字符串 ac自动姬
前言
省选临近,不能再颓了! 说着开始研究起moonlight串流。真香
本期博客之所以在csdn上发了一份,因为没有图床!如果有图床我一定会自力更生的!
好像和字符串没有毛关系
总之,为了备考省选,特地温习了一下ac自动姬
介绍
ac自动姬是一种多模匹配算法。说的直白一点,就是kmp的升级版,同时进行多个kmp。

说是多个kmp,其实它更多的借鉴的是kmp的思想,而不是算法。不会kmp可能可以理解ac自动姬,就像是不会加法也有可能理解乘法(多个加法);但是像线段树和树链剖分就有着严格的先后顺序,不可能在没有掌握线段树时就能理解树链剖分。
注:
- trie树为必备知识,不懂trie树的童鞋请先学习trie树!(●ˇ∀ˇ●)
- kmp为
非必备,学习完kmp再学习ac自动姬会更加深刻的理解
理论中的理论部分
对于多模匹配,我们肯定需要将模式串存储下来。怎么存?trie树呗
我们以一下模式串作为例子:
test
testt
est
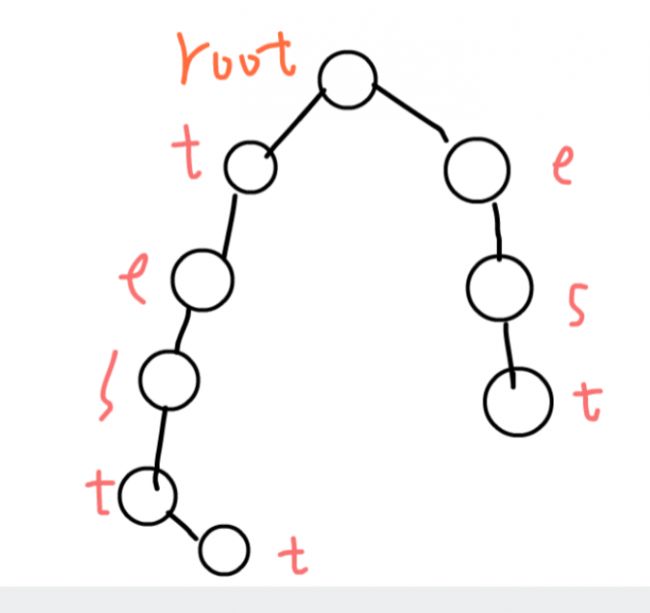
好了,用trie树,我们把所有的模式串存了下来。
存完模式串,我们就开始匹配。随着主串的不断匹配,我们可以将匹配结果归纳如下:
-
假如当前匹配节点存在通向下一个节点的边,那么就转移
-
否则就是找不到下一个节点,那么就要按照失配来处理
这时就需要引入一种概念,“失配指针”。
什么是失配指针?失配指针就是当前点失配后,转移到的另外一个节点。(不太好理解,接着看下去)参照kmp理解一下失配指针
| 对象 | kmp | ac自动姬 |
|---|---|---|
| 失配指针 | 最长公共前后缀的坐标 | trie树深度最深的合法坐标 |
还是不好理解?我们先把上述例子中的失配指针构建出来

照着图接着分析分析
参照kmp单模匹配。在kmp中,相当于只有左侧(\(root \Rightarrow t \Rightarrow e \Rightarrow s \Rightarrow t\))的这一条链。我们不断的找“最长公共前后缀”,是为了最大化利用我们已经匹配过的部分。
我们之所以要找“公共前后缀”,就是为了使得下一次匹配的对象是合法的。后缀与前缀重合,说明这段后缀可能作为下一个匹配的前缀被利用
而我们之所以要找“最长”的那一个,就是为了最大化的利用这个信息。假如当前公共前后缀存在不同的两个,且\(l_1
提供样例:ababa
“aba”与“a”分别是两个公共前后缀
“a”包含在“aba”中
好了,情况扩展到了ac自动姬多模匹配上。在多模匹配上就相当于提供了更多的可能来实现“最长公共前后缀”,一定要在保证“公共前后缀”的基础上尽可能“最长”,这样才能不浪费已经匹配出来的信息
理论中的代码部分
好了,基础的理论有了,我们就要开始实现。
回顾算法,主要难点分为两部分:构建fail指针和匹配
构建fail指针
显然,我们在构建一个某一个节点的fail指针时,一定要事先求出来了所有深度小于这个节点的fail指针。换言之所有的fail只和深度小于这个点的节点有关联。
所有深度一致的先搜出来,保证深度按递增顺序搜出来...BFS!! 不难发现BFS就可以完美满足所有上述要求
我们取奔波最远的一个指针作为例子
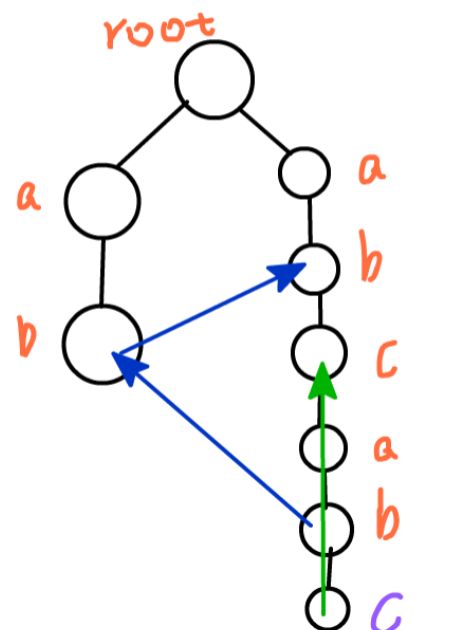
在这个例子中,紫色的c为了获得fail指针,一共移动了两次
第一次:从c的父节点的fail指针开始寻找,发现第一个"b"下面并没有"c",接着转移
第二次:转移到了第二个b,发现这次,b下面接了一个c,那么就为这个c找到了失配指针
否则,假如到头了仍然没有找到,就将fail指针设为root即可
代码:
void getfail(){
//单独处理根节点
fail[root]=-1;
queue line; line.push(root);
while(!line.empty()){
int u=line.front(); line.pop();
for(int i=0;i<=25;++i){
if(ch[u][i]){ //假如u节点后面跟着i节点
line.push(ch[u][i]);
int tmp=fail[u];
//如果一下就到头了
if(tmp==-1){
fail[ch[u][i]]=root;
}
//否则尝试匹配
else{
while(tmp!=root&&!ch[tmp][i]{
tmp=fail[tmp];
}
if(tmp!=root||ch[tmp][i]){
fail[ch[u][i]]=ch[tmp][i];
}
else{
fail[ch[u][i]]=root;
last[ch[u][i]]=root;
}
}
}
}
}
}
匹配
好了,fail指针也构建完了,就可以开始匹配了
-
假如当前匹配节点存在通向下一个节点的边,那么就转移
-
否则就是找不到下一个节点,那么就要按照失配来处理
(搬过来~~)
我们知道怎么转移之后还有一个重要的问题:怎么统计?
从一个节点,通过fail指针遍历到的字串一定是该串的一个后缀,而鬼知道哪一个字串会被模式串匹配上,所以统计一定是随匹配转移时刻进行的。
而且,fail指针的转移的过程中,一定会遍历到所有被当前串包含的公共前后缀。因此可以保证正确性。
由于建trie树的时候记录了以某一点结尾的权值,故沿途加上所有权值即可。
代码如下:
void kmp(string a){
//转移部分
int len=a.size();
int u=root;
for(int i=0;ilast优化
在转移过程中,会遇到很多权值为0(模式串中不包含),但fail指针却跳到了,导致fail指针要大量跳过一些对答案没有用的节点。
last优化就是要想法设法避免这件事。由于权值为0的fail指针是毫无意义的,那么就设last指针必定跳向一个权值不为0的指针
假如(fail指针所指向的点,其权值大于零)
last指针就是fail指针
否则
last指针就是fail指针指向的点的last指针
简单的实现:
last[u]=dot[fail[u]]?fail[u]:last[fail[u]];
总结
至此,ac自动姬已经从理论到代码都有了完整的实现一举,参考代码如下:
该代码记录的是
struct trie{
static const int MAX=3e5+6;
int cnt,tot,root;
int ch[MAX][26],fail[MAX],last[MAX],dot[MAX];
void clean(){
cnt=0; tot=0; root=0;
memset(ch,0,sizeof(ch));
memset(fail,0,sizeof(fail));
memset(last,0,sizeof(last));
memset(dot,0,sizeof(dot));
}
void insert(string a){
tot++;
int len=a.size();
int u=root;
for(int i=0;i line; line.push(root);
while(!line.empty()){
int u=line.front(); line.pop();
for(int i=0;i<=25;++i){
if(ch[u][i]){
line.push(ch[u][i]);
int tmp=fail[u];
if(tmp==-1){
fail[ch[u][i]]=root;
last[ch[u][i]]=root;
}
else{
while(tmp!=root&&!ch[tmp][i]){
tmp=fail[tmp];
}
if(tmp!=root||ch[tmp][i]){
fail[ch[u][i]]=ch[tmp][i];
last[ch[u][i]]=dot[fail[ch[u][i]]]?fail[ch[u][i]]:last[fail[ch[u][i]]];
}
else{
fail[ch[u][i]]=root;
last[ch[u][i]]=root;
}
}
}
}
}
}
int kmp(string a){
int len=a.size(),ans=0;
int u=root;
for(int i=0;i 后记
深夜里又打了6e3个字..(>人<;)
希望通过这篇博客,能为自己和所有看到的人提供一点思路(´▽`ʃ♡ƪ)