JVM 菜鸟进阶高手之路九(解惑)
关于MAT工具相关知识解惑
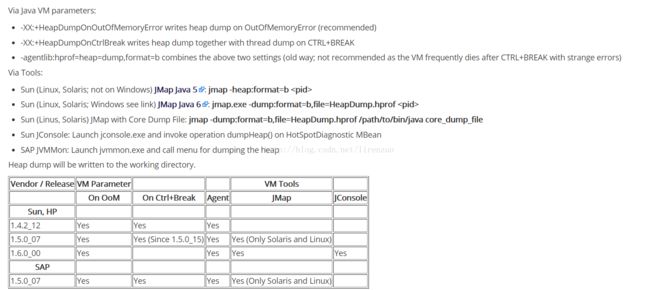
jmap -dump:format=b,file=heap.bin pid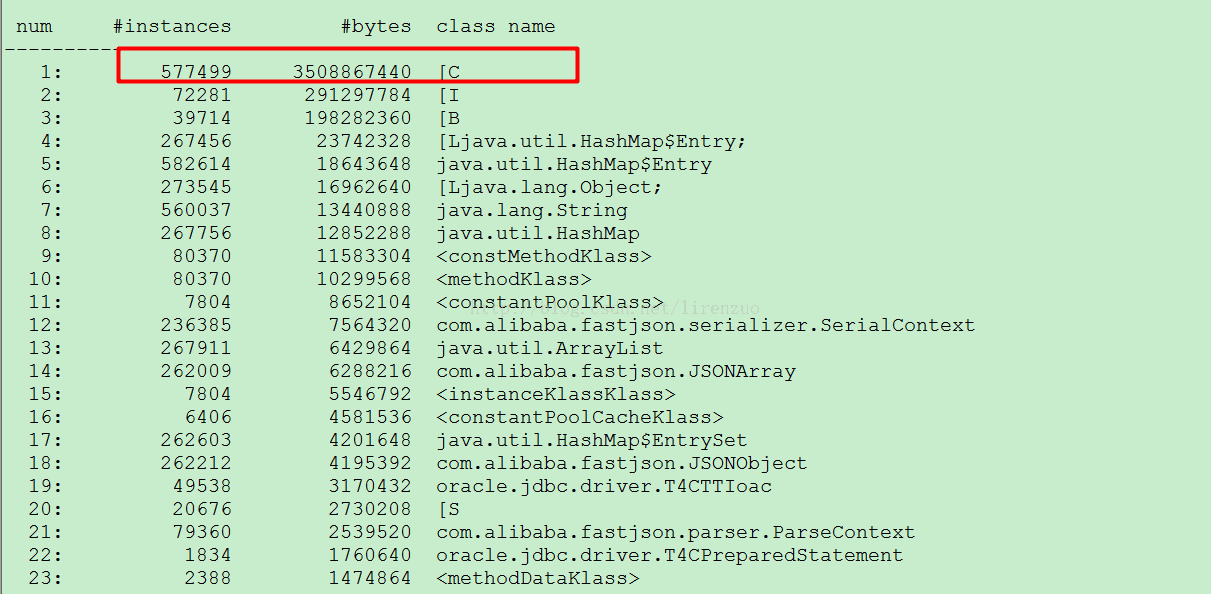
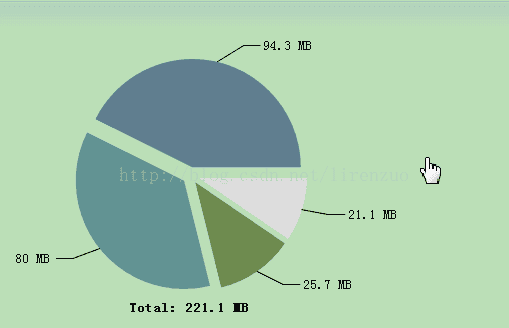 有没有觉得很奇怪,明明4G的堆,dump文件也是4G多,为什么用MAT打开就220M左右????? 奇怪吧,我也疑惑好久,因为因为MAT把不可达对象没加在里面,如果需要显示在MAT工具进行选择设置即可,如下:
有没有觉得很奇怪,明明4G的堆,dump文件也是4G多,为什么用MAT打开就220M左右????? 奇怪吧,我也疑惑好久,因为因为MAT把不可达对象没加在里面,如果需要显示在MAT工具进行选择设置即可,如下: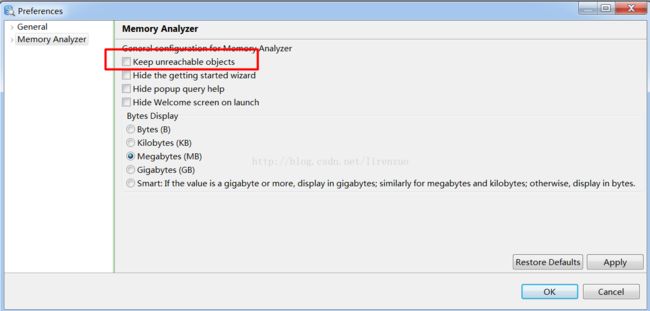
关于第八篇Xmn问题

time ls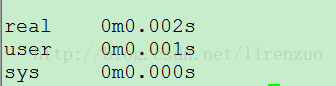
Real, User and Sys process time statistics
One of these things is not like the other. Real refers to actual elapsed time; User and Sys refer to CPU time used only by the process.
Real is wall clock time - time from start to finish of the call. This is all elapsed time including time slices used by other processes and time the process spends blocked (for example if it is waiting for I/O to complete).
User is the amount of CPU time spent in user-mode code (outside the kernel) within the process. This is only actual CPU time used in executing the process. Other processes and time the process spends blocked do not count towards this figure.
Sys is the amount of CPU time spent in the kernel within the process. This means executing CPU time spent in system calls within the kernel, as opposed to library code, which is still running in user-space. Like 'user', this is only CPU time used by the process. See below for a brief description of kernel mode (also known as 'supervisor' mode) and the system call mechanism.
User+Sys will tell you how much actual CPU time your process used. Note that this is across all CPUs, so if the process has multiple threads (and this process is running on a computer with more than one processor) it could potentially exceed the wall clock time reported by Real (which usually occurs). Note that in the output these figures include the User and Sys time of all child processes (and their descendants) as well when they could have been collected, e.g. by wait(2) or waitpid(2), although the underlying system calls return the statistics for the process and its children separately.
Origins of the statistics reported by time (1)
The statistics reported by time are gathered from various system calls. 'User' and 'Sys' come from wait (2) or times (2), depending on the particular system. 'Real' is calculated from a start and end time gathered from the gettimeofday (2) call. Depending on the version of the system, various other statistics such as the number of context switches may also be gathered by time.
On a multi-processor machine, a multi-threaded process or a process forking children could have an elapsed time smaller than the total CPU time - as different threads or processes may run in parallel. Also, the time statistics reported come from different origins, so times recorded for very short running tasks may be subject to rounding errors, as the example given by the original poster shows.
A brief primer on Kernel vs. User mode
On Unix, or any protected-memory operating system, 'Kernel' or 'Supervisor' mode refers to a privileged mode that the CPU can operate in. Certain privileged actions that could affect security or stability can only be done when the CPU is operating in this mode; these actions are not available to application code. An example of such an action might be manipulation of the MMU to gain access to the address space of another process. Normally, user-mode code cannot do this (with good reason), although it can request shared memory from the kernel, which could be read or written by more than one process. In this case, the shared memory is explicitly requested from the kernel through a secure mechanism and both processes have to explicitly attach to it in order to use it.
The privileged mode is usually referred to as 'kernel' mode because the kernel is executed by the CPU running in this mode. In order to switch to kernel mode you have to issue a specific instruction (often called a trap) that switches the CPU to running in kernel mode and runs code from a specific location held in a jump table. For security reasons, you cannot switch to kernel mode and execute arbitrary code - the traps are managed through a table of addresses that cannot be written to unless the CPU is running in supervisor mode. You trap with an explicit trap number and the address is looked up in the jump table; the kernel has a finite number of controlled entry points.
The 'system' calls in the C library (particularly those described in Section 2 of the man pages) have a user-mode component, which is what you actually call from your C program. Behind the scenes, they may issue one or more system calls to the kernel to do specific services such as I/O, but they still also have code running in user-mode. It is also quite possible to directly issue a trap to kernel mode from any user space code if desired, although you may need to write a snippet of assembly language to set up the registers correctly for the call. A page describing the system calls provided by the Linux kernel and the conventions for setting up registers can be found here.
More about 'sys'
There are things that your code cannot do from user mode - things like allocating memory or accessing hardware (HDD, network, etc.). These are under the supervision of the kernel, and it alone can do them. Some operations that you do (like malloc orfread/fwrite) will invoke these Kernel functions and that then will count as 'sys' time. Unfortunately it's not as simple as "every call to malloc will be counted in 'sys' time". The call to malloc will do some processing of its own (still counted in 'user' time) and then somewhere along the way it may call the function in kernel (counted in 'sys' time). After returning from the kernel call, there will be some more time in 'user' and then malloc will return to your code. As for when the switch happens, and how much of it is spent in kernel mode... you cannot say. It depends on the implementation of the library. Also, other seemingly innocent functions might also use malloc and the like in the background, which will again have some time in 'sys' then.
其实如果这些看完就知道了,我当时没有看这块内容,问笨神了,不得不说笨神大大很牛逼啊,直接告诉我有可能那个时候因为swap导致gc慢了,最后经过一系列验证的确是swap问题,把这个关闭就没有这块的问题了。其实类似linux很重要,需要重点学习下。
其实IO也很重要,在后面的一个问题虽然不是IO问题,但是笨神提到了是否是IO问题,也是需要关注的一个点,sar(System Activity Reporter系统活动情况报告)是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。一句话sar非常牛逼。
敲入“sar”,如果提示没有进行安装:
yum install sysstat 安装成功后,sar有很多明白包括不限于, 查看CPU使用率、查看平均负荷、查看内存使用情况、查看页面交换发生状况、查看I/O和传送速率的统计信息等,重点看看IO这块:
-d option in the sar command is used to display the block device statistics report. Using option -p (pretty-print) along with -d make the dev column more readable, example is shown below :
sar -d -p 1
等相关命令。
选择UseParallelOldGC垃圾回收器相关坑
- 新生代对象每经历依次minor gc,年龄会加一,当达到年龄阀值会直接进入老年代。阀值大小一般为15
- Survivor空间中年龄所有对象大小的总和大于survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,而无需等到年龄阀值
- 大对象直接进入老年代
- 新生代复制算法需要一个survivor区进行轮换备份,如果出现大量对象在minor gc后仍然存活的情况时,就需要老年代进行分配担保,让survivor无法容纳的对象直接进入老年代
先通过命令:
jstat -gc pid 3s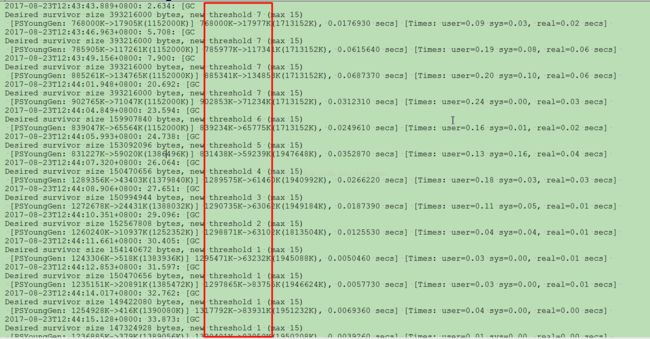
通过各种日志观察,见鬼啦,居然S0、S1大小在越来越小,对、你没有看错,PS下UseAdaptiveSizePolicy默认是打开的,对问题就是在这里,通过命令:
jinfo -flag UseAdaptiveSizePolicy pid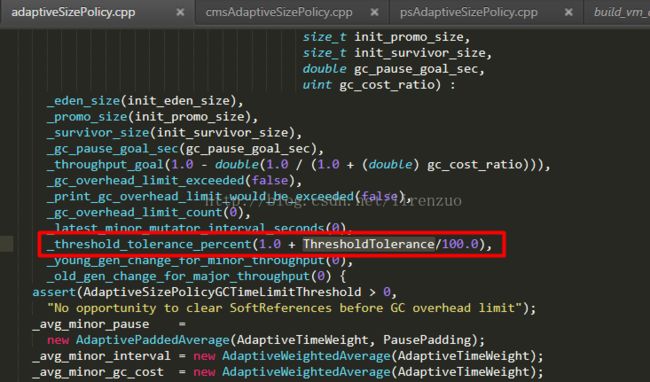
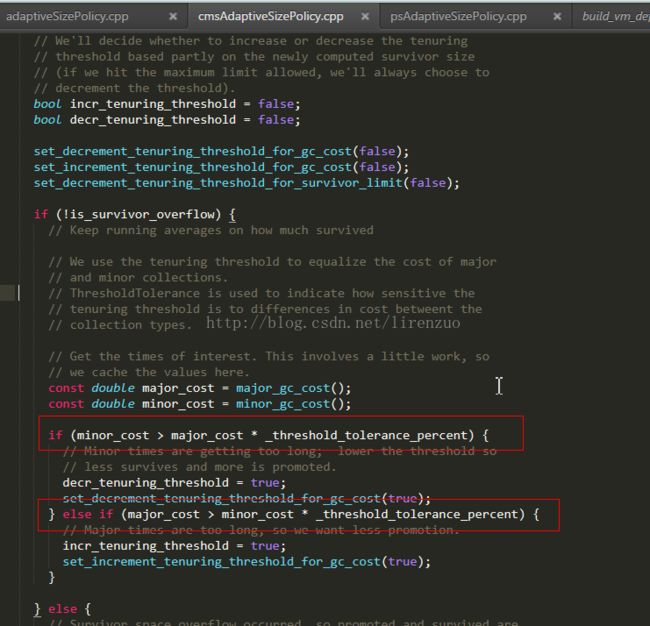


再此观察,日志里面一个类似age的都没有,以为不是对象年龄到了晋升到old的,怀疑是对象过大了,通过加 -XX:PretenureSizeThreshold=100m参数(这个参数其实只对串行回收器和ParNew有效,对ParallelGC无效), 再次观察,还是old很涨,如果巨坑来了,纠结一晚上。
