则在with open(...,newline="")增加参数newline=""
2、CSV.Writer中的方法writerow()方法接受一个列表参数。列表中的每个词,放在输出的CSV文件中的一个单元格中。writerow()函数的返回值,是写入文件中这一行的字符数(包含换行符)
- 运行结果如下所示:
Test save file as csv file
['ID', 'Department', 'Employees', 'HireDate']
['1', 'Dev', 'Kevin', '2019-10-30']
['2', 'Prd', 'Lily', '2019-10-31']
['3', 'Test', 'Kate', '2019-11-01']
['4', 'Dev', 'Leo', '2019-11-02']
['5', 'Prd', 'Lucy', '2019-11-03']
19.3.2.2 字典形式写入
如果我们要创建带有标题和数据的CSV文件,则可以采用以字典形式进行保存文件。
- 示例代码如下所示:
import csv
import os
def ReadFromDict(path=os.getcwd(),fileName="test.csv",fileEncode="utf8"):
csvFilePath=path+"\\"+fileName
dataValue=[]
if os.path.exists(csvFilePath) and os.path.isfile(csvFilePath):
try:
with open(csvFilePath,"r",encoding=fileEncode) as fr:
dataContent=csv.DictReader(fr)
headers=dataContent.fieldnames
next(dataContent)
for dataRow in dataContent:
dataValue.append(dataRow)
except Exception as ex:
raise ex
return dataValue,headers
def SaveCSVFileUseDict(path=os.getcwd(),fileName="testSave.csv",fileEncode="utf8",headers="",content=""):
csvFilePath=path+"\\"+fileName
if os.path.exists(path) and os.path.isdir(path):
try:
with open(csvFilePath,'w+',encoding=fileEncode,newline="") as fw:
dataObj=csv.DictWriter(fw,fieldnames=headers)
dataObj.writeheader()
for item in content:
dataObj.writerow(item)
except Exception as ex:
raise ex
if __name__=="__main__":
path=r"C:\Users\Administrator\PycharmProjects\TestProject\PythonIOTest\csvLesson"
fileName="CSVTestFile.csv"
print("Test save file as csv file")
headers={"ID", "Name", "Author", "ISBN"}
data=[
{"ID":"1","Name":"Python基础教程","Author":"Surpassme","ISBN":1088021365},
{"ID":"2","Name":"Java基础教程","Author":"Surpassme","ISBN":2088021365},
{"ID":"3","Name":"C#基础教程","Author":"Kevin","ISBN":3088021365},
]
SaveCSVFileUseDict(path=path,headers=headers,content=data)
dataFromSaveFile,headers=ReadFromDict(path=path,fileName="testSave.csv")
print(f"header is {headers}")
for item in dataFromSaveFile:
print(item)
以字典形式保存时,需要注意标题即为字典的Key值
- 运行结果如下所示:
Test save file as csv file
header is ['ID', 'Name', 'ISBN', 'Author']
OrderedDict([('ID', '2'), ('Name', 'Java基础教程'), ('ISBN', '2088021365'), ('Author', 'Surpassme')])
OrderedDict([('ID', '3'), ('Name', 'C#基础教程'), ('ISBN', '3088021365'), ('Author', 'Kevin')])
19.3.2.3 自定义分隔符和终止符
如果希望可以自定义分隔符(如Tab),希望有两倍行距,则可以使用delimiter和lineterminator关键字参数。
- 示例代码如下所示:
import csv
import os
def SaveCSVFile(path=os.getcwd(),fileName="test.csv",content="",delimiter=",",lineterminator="\n",fileEncoding="utf8"):
csvFilePath=path+"\\"+fileName
if os.path.exists(path) and os.path.isdir(path):
try:
with open(csvFilePath,"w+",encoding=fileEncoding,newline="") as fw:
dataObj=csv.writer(fw,delimiter=delimiter,lineterminator=lineterminator)
for item in content:
dataObj.writerow(item)
except Exception as ex:
raise ex
if __name__=="__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\csvLesson"
print(f"Test save csv file")
data=[
['ID', 'Department', 'Employees', 'HireDate'],
['1', 'Dev', 'Kevin', '2019-10-30'],
['2', 'Prd', 'Lily', '2019-10-31'],
['3', 'Test', 'Kate', '2019-11-01'],
['4', 'Dev', 'Leo', '2019-11-02'],
['5', 'Prd', 'Lucy', '2019-11-03']
]
SaveCSVFile(path=path,content=data,delimiter="\t",lineterminator="\n\n")
- 运行结果如下所示:

19.3.3 示例项目
假设现在有一个任务,从一个文件夹中删除所有CSV文件的第一行。主要方法如下所示:
- 依次逐个打开CSV文件,删除第一行数据,再保存
- 在网上找找有没有相应的工具
- 自己使用代码编写工具
今天我们就来尝试用Python来解决该任务。先来分析一下,使用代码需要解决的问题点有哪些
- 过滤到文件为CSV类型的文件
- 读取每个文件的全部内容
- 删除CSV文件的第一行,并保存为CSV文件
在使用工具或代码来修改文件时,需要将数据或文件进行备份
详细示例如下所示:
import csv
import os
import shutil
def GetCSVFileList(path,extName=".csv"):
"""
获取CSV文件列表
"""
csvFileList=[]
for r,s,fs in os.walk(path):
for csvFile in fs:
if os.path.isfile(os.path.join(r,csvFile)) and os.path.splitext(os.path.join(r,csvFile))[-1] in extName:
csvFileList.append(os.path.join(r,csvFile))
return csvFileList
def ReadCSVFile(csvFileList,encoding="utf8"):
"""读取CSV文件"""
csvRows=[]
for csvFile in csvFileList:
csvFilePath=(os.path.split(csvFile))[0]+"\\headerRemoved\\"+os.path.basename(csvFile)
try:
with open(csvFile,"r",encoding=encoding) as fr:
csvObj=csv.reader(fr)
for row in csvObj:
if csvObj.line_num==1:
continue
csvRows.append(row)
WriterCSVFile(csvFilePath,csvRows)
csvRows.clear()
except Exception as ex:
raise ex
def WriterCSVFile(path,data,encoding="utf8"):
"""保存CSV文件"""
try:
with open(path,"w+",encoding=encoding,newline="") as fw:
csvWriteObj=csv.writer(fw)
for row in data:
csvWriteObj.writerow(row)
except Exception as ex:
raise ex
def SaveAsDirectory(path,dirName):
"""创建另存文件夹"""
tempDir=path+"\\"+dirName
try:
if os.path.isdir(tempDir) and os.path.exists(tempDir):
shutil.rmtree(tempDir)
os.makedirs(tempDir,exist_ok=True)
else:
os.makedirs(tempDir,exist_ok=True)
except Exception as ex:
raise ex
if __name__=="__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\csvLesson\CSVFile"
SaveAsDirectory(path,"headerRemoved")
csvFiles=GetCSVFileList(path)
ReadCSVFile(csvFiles)
最终的运行效果如下所示:

19.4 YAML读写
19.4.1 YAML简介
YAML是YAML Ain't Markup Language的递归缩写,意思其实是:"Yet Another Markup Language"。YAML 的语法和其他高级语言类似,并且可以简单表达清单、散列表,标量等数据形态。它使用空白符号缩进和大量依赖外观的特色,特别适合用来表达或编辑数据结构、各种配置文件、倾印调试内容、文件大纲,其扩展名为.yml.
19.4.2 基本语法
- 区分大小写
- 使用缩进表示层级关系,同层元素左对齐
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 字串一般不使用引号,但必要的时候可以用引号框住
- 使用双引号表示字串时,可用****进行特殊字符转义
- #表示注释
19.4.3 数据类型
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
- 纯量(scalars):单个的、不可再分的值
19.4.3.1 对象
- 对象通常是键值对形式(key: value),冒号后面要加一个空格。示例如下所示:
key:
ckey1: cvalue1
ckey2: cvalue2
ckey3:
cckey1: ccvalue1
cckye2: ccvalue2
ckey4: cvalue4
或
key: {ckey1: cvalue1, ckey2: cvalue2,ckey3: {cckey1: ccvalue1, cckye2: ccvalue2}, ckey4: cvalue4}
- 使用?+空格表示复杂键,当键是一个列表或键值表时,就需要使用该符号进行表示。示例如下所示:
?
- Red
- Green
- Blue
:
- Color
以上等价于
{[blue, reg, green]: Color}
19.4.3.2 数组
以 - 开头的行表示构成一个数组
- 一维数组
- Red
- Green
- Blue
以上等价于
[ 'Red', 'Green', 'Blue' ]
- 多维数组
-
- Red
- Green
- Blue
-
- apple
- tree
- ocean
以上等价于
[ [ 'Red', 'Green', 'Blue' ], [ 'apple', 'tree', 'ocean' ] ]
- 复杂结构
对象和数组可以组合成更为复杂的结构,示例如下所示:
Person:
- sex:
- man
- woman
- color:
yellow: Asia
white: Europe
balck: Africa
country:
- China
- American
- South Korea
- Russia
City:
-
id: 1
name: shanghai
-
id: 2
name: beijing
以上等价于:
{
Person: [
{
sex: [ 'man', 'woman' ]
},
{
color:
{
yellow: 'Asia',
white: 'Europe',
balck: 'Africa'
}
}
],
country: [ 'China', 'American', 'South Korea', 'Russia' ],
City: [
{
id: 1,
name: 'shanghai'
},
{
id: 2,
name: 'beijing'
}
]
}
19.4.3.3 纯量
纯量是最基本,不能再分割的值,如下所示:
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
示例如下所示:
- 字符串
str:
- test str
- "test \n double " # 可以使用双引号或者单引号包裹特殊字符,双引号不会对特殊字符转义。
- 'test \n double'
- line
newline # 字符串可以拆成多行,每一行会被转化成一个空格
- 'testor'' day' # 单引号之中如果还有单引号,必须连续使用两个单引号转义。
test: | # 多行字符串可以使用|保留换行符,也可以使用 > 折叠换行
def
foo
python: >
def
foo
textblock1: |+ # + 表示保留文字块末尾的换行,- 表示删除字符串末尾的换行。
def
foo
textblock2: |-
def
foo
显示结果如下所示:
str:
[ 'test str',
'test \n double ',
'test \\n double',
'line newline',
'testor\' day' ],
test: 'def\nfoo\n',
python: 'def foo \n',
textblock1: 'def\n\nfoo\n\n',
textblock2: 'def \n\nfoo' }
- 布尔值
isMatch:
- true # true,True都可以
- False # false,False都可以
显示结果如下所示:
isMatch: [ true, false ]
- 整数与浮点数
intNum:
- 123
- 0b11100011
- 0x12A
floatNum:
- 123.25
- 3.1415392e+5
显示结果如下所示:
intNum: [ 123, 227, 298 ]
floatNum: [ 123.25, 314153.92 ]
- Null
isNull: ~ # 使用~表示null
显示结果如下所示:
isNull: null
- 时间与日期
datetime: 2020-01-19T10:34:30+08:00 # 时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
date: 2020-01-19 # 日期必须使用ISO 8601格式,即yyyy-MM-dd
time: 10:34:30
显示结果如下所示:
datetime: Sun Jan 19 2020 10:34:30 GMT+0800 (中国标准时间),
date: Sun Jan 19 2020 08:00:00 GMT+0800 (中国标准时间),
time: 38070,
19.4.4 引用
锚点&和别名*,可以用来引用,示例如下所示:
server: &server
host: 10.68.1.81
username: root
password: password
test:
<<: *server
datebase: test
dev:
<<: *server
database: dev
rel:
<<: *server
database: rel
最终显示的结果如下所示:
{
server:
{
host: '10.68.1.81',
username: 'root',
password: 'password'
},
test:
{
host: '10.68.1.81',
username: 'root',
password: 'password',
datebase: 'test'
},
dev:
{
host: '10.68.1.81',
username: 'root',
password: 'password',
database: 'dev'
},
rel:
{
host: '10.68.1.81',
username: 'root',
password: 'password',
database: 'rel'
}
}
& 用来建立锚点(server),<< 表示合并到当前数据,* 用来引用锚点。
19.4.5 应用场景
- 1、实现简单,解析方便,特别适合在脚本语言中使用
- 2、配置文件,写YAML比XML/ini/JSON快,因为不需要关注标签、引号、括号等
19.4.6 在线验证网址:
http://www.bejson.com/validators/yaml/
19.4.7 YAML的Python读写
19.4.7.1 YAML库安装
在Python常用的读写YAML库有pyyaml和ruamel
- pyyaml安装
pip install -U pyyaml
或
pip3 install -U pyyaml
- ruamel安装
pip install -U ruamel.yaml
或
pip3 install -U ruamel.yaml
19.4.7.2 Python写YAML
19.4.7.2.1 将字典写入YAML文件
示例代码如下所示:
import os
import yaml
def SaveDict2YAML(path,filename,**data):
savePath=os.path.join(path,filename)
with open(savePath,mode="w",encoding="utf8") as fo:
yaml.dump(data,fo,Dumper=yaml.Dumper)
if __name__=="__main__":
testDict={
"server":
{
"host": "10.68.1.81",
"username": "root",
"password": "password"
},
"ower":["test","dev","rel"]
}
path=os.getcwd()
filename="dict2yaml.yaml"
SaveDict2YAML(path,filename,data=testDict)
最终保存的文件如下所示:
data:
ower:
- test
- dev
- rel
server:
host: 10.68.1.81
password: password
username: root
19.4.7.2.2 将列表写入YAML文件
示例代码如下所示:
import os
import yaml
def SaveList2YAML(path,filename,data):
savePath=os.path.join(path,filename)
with open(savePath,mode="w",encoding="utf8") as fo:
yaml.dump(data,fo,Dumper=yaml.Dumper)
if __name__=="__main__":
testList=[
"test",
"dev",
"rel",
{
"server":
{
"host": "10.68.1.81",
"username": "root",
"password": "password"
}
}
]
path=os.getcwd()
filename="list2yaml.yaml"
SaveList2YAML(path,filename,testList)
最终保存的文件如下所示:
- test
- dev
- rel
- server:
host: 10.68.1.81
password: password
username: root
19.4.7.3 Python读YAML
import os
import yaml
import json
def ReadYAML(path,filename):
path=os.path.join(path,filename)
with open(path,mode="r",encoding="utf8") as fo:
data=yaml.load(fo.read(),Loader=yaml.Loader)
return data
if __name__=="__main__":
filename="list2yaml.yaml"
path=os.getcwd()
data=ReadYAML(path,filename)
print(json.dumps(data,indent=3))
最终的打印结果如下所示:
[
"test",
"dev",
"rel",
{
"server": {
"host": "10.68.1.81",
"password": "password",
"username": "root"
}
}
]
如果使用ruamel写YAML文件,需要将Dumper更换一下即可,如下所示:
yaml.dump(data,fo,Dumper=ruamelyaml.RoundTripDumper)
19.5 Excel读写
19.5.1 安装openpyxl模块
Python没有自带openpyxl,需要自行安装,安装方法如下所示:
pip install -U openpyxl
验证是否安装成功
pip list | findstr "openpyxl"
或
pip show openpyxl
返回以下结果即说明安装成功
openpyxl 3.0.0
19.5.2 读取Excel文档
以下示例将使用Excel表格 data.xlsx,使用Excel 2013创建,默认包含3个sheet页,如下所示:

19.5.2.1 使用openpyxl打开Excel文档
详细代码如下所示:
import openpyxl
import os
def getBaseDir(fileName):
return os.path.join(os.path.dirname(__file__),fileName)
def loadWorkbook():
workbook=openpyxl.load_workbook(getBaseDir("data.xlsx"))
print(type(workbook))
loadWorkbook()
openpyxl.load_workbook()接受文件名,返回一个workbook数据类型的值,这个workbook对象代表这个Excel文件。需要注意的是所打开的默认必须位于当前工作目录,否则需要传入完整路径,可使用 os.getcwd()
输出结果:
19.5.2.2 从Workbook中获取Sheet
import openpyxl
import os
def getBaseDir(fileName):
return os.path.join(os.path.dirname(__file__),fileName)
def loadWorkbook():
workbook=openpyxl.load_workbook(getBaseDir("data.xlsx"))
return workbook
def getSheet():
wb=loadWorkbook()
# 获取所有sheet表名
print(wb.sheetnames,type(wb.sheetnames))
# 根据sheet名字获取sheet
print(wb['Sheet2'],type(wb['Sheet2']))
# 获取激活的sheet
print(wb.active,type(wb.active))
if __name__ == '__main__':
getSheet()
输出结果:
['Sheet1', 'Sheet2', 'Sheet3']
19.5.2.3 从sheet页中获取单元格
import openpyxl
import os
def getBaseDir(fileName):
return os.path.join(os.path.dirname(__file__),fileName)
def loadWorkbook():
workbook=openpyxl.load_workbook(getBaseDir("data.xlsx"))
return workbook
def getSheet():
wb=loadWorkbook()
# 获取所有sheet表名
print(wb.sheetnames,type(wb.sheetnames))
# 根据sheet名字获取sheet
print(wb['Sheet2'],type(wb['Sheet2']))
# 获取激活的sheet
print(wb.active,type(wb.active))
def getCellValue():
wb = loadWorkbook()
sheet=wb['Sheet2']
cell=sheet['A1']
# 获取单元格的Value值
print("Row {} Column {} Value {} ".format(cell.row,cell.column,cell.value))
for i in range(1,10):
for j in range(1,3):
print(i,sheet.cell(row=i,column=j).value)
if __name__ == '__main__':
# getSheet()
getCellValue()
输出结果:
Row 1 Column 1 Value A1-A1
1 A1-A1
1 B1-B1
2 A1-A2
2 B1-B2
3 A1-A3
3 B1-B3
4 A1-A4
4 B1-B4
5 A1-A5
5 B1-B5
6 A1-A6
6 B1-B6
7 A1-A7
7 B1-B7
8 A1-A8
8 B1-B8
9 A1-A9
9 B1-B9
19.5.2.4 从表中取得行和列
import openpyxl
import os
def getBaseDir(fileName):
return os.path.join(os.path.dirname(__file__),fileName)
def loadWorkbook():
workbook=openpyxl.load_workbook(getBaseDir("data.xlsx"))
return workbook
def getRowAndColumn():
wb = loadWorkbook()
sheet = wb['Sheet2']
print(tuple(sheet['A1':'B8']))
# 循环每一行
for r in sheet['A1':'B8']:
# 循环每一列
for c in r:
print("Locate is {},value is {}".format(c.coordinate,c.value))
if __name__ == '__main__':
# getSheet()
getRowAndColumn()
运行结果如下:
((, ), (, ), (, ), (, ), (, ), (, ), (, ), (, | ))
Locate is A1,value is A1-A1
Locate is B1,value is B1-B1
Locate is A2,value is A1-A2
Locate is B2,value is B1-B2
Locate is A3,value is A1-A3
Locate is B3,value is B1-B3
Locate is A4,value is A1-A4
Locate is B4,value is B1-B4
Locate is A5,value is A1-A5
Locate is B5,value is B1-B5
Locate is A6,value is A1-A6
Locate is B6,value is B1-B6
Locate is A7,value is A1-A7
Locate is B7,value is B1-B7
Locate is A8,value is A1-A8
Locate is B8,value is B1-B8
| | | | | | | | | | | | | | | | 19.5.3 写入Excel文档
19.5.3.1 创建和保存Excel文档
import openpyxl
import os
def CreateNewWorkbook(path,fileName="test.xlsx"):
workbook=openpyxl.Workbook()
activeSheet=workbook.active
# 给sheet取名字
activeSheet.title="This is test sheet by openpyxl"
print(f"current acvtive sheet is {activeSheet},name is: {activeSheet.title}\nwork book is {workbook['This is test sheet by openpyxl']} ")
# 保存工作簿
workbook.save(path+"\\"+fileName)
if __name__ == "__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
CreateNewWorkbook(path,fileName="SaveAsByOpenpyxl.xlsx")
运行结果如下所示:
current acvtive sheet is ,name is: This is test sheet by openpyxl
work book is

19.5.3.2 创建和删除sheet
import openpyxl
import os
def CreateNewAndDelete(path,fileName="test.xlsx"):
workbook=openpyxl.Workbook()
print(f"init sheetname is:{workbook.sheetnames}")
# 创建Sheet
for i in range(5):
workbook.create_sheet(title="Sheet"+str(i),index=i)
print(f"create sheetname is {workbook.sheetnames}")
# 删除Sheet
for j in range(3):
del workbook['Sheet'+str(j)]
print(f"after delete sheetname is:{workbook.sheetnames}")
# 保存Excel工作簿
workbook.save(path+"\\"+fileName)
if __name__ == '__main__':
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
CreateNewAndDelete(path,fileName="createOrDelSheet.xlsx")
运行结果如下所示:
init sheetname is:['Sheet']
create sheetname is ['Sheet0', 'Sheet1', 'Sheet2', 'Sheet3', 'Sheet4', 'Sheet']
after delete sheetname is:['Sheet3', 'Sheet4', 'Sheet']
19.5.3.3 将值写入单元格
import openpyxl
import os
def CreateNewAndDelete(path,fileName="test.xlsx"):
workbook=openpyxl.Workbook()
for i in range(5):
workbook.create_sheet(title="Sheet"+str(i),index=i)
# 保存Excel工作簿
workbook.save(path+"\\"+fileName)
def InsertValutToExcel(path,fileName,sheetName,insertValue,cellRange):
filePath=path+"\\"+fileName
workbook=openpyxl.load_workbook(filePath)
sheetName=workbook[sheetName]
sheetName[cellRange]=insertValue
print(sheetName[cellRange].value)
workbook.save(filePath)
if __name__ == '__main__':
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
CreateNewAndDelete(path,fileName="createOrDelSheet.xlsx")
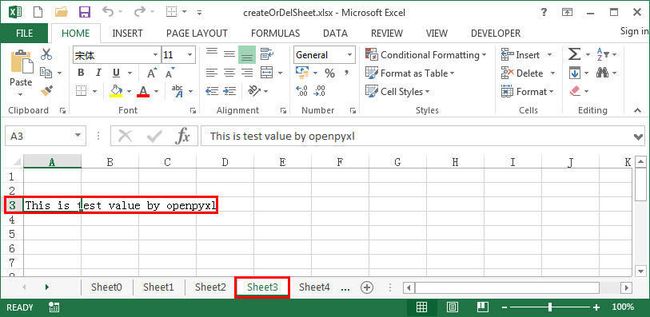
InsertValutToExcel(path=path,fileName="createOrDelSheet.xlsx",sheetName="Sheet3",insertValue="This is test value by openpyxl",cellRange="A3")
运行结果如下所示:
19.5.4 修饰Excel文档
对某些单元格设置字体、样式等,可以起到强调单元格的重要性等。因此需要从openpyxl.styles中导入Font()和Style()函数。
19.5.4.1 设置字体和样式
设置单元格字体样式主要使用Font对象,向其传入关键字参数即可,主要关键字参数如下所示:
| 关键字参数 | 数据类型 | 描述 |
|---|---|---|
| name | string | 字体名称,如Arial/Times New Roman |
| size | int | 字体大小 |
| italic | bool | 是否采用斜体,True代表使用斜体 |
| bold | bool | 是否采用粗体,True代表使用粗体 |
| underline | string | 是否带下划线 |
| vertAlign | string | 垂直对齐方式 |
underline:为固定的参数可选项,如下所示:
- double:双下划线
- single:单下划线
- doubleAccounting:会计双下划线
- singleAccounting:会计单下划线
vertAlign:为固定的参数可选项,如下所示:- baseline:比较基准
- superscript:上标
- subscript:下标
示例代码如下所示:
import os
from openpyxl import Workbook
from openpyxl.styles import colors
from openpyxl.styles import Font,Color
def SetExcelFont(path,fileName):
wb=Workbook()
sheet=wb.active
firstFontObj=Font(name="Arial",size="18",italic=True,bold=True,underline="single",color=colors.RED)
secondFontObj=Font(name="Times New Roman",size="24",bold=True,underline="double",vertAlign="baseline",color=colors.BLUE)
thirdFontObj=Font(name="Calibri",size="24",italic=False,bold=True,underline="doubleAccounting",vertAlign="superscript",color="0099CC00")
fourthFontObj=Font(name="Arial",size="34",italic=False,bold=False,underline="singleAccounting",vertAlign="subscript",color=colors.BLACK)
sheet["A1"].font=firstFontObj
sheet["B1"].font=secondFontObj
sheet["A2"].font=thirdFontObj
sheet["B2"].font=fourthFontObj
sheet["A1"]="hello"
sheet["B1"]="world"
sheet["A2"]="Software"
sheet["B2"]="Test"
wb.save(path+"\\"+fileName)
if __name__=="__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
SetExcelFont(path,fileName="SetExcelFont.xlsx")
运行结果如下所示:

19.5.4.2 添加公式
在Excel文件中,公式通常以=开始,通过其他单元格的计算得到值,使用openpyxl添加公式特别简单,就像直接在Excel文件中添加公式一样,现在有一份成绩单,大于等于90,则评价为优,小于60为不合格,介于60和90为良好,示例代码如下所示:
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl.styles import Font,colors,PatternFill,fills
def AddFormula(path,fileName,sheetName="Sheet1"):
filePath=path+"\\"+fileName
wb=load_workbook(filePath)
ws=wb[sheetName]
for i in range(2,len(ws["B"])+1):
scorePost="B"+str(i)
formulaPos="C"+str(i)
formulaText=f'=IF(B{i}>=90,"优",IF(B{i}<60,"不合格","良好"))'
ws[formulaPos]=formulaText
if int(ws[scorePost].value) >=90:
# 写入公式
ws[formulaPos].font=Font(name="Arial",color=colors.BLACK)
# 进行单元格填充
ws[formulaPos].fill=PatternFill(fill_type=fills.FILL_SOLID,fgColor=colors.GREEN)
elif int(ws[scorePost].value) <60:
ws[formulaPos].font=Font(name="Arial",color=colors.BLACK)
ws[formulaPos].fill=PatternFill(fill_type=fills.FILL_SOLID,fgColor=colors.RED)
else:
ws[formulaPos].font=Font(name="Arial",color=colors.BLACK)
ws[formulaPos].fill=PatternFill(fill_type=fills.FILL_SOLID,fgColor=colors.BLUE)
wb.save(filePath)
if __name__=="__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
AddFormula(path,fileName="AddFormula.xlsx")
运行的结果如下所示:

注意事项
- 如果在调用load_workbook()不带参数data_only=True,则带公式的单元格,在获取单元格内容为其公式,如果仅希望获取单元格值,则需要带上data_only=True参数
19.5.4.3 调整行高和列宽
在Excel中,调整行高和列宽非常容易,今天我们来用代码尝试一下调整行高和列宽。主要涉及到Worksheet对象row_dimensions和column_demiensions。
示例代码如下所示:
from openpyxl import Workbook
def SetHeightAndWidth(path,fileName="test.xlsx"):
filePath=path+"\\"+fileName
wb=Workbook()
ws=wb.active
ws["A1"]="Set Row Heigh"
ws["B1"]="Set Column Widht"
ws.row_dimensions[1].height=80
ws.column_dimensions['B'].width=50
wb.save(filePath)
if __name__=="__main__":
path=r"C:\Users\Surpass\PycharmProjects\PythonIOTest\ExcelLesson"
fileName="SetHeightAndWidth.xlsx"
SetHeightAndWidth(path,fileName=fileName)
运行结果如下所示:

19.6 对象序列化
在Python,如果需要将任意对象保存到磁盘中,必须要进行转换为其相应的格式,如dict类型的数据是不能直接按文本格式保存的。在Python中,能实现任意对象与文本之间的相互转化,同时也可以将任意对象与二进制之间相互转化的称为序列化,使用的模块为pickle。
使用Python的pickle操作,可以将对象序列化字符串、文件等类似于文件的任意对象;也可以将这些字符串、文件或任意类似于文件的对象还原为原来的对象。
19.6.1 pickle模块方法
pickle模块中,常用的方法如下所示:
- dumps:将Python中的对象序列化二进制对象
- loads:从指定的pickle数据读取并返回对象
- dump:将Python中的对象序列化二进制对象,并保存为文件
- load:读取指定的序列化数据文件,并返回对象
以上4个方法又可以分为两类:
- dumps和loads:是基于内存的Python对象与二进制相互转化
- dump和load:是基于文件的Python对象与二进制相互转化
19.6.2 dumps和dump
19.6.2.1 dumps
dumps其主要功能:将Python对象转换为二进制,方法的详细定义如下所示:
dumps(obj, protocol=None, *, fix_imports=True)
- obj:要转换的Python对象
- protocol:pickle的转码协议,取值0、1、2、3、4,默认为3。
-
- 0:ASCII码
-
- 2:旧版本的二进制协议
-
- 3:新版本的二进制协议
-
- 4:更新版本的二进制协议
19.6.2.2 dump
dumps其主要功能:将Python对象转换为二进制文件,方法的详细定义如下所示:
dump(obj, file, protocol=None, *, fix_imports=True)
- obj:要转换的Python对象
- file:序列化后要保存的文件
- protocol:pickle的转码协议,取值0、1、2、3、4,默认为3。
-
- 0:ASCII码
-
- 2:旧版本的二进制协议
-
- 3:新版本的二进制协议
-
- 4:更新版本的二进制协议
序列化的文件扩展名为pkl
19.6.3 loads和load
19.6.3.1 loads
loads其主要功能:将二进制对象转换为Python对象,方法的详细定义如下所示:
loads(s, *, fix_imports=True, encoding="ASCII", errors="strict")
- s:要转换的二进制对象
在将二进制对象反序列化为Python对象时,会自动识别转码协议,一般不需要传入转码协议参数值。当待转换的二进制对象的字节数据超过pickle的Python对象时,多余的字节将被忽略。
19.6.3.2 load
load其主要功能:将二进制对象文件转换为Python对象,方法的详细定义如下所示:
load(file, *, fix_imports=True, encoding="ASCII", errors="strict")
- file:二进制对象文件
19.6.4 pickle示例
1.dumps和loads
>>> import pickle
>>> tempDict={"a":1,"b":2,"c":3}
>>> pA=pickle.dumps(tempDict)
>>> pA
b'\x80\x03}q\x00(X\x01\x00\x00\x00aq\x01K\x01X\x01\x00\x00\x00bq\x02K\x02X\x01\x00\x00\x00cq\x03K\x03u.'
>>> pB=pickle.loads(pA)
>>> pB
{'a': 1, 'b': 2, 'c': 3}
2.dump和load
import os
import pickle
def saveAsPickleObj(path:str,data:str,filename="Serialization.pkl"):
savePath=os.path.join(path,filename)
try:
with open(savePath,"wb",pickle.HIGHEST_PROTOCOL) as fo:
pickle.dump(data,fo)
except Exception as ex:
print(f"save error\n{ex}")
def readPickleObj(path:str,filename):
filePath=os.path.join(path,filename)
flag= True if all((os.path.exists(filePath),os.path.isfile(filePath))) else False
if flag:
try:
with open(filePath,mode="rb") as fo:
result=pickle.load(fo)
except Exception as ex:
print(f"read error\n{ex}")
else:
return result
if __name__ == '__main__':
tempDict={"a":1,"b":2,"c":3}
path=os.getcwd()
filename="sample.pkl"
saveAsPickleObj(path,tempDict,filename)
result=readPickleObj(path,filename)
print(result)
代码运行完成之后,会目录生成一个sample.pkl文件。
https://www.cnblogs.com/surpassme/p/13034972.html
本文同步在微信订阅号上发布,如各位小伙伴们喜欢我的文章,也可以关注我的微信订阅号:woaitest,或扫描下面的二维码添加关注:
