使用Tesseract训练图片的方法
所需要的工具:
Tesseract4.0(windows版本于2017年1月30号发布),据说windows版本会有很多诡异的Bug;
java7以上版本,为安装jTessBoxEditor做准备;
jTessBoxEditor,用于标定数据,此软件依赖于java;
准备一些需要识别的目标图片,应该能够覆盖所有需要识别的字符;
训练新字体对图片的预处理和要求:
同tesseract OCR识别对图片有要求一样,在训练新的字符集或新的字体时,对图片也有一定要求,符合要求的图片,能大大提高训练的效率。
在图像处理方面,去除噪声,使训练的字符图片尽量连贯、清晰。
其他方面,通常的要求如下:
1. 在一幅图片内,字体统一,决不能将多种字体混合出现在一幅训练图片内;如果不是通过扫描文本获取的字符图片,这个条件很容易被忽视。
2. 理想条件下,同种字体的字符图片集中到一幅大的训练图片中,在同一页内;
3. 要保留一定的字符间距与行间距;
4. 字符高度(大小),只要满足高度最小条件即可,对于小写字符x,其高度要至少大于10个像素,一般统一采用一种大小即可,tesseract engine默认的training数据集也是一种大小;
5. 对于非字母字符,如!@#$%^&(),.{}<>/?,不要集中在一起出现,原因是这样不利于tesseract找出 文本行基线baseline,不利于文本高度及大小的检测,baseline检测是tesseract engine的第一步;
6. 一般每个字符需要10个样本,高频常见字符至少20个样本,不常见字符需要5个样本;
7. 对于同种字体,多页训练图片,可以在训练中,件用相同的方式合并tr文件和box文件,两类文件内的字符次序要相同,利于提高训练效果。
在获取训练字符图片方面,不一定非要从待识别图片中收集,可以利用word字符集找到对应字体,打印,扫描,获取训练图片,简单、方便。这个根据实际情况来应用。
资源文件(后缀为.traineddata文件)是什么?
可以通过以下命令,打开eng资源文件到english文件中:
combine_tessdata -u /usr/share/tesseract-ocr/tessdata/eng.traineddata english/eng
可以看到如下界面
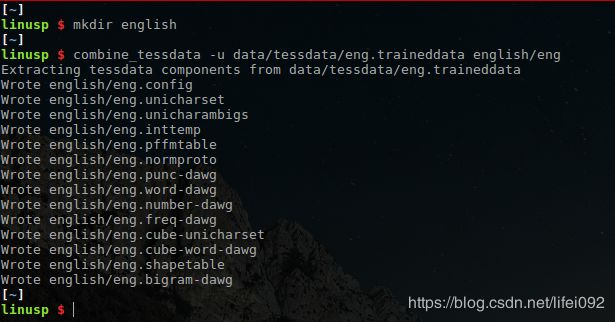
可以看到,这个资源文件里包含了很多东西,这些文件各自的意义为:
- config: 配置文件
- unicharset: 字符集文件,所谓 "字符集" 即是所有可被识别的字符的集合
- unicharambigs: 识别歧义修正文件
- inttemp: 每个字符的 "原型" ,或者是 "标准型" ,当然啦,这里面其实是包含了字符的各种特征,并不是一个标准的 "字符图像"
- pffmtable: 指明了每个字符的特征数量
- normproto: 项目网站上的说法是 "normalization sensitivity prototypes" ,不知道怎么翻译合适
- 以 dawg 结尾的文件: 有向非循环词图(Directed Acyclic Word Graph, DAWG)文件,用来增强、调整识别过程
- cube-unicharset, cube-word-dawg: 用于 Tesseract 内部名为 CUBE 的识别引擎,无资料,不详
- shapetable: 同样是个不知道如何翻译的家伙,反正项目网站上说这个文件已经不需要使用(但还得有这个文件),就不纠结了
通过以下命令可以再将这些文件进行打包:
combine_tessdata eng
经过尝试,以下五个文件必不可少:
- unicharset
- inttemp
- pffmtable
- normproto
- shapetable
训练的过程就是为了产生这些文件
unicharset_extractor 命令用于产生unicharset文件即字符集文件;
font_properties文件信息释义:
第一个字段为字体名称,名称中不能有空格,名称可以任意,但建议尽量贴近字体在操作系统上的名称,后面五个字段分别表示:
- 该字体是否有斜体
- 该字体是否有粗体
- 该字体是否有无衬线体
- 该字体是否有衬线体
- 该字体是否有哥特体
训练方法步骤:
1) 准备一些需要识别的目标图片,应该能够覆盖所有需要识别的字符;
2) 图片必须为tiff格式,否则无法进行以下步骤;
3) 合并多个tif文件为一个,这里需要用到一个软件jTessBoxEditor;
4) 双击.bat文件运行jTessBoxEditor软件;

5) 打开“Tools->Merge TIFF...”,选择多个tif文件,保存为name.tif,所有下面的“name”,就是你所取的识别引擎文件的名字,可以改成你自己的。name的格式为 [lang].[fontname].exp[num]
lang为语言,fontname为字体类型(自定义),num为数字(0,1,2,3,...)

6) 输入以下命令,生成box文件,该文件记录了tesseract识别出来的每一个字和其位置坐标;
![]()

7) 使用jTessBoxEditor打开name.tif文件,需要记住的是第2步生成的name.box要和这个name.tif文件同在一个目录下。逐个校正文字,后保存。
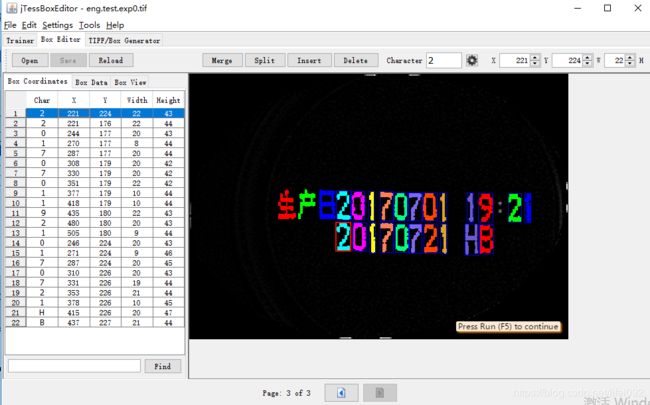

8) 通过以下命令,生成特征文件(unicharset文件);
a) 生成tr文件
//tesseract.exe [tif图片文件名] [生成的tr文件名] nobatch box.train
tesseract.exe chi.fangzheng.exp0.tif chi.fangzheng.exp0 nobatch box.train

b) 生成Character集合
//unicharset_extractor.exe [box文件名]
unicharset_extractor.exe chi.fangzheng.exp0.box

9) 聚集;
首先,创建字体特征文件,新建文件“font_properties”,并输入文本:name 0 0 0 0 0;
其次,上一步的特征文件生成后,需要将同样文字的不同字体的特征聚集到一起来产生该文字的一个 原型 ,这一步需要执行三个命令:
shape_clustering -F font_properties -U unicharset *.tr
这一步将会生成一个名为 shapetable 的文件。
mftraining -F font_properties -U unicharset -O banker.unicharset *.tr
这一步将会生成一个名为 inttemp文件和pffmtable文件。
cntraining *.tr
这一步将会生成一个名为normproto 的文件。
10) 合并数据文件(打包)
首先,需要将unicharset, inttemp, normproto, pfftable,shapetable这五个文件加上前缀“name.”
然后执行以下命令:
combine_tessdata name.
本例中的name为eng.test.exp0

需确认打印结果中的 Offset 1、3、4、5、13 这些项不是 -1。这样,一个新的语言文件就生成了。
至此,训练过程结束。
此时目录下“name.traineddata”的文件拷贝到tesseract程序目录下的“tessdata”目录。
以后就可以使用该该字典来识别了,例如:
//tesseract [图片文件名] [需要输出的文本文档的文件名] -l [识别的语言] tesseract chi.fangzheng.exp0.tif out -l chi
或者 tesseract.exe test.jpg out –l name -psm 7
将生成的文件name.traineddata拷贝到linux相应的目录下,一样可以使用,整个训练过程最麻烦的就是使用jTessBoxEditor进行文字的校正(即标注),需要非常耐心,这样识别结果就会大大提高。