R语言统计分析篇
1.描述性统计分析
(1)方法云集
通过summary,sapply()计算描述性统计量
vars<-c("mpg","hp","wt")
vars
head(mtcars[vars])
#通过summary()函数来获取描述性统计量
summary(mtcars[vars])
#sapply()函数,格式:sapply(x,FUN,options)x:数据框或矩阵;FUN:为任意的函数;options:若被指定,则将被传递给FUN
#通过sapply()计算描述性统计量
mystats<-function(x,na.omit=FALSE){
if(na.omit)
x<-x[!is.na(x)]
m<-mean(x)
n<-length(x)
s<-sd(x)
skew<-sum((x-m)^3/s^3)/n
kurt<-sum((x-m)^4/s^4)/n-3
return(c(n=n,mean=m,stdev=s,skew=skew,kurtosis=kurt))
}
sapply(mtcars[vars],mystats)
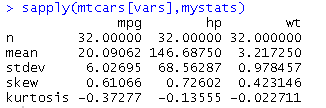
通过Hmisc包中的describe()函数计算描述性统计量
library(Hmisc)
describe(mtcars[vars])
通过pastecs包中的stat.desc()函数计算描述性统计量
格式:stat.desc(x,basic=TRUE,desc=TRUE,norm=FALSE,p=0.95)
| x | 是一个数据框或时间序列 |
| basic=TRUE | 计算其中所有值、空值、缺失值的数量 以及最小值 、最大值、值域还有总和 |
| desc=TRUE | 计算中位数、平均数、平均数的标准误, 平均数置信度为95%的置信区间、方差、标准差以及变异系数 |
| norm=TRUE | 返回正态统计量,包括信度和峰度(以及它们的统计显著程度) 及Shapiro-Wilk正态检验结果 |
| p |
library(pastecs)
stat.desc(mtcars[vars])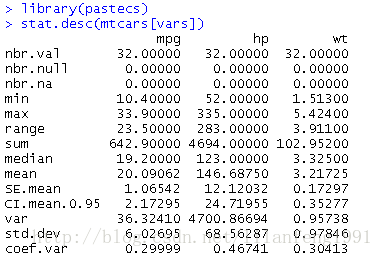
通过psych包中的describe()计算描述性统计量
可计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值的标准误
library(psych)
describe(mtcars[vars])

(2)分组计算描述性统计量
使用aggregate()分组获取描述性统计量
注意:aggregate()仅允许在每次调用中使用平均数、标准差这样的单返回值函数
aggregate(mtcars[vars],by=list(am=mtcars$am),mean)
aggregate(mtcars[vars],by=list(am=mtcars$am),sd)
使用by()分组计算描述性统计量
by(data,INDICES,FUN)
dstats<-function(x)(c(mean=mean(x),sd=sd(x)))
by(mtcars[vars],mtcars$am,dstats)使用doBy包中的summaryBy()分组计算概述统计量
library(doBy)
summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mystats)
使用psych包中的describe.by()分组计算概述统计量
library(psych)
describeBy(mtcars[vars],mtcars$am)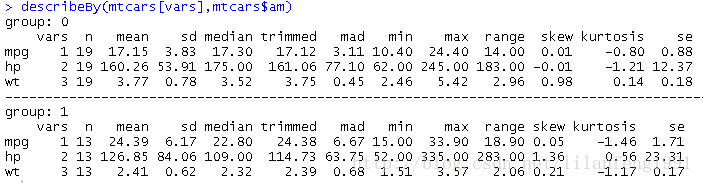
使用reshape包分组计算概述统计量
library(reshape)
dstats<-function(x)(c(n=length(x),mean=mean(x),sd=sd(x)))
dfm<-melt(mtcars,measure.vasrs=c("mpg","hp","wt"),id.vars=c("am","cyl"))
cast(dfm,am+cyl+variable~.,dstats)2.频数表和列联表
(1)生成频数表
用于创建和处理列联表的函数
| 函数 | 描述 |
| table(var1,var2,…,varN) | 使用N个类别变量(因子) 创建一个N维列联表 |
| xtabs(forula,data) | 根据一个公式和一个矩阵或数据框创建一个N维列联表 |
| prop.table(table,margins) | 依margins定义的边际列表中条目表示为分数形式 |
| margin.table(table,margins) | 依margins定义的边际列表计算表中条目的和 |
| addmargins(table,margins) | 将概述边margins放入表中 |
| ftable(table) | 创建一个紧凑的”平铺“式列联表 |
(2)一维列联表
eg
install.packages("vcd")
library(vcd)
mytable<-with(Arthritis,table(Improved))
mytable
#使用prop.table()将频数转化为比例值:
prop.table(mytable)
#使用prop.table()*100转化为百分比
prop.table(mytable)*100
(3)二维列联表
table()
mytable<-xtabs(~Treatment+Improved,data=Arthritis)
mytable
#可以使用margin.table()和prop.table()函数分别生成边际频数和比例
margin.table(mytable,1) #下标1指代table()语句中的第一个变量
prop.table(mytable,1)
#列和列比例可以这样计算
margin.table(mytable,2)#下标2指代table()语句中的第二个变量
prop.table(mytable,2)
#各单元所占比例可用如下语句获取
prop.table(mytable)
#可使用addmargins()函数为表格添加边际和;使用addmargins()时,默认行为是为表中所有的变量创建边际和
addmargins(mytable)
addmargins(prop.table(mytable))
#仅添加各行的和
addmargins(prop.table(mytable,1),2)
#仅添加各列的和
addmargins(prop.table(mytable,2),1)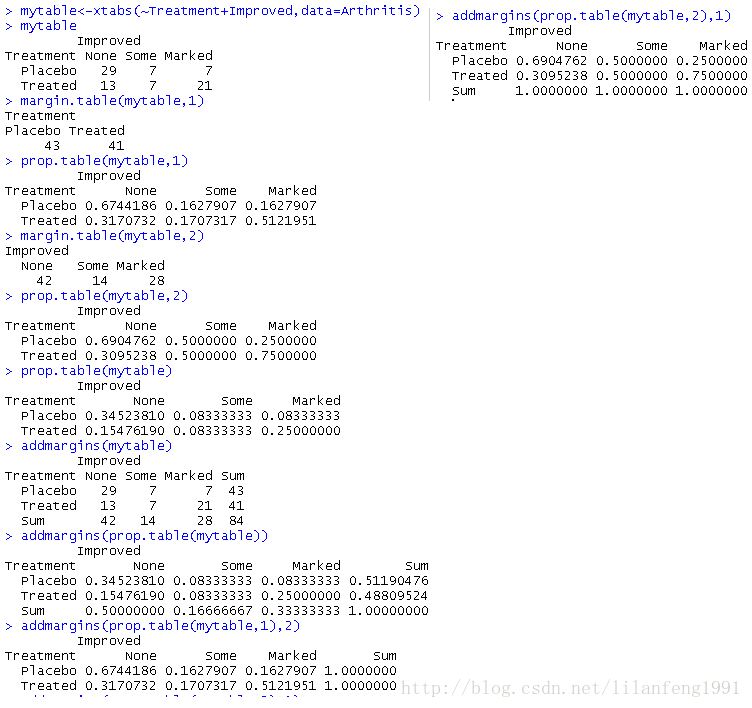
使用CrossTable生成二维列联表
install.packages("gmodels")
library(gmodels)
CrossTable(Arthritis$Treatment,Arthritis$Improved)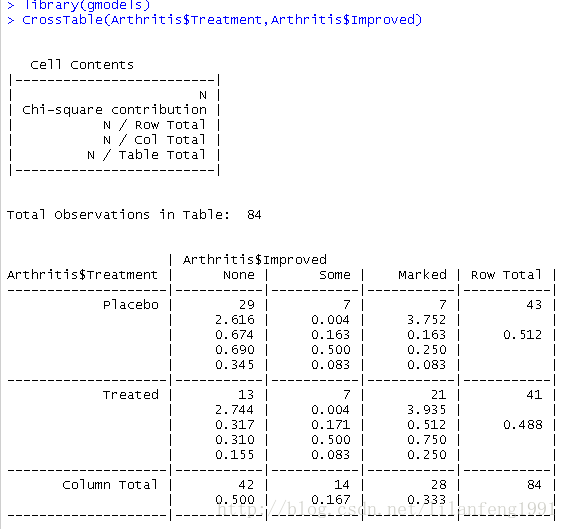
(4)多维列联表
table()
xtabs()
margin.table()
prop.table()
addmargins()
ftable()
eg:
mytable<-xtabs(~Treatment+Sex+Improved,data=Arthritis)
mytable
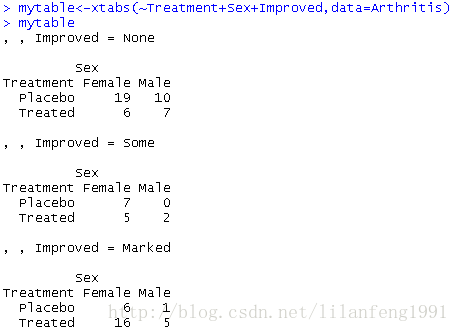
ftable(mytable)
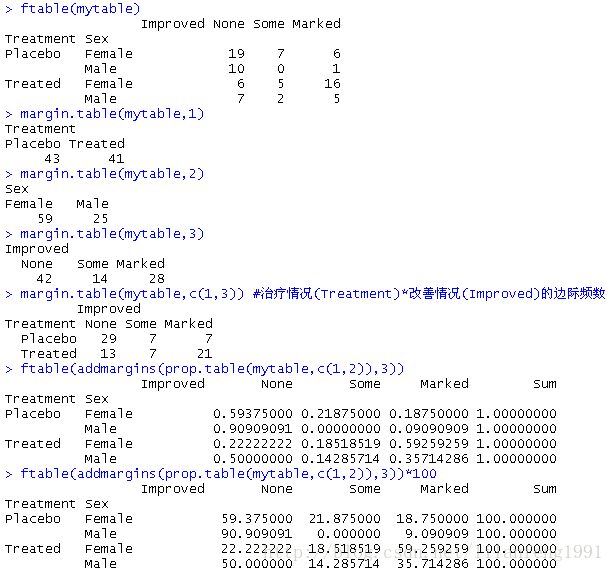
mytable<-xtabs(~Treatment+Sex+Improved,data=Arthritis)
mytable
ftable(mytable)
margin.table(mytable,1)#边际频数
margin.table(mytable,2)
margin.table(mytable,3)
margin.table(mytable,c(1,3)) #治疗情况(Treatment)*改善情况(Improved)的边际频数
ftable(prop.table(mytable,c(1.2))) #Treatment * Sex 的各类改善情况比例
ftable(addmargins(prop.table(mytable,c(1,2)),3))
ftable(addmargins(prop.table(mytable,c(1,2)),3))*100 #得到百分比而不是比例,可将结果乘以100
(5)独立性检验
| 名称 | 原理 | 函数 |
| 卡方独立性检验 | 对二维表的行变量和列变量进行卡方独立性检验 | chisq.test() |
| Fisher精确检验 | 边界固定的列联表中行和列是相互独立的 注意:与许多统计软件不同的是,这里fisher.test()函数可以在任意行列数大于等于2的二维旬联表上使用,但不能用于2*2的列表 |
fisher.test() |
| Cochran-Mantel-Haenszel检验 | 两个名义变量在第三个变量的每一层中都是条件独立的 | mantelhaen.test() |
library(vcd)
mytable<-xtabs(~Treatment+Improved,data=Arthritis) #Treatment和Improved是否独立
chisq.test(mytable)
mytable<-xtabs(~Improved+Sex,data=Arthritis)
chisq.test(mytable)

mytable<-xtabs(~Treatment+Improved,data=Arthritis) fisher.test(mytable)

mytable<-xtabs(~Treatment+Improved+Sex,data=Arthritis)
mantelhaen.test(mytable)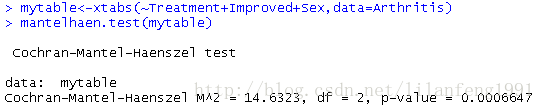
(6)相关性的度量
若变量间不独立,衡量相关性强弱的相关性度量
library(vcd)
mytable<-xtabs(~Treatment+Improved,data=Arthritis)
assocstats(mytable)
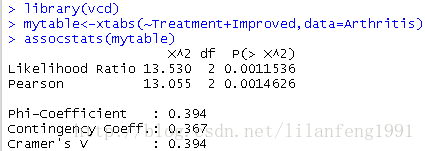
较大的值意味着较强的相关性
vcd包中也提供了一个kappa()函数,可以计算混淆矩阵的Cohen's kappa值以及加权的kappa值(混淆矩阵可表示两位遮天盖地者对于一系列对象进行分类 所得结果的一致程度)
(7)结果可视化
将表转换为扁平格式
通过table2flat将表转换为扁平格式
table2flat<-function(mytable){
df<-as.data.frame(mytable)
rows<-dim(df)[1]
cols<-dim(df)[2]
x<-NULL
for(i in 1:rows){
for(j in 1:df$Freq[i]){
row<-df[i,c(1:(cols-1))]
x<-rbind(x,row)
}
}
row.names(x)<-c(1:dim(x)[1])
return(x)
}
table2flat(mytable)
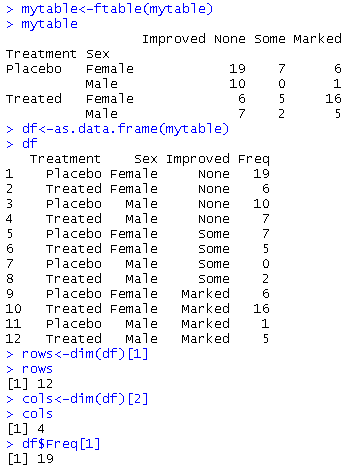
mytable<-xtabs(~Treatment+Sex+Improved,data=Arthritis)
mytable
mytable<-ftable(mytable)
df<-as.data.frame(mytable)
df
rows<-dim(df)[1]
rows
cols<-dim(df)[2]
cols
df$Freq[1]
3.相关
(1)相关类型
| 相关类型 |
定义 |
函数 |
| Pearson积差相关系数 |
衡量两个定量变量之间的线性相关程度 |
cor(x,use=,method=pearson) |
| Spearman等级相关系数 |
衡量分级定序变量之间的相关程度 |
cor(x,use=,method=spearman) |
| Kendall's Tau相关系数 |
是一种非参数的等级相关度量 |
cor(x,use=,kendall) |
(2)协方差和相关系数
states<-state.x77[,1:6]
states
cov(states)
cor(states)
cor(states,method="spearman")(3)偏相关
偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系,
可使用ggm包中的pcor()函数计算偏相关系数
函数调用格式为:
Pcor(u,S)
其中u是一个数值向量,前两个数值表示要计算相关系数的变量下标,其余的数值为条件变量(即要排除影响的变量)的下标。
S为变量的协方差阵
Eg:
install.packages("ggm")
library(ggm)
pcor(c(1,5,2,3,6),cov(states))(4)相关性的显著性检验
格式:
Cor.test(x,y,alternative=,method=)
cor.test(states[,3],states[,5]) #cor.test每次只能检验一种相关关系,psych包中提供的corr.test()可一次做更多的事
psych包中的pcor.test()函数可以用来检验在控制一个或多个额外变量时两个变量之间的条件独立性,
格式为:pcor.test(r,q,n)
R是由pcor()函数计算得到的偏相关系数
Q为要控制的变量数(以数值表示位置)
N为样本的大小
4.t检验
(1)独立样本的t检验
检验的调用格式为:
t.test(y~x,data)
eg
library(MASS)
t.test(Prob~So,data=UScrime)(2)非独立样本的t检验
在两组的观测之间相关时,获得的是一个非独立组设计(dependent groups design)
前-后测设计(pre-post design)
重复测量设计(repeated measures design)
调用格式:
t.test(y1,y2,paired=TRUE)
eg
library(MASS)
sapply(UScrime[c("U1","U2")],function(x)(c(mean=mean(x),sd=sd(x))))
with(UScrime,t.test(U1,U2,paired=TRUE))
若想在多于两个的组之间进行比较,若假设数据是从正态总体中独立抽样而得的,可使用方差分析(ANOVA)
5. 组间差异的非参数检验
(1)两组的比较
library(MASS)
with(UScrime,by(Prob,So,median))
wilcox.test(Prob~So,data=UScrime)
(2)多于两组的比较
若无法满足ANOVA设计的假设,可以使用非参数方法来评估组间的差异。
若各组独立,Kruskal-Wallis检验是一种实用的方法
若各组不独立(如重复测量设计或随机区组设计),则Friedman检验更合适
Kruskal-Wallis调用格式为:kruskal.test(y~A,data) (y是数值型 结果变量,A是一个分组变量,而B是一个用以认定匹配观测的区组变量(blocking variable))
states<-as.data.frame(cbind(state.region,state.x77))
kruskal.test(Illiteracy~state.region,data=states)

非参数多组比较
install.packages("npmc")
library(npmc)
class<-state.region
var<-state.x77[,c("Illiteracy")]
mydata<-as.data.frame(cbind(class,var))
rm(class,var)
summary(npmc(mydata),type="BF")
aggregate(mydata,by=list(mydata$class),median)