机器学习算法原理与实践(六)、感知机算法
-
- 感知机
- 感知机模型
- 感知机的学习策略
- 感知机的原始形式
- 伪代码
- 实现代码
- 对线性可分数据集
- 对线性不可分数据集
- 感知机的对偶形式
- 伪代码
- 代码
- 训练过程
- 分类效果
- 训练误差
- 感知机
转载请注明出处【CSDN】http://blog.csdn.net/llp1992
感知机
感知机是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法对损失函数进行最优化(最优化)。感知机的学习算法具有简单而易于实现的优点,分为原始形式 和 对偶形式。感知机预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型。感知机是一种线性分类模型,只适应于线性可分的数据,对于线性不可分的数据模型训练是不会收敛的。
感知机模型
假设输入空间(特征向量)是 x∈Rn 输出空间为 Y={−1,+1} ,输入 x∈X 表示表示实例的特征向量,对应于输入空间的点,输出 y∈Y 表示实例的类别,则由输入空间到输出空间的表达形式为:
该函数称为感知机,其中 w和b 称为模型的参数, w∈Rn 称为权值, b 称为偏置, w⋅x 表示 w和x 的内积
这里
如果我们将sign称之为激活函数的话,感知机与logistic regression的差别就是感知机激活函数是sign,logistic regression的激活函数是sigmoid。sign(x)将大于0的分为1,小于0的分为-1;sigmoid将大于0.5的分为1,小于0.5的分为0。因此sign又被称为单位阶跃函数,logistic regression也被看作是一种概率估计。
在神经网络以及DeepLearning中会使用其他如tanh,relu等其他激活函数。
感知机的学习策略
如下图: 线性可分数据集
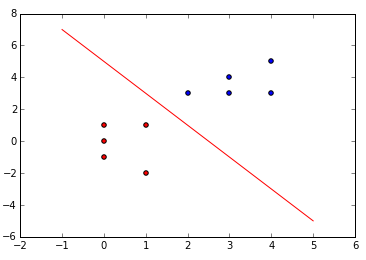
对于一个给定的线性可分的数据集,如上面的数据点,红色代表正类,蓝色代表负类,感知机的主要工作就是寻找一个线性可分的超平面 S:{w⋅x+b=0} , 该超平面能够将所有的正类和负类完全划分到超平面的两侧。而这就是上图中的红色直线,也就是说,感知机算法实际上就是找一条直线将数据集进行正确划分。
如果数据集可以被一个超平面完全划分,则称该数据集是线性可分的数据集,否则称为线性不可分的数据集,如下图:
非线性可分数据集
感知机分类效果:
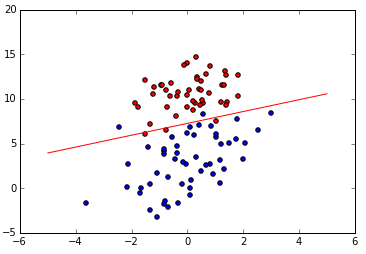
logistic regression分类效果:
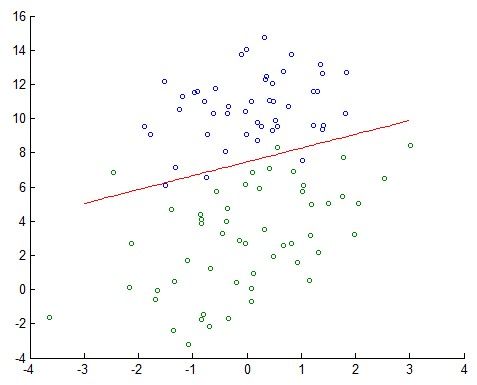
为了寻找上面那条能够将数据集完全划分的超平面 S:w⋅x+b=0 我们需要确定一个学习策略,也就是常说的loss function 以及梯度下降法迭代求解。
为了使用梯度下降法求解 w和b ,我们的loss function必须是 w和b 的连续可导函数,因此可以选择loss function为:误分类点到超平面 S 的总距离。令输入 x0 到超平面 S 的距离为 1||w|||w⋅x0+b| ,其中 ||w|| 为 w 的 L2 范数。
对误分类点 (xi,yi) 来说,有 −yi(w⋅xi+b)>0 ,则可得loss function为:
感知机的原始形式
伪代码
输入:训练数据集 T=(x1,y1),(x2,y2),⋯,(xN,yN), 其中 xi∈X=Rn,yi∈Y=−1,+1.i=1,2,⋯,N; 学习率 η(0<η≤1)
输出: w,b ;感知机模型 f(x)=sign(w⋅x+b)
1、选取初值 w0,b0
2、在训练集中选取数据 (xi,yi)
3、 yi(w⋅xi+b)≤0
w=w+ηyixib=b+ηyi
4、转至2直到没有误分类点
直观解释:当一个实例点被误分的时候,即调整 w,b , 也就是调整 超平面所在的直线,让误分类的点划分到正确的一侧。
实现代码
"""
@Description : perceptron by python
@Author: Liu_Longpo
@Time: Sun Dec 20 12:57:00 2015
"""
import matplotlib.pyplot as plt
import numpy as np
import time
trainSet = []
w = []
b = 0
lens = 0
alpha = 0 # learn rate , default 1
trainLoss = []
def updateParm(sample):
global w,b,lens,alpha
for i in range(lens):
w[i] = w[i] + alpha*sample[1]*sample[0][i]
b = b + alpha*sample[1]
def calDistance(sample):
global w,b
res = 0
for i in range(len(sample[0])):
res += sample[0][i] * w[i]
res += b
res *= int(sample[1])
return res
def trainMLP(Iter):
print "training MLP..."
print "-"*40
epoch = 0
for i in range(Iter):
train_loss = 0
update = False
print "epoch",epoch, " w: ",w,"b:",b,
for sample in trainSet:
res = calDistance(sample)
if res <= 0:
train_loss += -res
update = True
updateParm(sample)
print 'train loss:',train_loss
trainLoss.append(train_loss)
if update:
epoch = epoch+1
else:
print "The training have convergenced,stop trianing "
print "Optimum W:",w," Optimum b:",b
#os._exit(0)
break # early stop
update = False
if __name__=="__main__":
'''
if len(sys.argv)!=4:
print "Usage: python MLP.py trainFile modelFile"
exit(0)
alpha = float(sys.argv[1])
trainFile = open(sys.argv[2])
modelPath = sys.argv[3]
'''
alpha = float(0.1)
trainFile = open('E://ML&DL//MachineLearning//python//testSet.txt')
#modelPath = 'model'
lens = 0
# load data trainSet[i][0]:data,trainSet[i][1]:label
for line in trainFile:
data = line.strip().split('\t') # train ' ' ,testSet '/t'
lens = len(data) - 1
sample_all = []
sample_data = []
for i in range(0,lens):
sample_data.append(float(data[i]))
sample_all.append(sample_data) # add data
if int(data[lens]) == 1:
sample_all.append(int(data[lens])) # add label
else:
sample_all.append(-1) # add label
trainSet.append(sample_all)
trainFile.close()
# initialize w by 0
for i in range(lens):
w.append(0)
# train model for max 100 Iteration
start = time.clock()
trainMLP(500)
end = time.clock()
print 'train time is %f s.' % (end - start)
x = np.linspace(-5,5,10)
plt.figure()
for i in range(len(trainSet)):
if trainSet[i][1] == 1:
plt.scatter(trainSet[i][0][0],trainSet[i][0][1],c=u'b')
else:
plt.scatter(trainSet[i][0][0],trainSet[i][0][1],c=u'r')
plt.plot(x,-(w[0]*x+b)/w[1],c=u'r')
plt.show()
trainIter = range(len(trainLoss))
plt.figure()
plt.scatter(trainIter,trainLoss,c=u'r')
plt.plot(trainIter,trainLoss)
plt.xlabel('Epoch')
plt.ylabel('trainLoss')
plt.show()
对线性可分数据集
训练过程
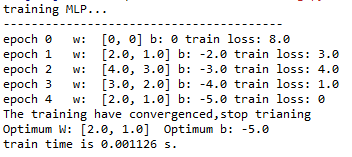
分类结果
迭代误差
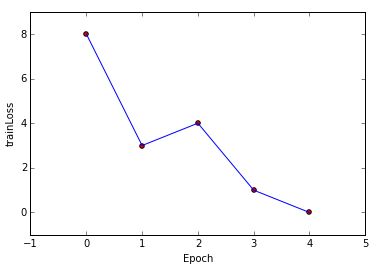
对线性不可分数据集
训练过程

分类结果
迭代误差
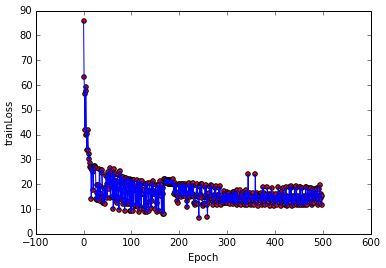
感知机算法的训练过程与logistic regression大体一致,梯度下降时的每一次更新都需要将整个数据集代入训练,所以训练完的分类效果也基本一致。
感知机的对偶形式
基本思想:
将 w 和 b 表示为实例 xi 和标记 yi 线性组合的形式,通过求解其系数而求得 w、b 。假设 w0,b0 为0,对误分类点 (xi,yi) 通过
逐步修改 w,b ,设修改 n 次,则 w,b 关于 (xi,yi) 的增量分别为 αiyixi 和 αiyi , 其中 αi=niη ,则最后学习到的 w,b 可以分别表示为
这里, αi≥0,=1,2,⋯N , αi=niη , ni 的意义是样本 i 被误分的次数,所以当 η=1 时,表示第 i 个样本由于被误分而更新的次数,实例点更新次数越多,表明它距离分离超平面越近,也就越难正确分类。
伪代码
输入:线性可分的数据集 T={(x1,y1),(x2,y2),⋯,(xN,yN)} ,其中 xi∈Rn,yi∈−1,+1,i=1,2,⋯,N ,学习率 η(0<η<1) ;
输出: a,b ;感知机模型 f(x)=sign(∑Nj=1αiyjxj⋅x+b)
其中, α=(α1,α2,⋯,αN)T
(1) α=0,b=0
(2) 在训练集中选取数据 (xi,yi)
(3) 如果 yi(∑Nj=1αjyjxj⋅xi+b)≤0
αi=αi+ηb=b+ηyi
(4) 转至(2)知道没有误分类数据
代码
# -*- coding: utf-8 -*-
'''
@Description : dualperceptron by python
@Author: Liu_Longpo
@Time: Sun Dec 20 12:57:00 2015
'''
import matplotlib.pyplot as plt
import numpy as np
import time
trainSet = []
w = []
a = []
b = 0
lens = 0
alpha = 0
Gram = []
trainLoss = []
def calInnerProduct(i, j):
global lens
res = 0
for p in range(lens):
res += trainSet[i][0][p] * trainSet[j][0][p]
return res
def AddVector(vec1, vec2):
retvec = []
for i in range(len(vec1)):
retvec.append(vec1[i] + vec2[i])
return retvec
def NumProduct(num, vec):
retvec = []
for i in range(len(vec)):
retvec.append(num * vec[i])
return retvec
def createGram():
global lens
for i in range(len(trainSet)):
tmp = []
for j in range(0, len(trainSet)):
tmp.append(calInnerProduct(i, j))
Gram.append(tmp)
# update parameters using stochastic gradient descent
def updateParm(k):
global a, b, alpha
a[k] += alpha
b = b + alpha * trainSet[k][1]
def calDistance(k):
global a, b
res = 0
for i in range(len(trainSet)):
res += a[i] * int(trainSet[i][1]) * Gram[i][k]
res += b
res *= trainSet[k][1]
return res
def trainModel(Iter):
print "training MLP..."
print "-"*40
epoch = 0
for i in range(Iter):
train_loss = 0
global w, a
update = False
print "epoch",epoch, " w: ",w,"b:",b,
for j in range(len(trainSet)):
res = calDistance(j)
if res <= 0:
train_loss += -res
update = True
updateParm(j)
print 'train loss:',train_loss
trainLoss.append(train_loss)
if update:
epoch = epoch+1
else:
for k in range(len(trainSet)):
w = AddVector(w, NumProduct(a[k] * int(trainSet[k][1]), trainSet[k][0]))
print "result: w: ", w, " b: ", b
update = False
if epoch==Iter:
print 'reach max trian epoch'
for j in range(len(trainSet)):
w = AddVector(w, NumProduct(a[j] * int(trainSet[j][1]), trainSet[j][0]))
print "RESULT: w: ", w, " b: ", b
if __name__=="__main__":
'''
if len(sys.argv)!=4:
print "Usage: python MLP.py trainFile modelFile"
exit(0)
alpha = float(sys.argv[1])
trainFile = open(sys.argv[2])
modelPath = sys.argv[3]
'''
alpha = float(0.1)
trainFile = open('./testSet.txt')
#modelPath = 'model'
lens = 0
# load data trainSet[i][0]:data,trainSet[i][1]:label
for line in trainFile:
data = line.strip().split('\t')
lens = len(data) - 1
sample_all = []
sample_data = []
for i in range(0,lens):
sample_data.append(float(data[i]))
sample_all.append(sample_data) # add data
if int(data[lens]) == 1:
sample_all.append(int(data[lens])) # add label
else:
sample_all.append(-1) # add label
trainSet.append(sample_all)
trainFile.close()
createGram()
for i in range(len(trainSet)):
a.append(0)
for i in range(lens):
w.append(0)
start = time.clock()
trainModel(500)
end = time.clock()
print 'train time is %f s' % (end - start)
x = np.linspace(-5,5,10)
plt.figure()
for i in range(len(trainSet)):
if trainSet[i][1] == 1:
plt.scatter(trainSet[i][0][0],trainSet[i][0][1],c=u'b')
else:
plt.scatter(trainSet[i][0][0],trainSet[i][0][1],c=u'r')
plt.plot(x,-(w[0]*x+b)/w[1],c=u'r')
plt.show()
trainIter = range(len(trainLoss))
plt.figure()
plt.scatter(trainIter,trainLoss,c=u'r')
plt.plot(trainIter,trainLoss)
plt.xlabel('Epoch')
plt.ylabel('trainLoss')
plt.show()
训练过程

对比起原始形式的感知机,同样的数据集,同样的迭代次数其训练过程只需要0.08824s,而对偶形式却需要1.7484s,可见原始形式的感知机在速度上占优势,且分类性能与对偶形式基本一致。
分类效果
训练误差
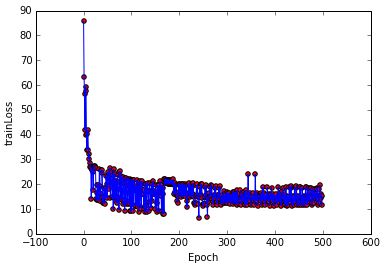
对于非线性可分的数据集,感知机的算法迭代过程都会发生震荡,如上图的train loss.
代码数数据集可在 Github 上下载
