Hadoop HA 原理及HA 高可用集群搭建
完全分布式参考:Hadoop完全分布式搭建。
目录
一、前期准备
二、HA 概述
三、原理
四、HA 集群搭建
4.1 HA集群搭建规划
4.2 Hadoop HA集群搭建
五、web端访问查询
序:
软件版本:
- VMware:VMware-15.5.1
- Linux:CentOS-7.5-x86_64-DVD-1804.iso
- JDK:jdk-8u212-linux-x64.tar.gz
- Hadoop:hadoop-3.1.3.tar.gz
- Zookeeper:zookeeper 3.5.7
一、前期准备
本次HA集群搭建是在分布式集群搭建的基础上完成。完全分布式搭建参考:Hadoop完全分布式搭建。HA集群搭建之前,需要完成以下准备:
- 完成JDK的安装及环境变量配置
- 完成Zookeeper的安装及配置
- 如Hadoop完全分布式搭建,在其基础上搭建HA 高可用集群
二、HA 概述
所谓HA(High Availablity),即高可用(7*24小时不中断服务)。实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。Hadoop2.0之前,在HDFS集群中NameNode存在单点故障SPOF(Single Points Of Failure)。
NameNode主要在以下两个方面影响HDFS集群(ResourceManager的影响相同)
- NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
- NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active/Standby两类NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
三、原理
通过多NameNode(Active NameNode和Standby NameNode)和ResourceManager(Active ResourceManager和Standby ResourceManager)来消除单点故障,但多NameNode和ResourceManager又会产生如下问题:
- 如何保证多个NameNode中的数据同步问题?
- 多个NameNode怎么确定谁是Active NameNode?
- Active NameNode故障后,多个Standby如何确定Active NameNode?如何实现Active的自动转移?
在Hadoop HA 高可用集群中,通过创建JournalNode集群来存储各NameNode所需的元数据信息,从而保持元数据信息同步。实现方式是:Active NameNode除了在自己的节点中维护元数据,还会将保存的编辑日志和元数据镜像保存到JournalNode集群中,Standby NameNode会从集群中获取编辑日志和元数据镜像,并在自己的节点中合并成元数据信息,从而实现元数据同步。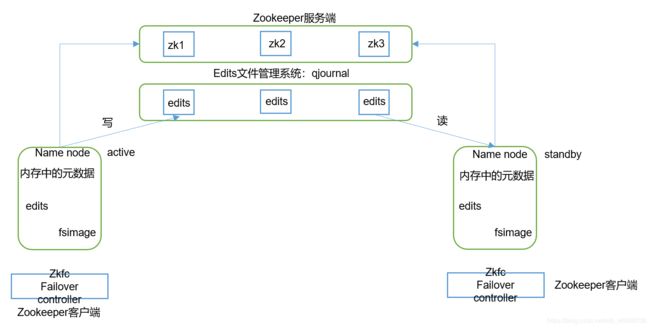
Active NodeManage选定的解决方式如图,在HA机制中,增加了ZooKeeper和ZKFailoverController(ZKFC)进程。ZooKeeper是维护少量协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA的自动故障转移依赖于ZooKeeper的以下功能:
故障检测:
集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZooKeeper中的会话将终止,ZooKeeper通知另一个NameNode需要触发故障转移。
现役NameNode选择:
ZooKeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是ZooKeeper的客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
ZooKeeper会话管理:当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
基于ZooKeeper的选择:如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active。故障转移进程与前面描述的手动故障转移相似,首先如果必要保护之前的现役NameNode,然后本地NameNode转换为Active状态。
如上图,简言之
每个NameNode都有一个对应的ZKFC作为自己的监护线程,HDFS系统初次启动时,多个NameNode对应的ZKFC会进行锁的争夺(即Zookeeper中的节点注册),抢到锁的ZKFC会将对应的NameNode置成Active。若是ZKFC在监视过程发现自己负责的Active NameNode没有信息反馈,则认为该NameNode已经故障,则会将抢到的锁释放。其他的ZKFC会对释放的锁进行争夺,获得者会进入原Active NameNode中将原Active NameNode 线程杀掉,然后将自己对应的NameNode置为Active对外服务,从而解决了单NameNode故障,集群无法工作及Active NameNode的选择问题。ResourceManagerHA的原理相同。
四、HA 集群搭建
4.1 HA集群搭建规划
表1-1: HA 高可用集群3个服务器的节点安排
| hadoop102 |
hadoop103 |
hadoop104 |
| NameNode |
NameNode |
NameNode |
| ZKFC |
ZKFC |
ZKFC |
| JournalNode |
JournalNode |
JournalNode |
| DataNode |
DataNode |
DataNode |
| ZK (zookeeper) |
ZK (zookeeper) |
ZK (zookeeper) |
| ResourceManager |
ResourceManager |
ResourceManager |
| NodeManager |
NodeManager |
NodeManager |
4.2 Hadoop HA集群搭建
1、将Hadoop 安装在/opt/module/ha/目录下,并在/etc/profile.d/目录下修改my-env.sh,具体内容如下:
#JAVA_HOME
JAVA_HOME=/opt/module/jdk1.8.0_212
#HADOOP_HOME
HADOOP_HOME=/opt/module/ha/hadoop-3.1.3
#ZOOKEEPER_HOME
ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
export PATH JAVA_HOME HADOOP_HOME ZOOKEEPER_HOME
2、修改hadoop配置文件core-site.xml,位置:opt/module/ha/hadoop-3.1.3/etc/hadoop/。core-site.xml配置如下:
ha.zookeeper.quorum
hadoop102:2181,hadoop103:2181,hadoop104:2181
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/opt/module/ha/hadoop-3.1.3/data/tmp
dfs.journalnode.edits.dir
file://${hadoop.tmp.dir}/jn
fs.trash.interval
5
fs.trash.checkpoint.interval
5
hadoop.http.staticuser.user
lipeng
hadoop.proxyuser.lipeng.hosts
*
hadoop.proxyuser.lipeng.groups
*
hadoop.proxyuser.lipeng.users
*
3、修改hadoop配置文件hdfs-site.xml,位置:opt/module/ha/hadoop-3.1.3/etc/hadoop/。hdfs-site.xml配置如下:
dfs.ha.automatic-failover.enabled
true
dfs.replication
3
dfs.nameservices
mycluster
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/name
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop102:9000
dfs.namenode.rpc-address.mycluster.nn2
hadoop103:9000
dfs.namenode.rpc-address.mycluster.nn3
hadoop104:9000
dfs.namenode.http-address.mycluster.nn1
hadoop102:9870
dfs.namenode.http-address.mycluster.nn2
hadoop103:9870
dfs.namenode.http-address.mycluster.nn3
hadoop104:9870
dfs.namenode.shared.edits.dir
qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/atguigu/.ssh/id_rsa
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.client.datanode-restart.timeout
30s
4、修改hadoop的yarn-site.xml,位置:opt/module/ha/hadoop-3.1.3/etc/hadoop/。yarn-site.xml的配置如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster-yarn
yarn.resourcemanager.ha.rm-ids
rm1,rm2,rm3
yarn.resourcemanager.hostname.rm1
hadoop102
yarn.resourcemanager.webapp.address.rm1
hadoop102:8088
yarn.resourcemanager.address.rm1
hadoop102:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop102:8030
yarn.resourcemanager.resource-tracker.address.rm1
hadoop102:8031
yarn.resourcemanager.hostname.rm2
hadoop103
yarn.resourcemanager.webapp.address.rm2
hadoop103:8088
yarn.resourcemanager.address.rm2
hadoop103:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop103:8030
yarn.resourcemanager.resource-tracker.address.rm2
hadoop103:8031
yarn.resourcemanager.hostname.rm3
hadoop104
yarn.resourcemanager.webapp.address.rm3
hadoop104:8088
yarn.resourcemanager.address.rm3
hadoop104:8032
yarn.resourcemanager.scheduler.address.rm3
hadoop104:8030
yarn.resourcemanager.resource-tracker.address.rm3
hadoop104:8031
yarn.resourcemanager.zk-address
hadoop102:2181,hadoop103:2181,hadoop104:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.nodemanager.vmem-check-enabled
false
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
5、hadoop软件、环境变量文件集群分发,使用xsync脚本(没有的可参考行首链接文档)和scp命令
xsync /op/module/ha/*
#环境变量设置分发
scp -r /etc/profile.d/my-env.sh root@hadoop103:/etc/profile.d/
scp -r /etc/profile.d/my-env.sh root@hadoop104:/etc/profile.d/
#分发后在集群各节点执行以下操作
source /etc/profile6、启动journalnode服务,启动前先确保/tmp目录下为空,不为空需删除目录内容。然后hadoop102、hadoop103、hadoop104分别启动journalnode服务。各服务器执行以下命令,执行完,调用jps查询进程,确保开启。
hdfs --daemon start journalnode
#jps查询如下:
1678 JournalNode
1727 Jps7、集群各节点启动zookeeper集群,并初始化HA在Zookeeper中的状态
zkServer.sh start
hdfs zkfc -formatZK8、namenode格式化:在集群中任意一个服务器上进行namenode格式化并启动,执行代码如下:
hdfs namenode -format
hdfs --daemon start namenode
9、其他服务器元数据同步并启动其他的namenode,此时完成所有namenode的启动
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode10、所有服务器启动datanode
hdfs --daemon start namenode11、启动集群yarn服务
start-yarn.sh12、一键启动脚本,由于启动的节点较多,最好的实现方式是编写脚本,实现一键启动,脚本内容如下:
#!/bin/bash
if [ $# -lt 1 ]
then
echo " no args input "
exit
fi
case $1 in
"start")
echo "==================start hadoop102 zookeeper ==============="
ssh hadoop102 /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
echo "==================start hadoop103 zookeeper ==============="
ssh hadoop103 /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
echo "==================start hadoop104 zookeeper ==============="
ssh hadoop104 /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
echo "====================start $i hdfs==================="
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/sbin/start-dfs.sh
echo "====================start $i yarn=================="
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/sbin/start-yarn.sh
echo "------------------start historyserver----------------------"
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/bin/mapred --daemon start historyserver
;;
"stop")
echo "====================stop $i yarn=================="
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/sbin/stop-yarn.sh
echo "------------------stop historyserver-----------------------"
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/bin/mapred --daemon stop historyserver
echo "====================stop $i hdfs==================="
ssh hadoop102 /opt/module/ha/hadoop-3.1.3/sbin/stop-dfs.sh
echo "==================stop hadoop102 zookeeper ==============="
ssh hadoop102 /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
echo "==================stop hadoop103 zookeeper ==============="
ssh hadoop103 /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
echo "==================stop hadoop104 zookeeper ==============="
ssh hadoop104 /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
;;
*)
echo "input error"
;;
esac
13、一键启动后进程查询,使用myjps脚本
--------------------hadoop102 jps----------------------
3667 DFSZKFailoverController
1796 QuorumPeerMain
3157 NodeManager
2149 DataNode
3381 JobHistoryServer
3014 ResourceManager
4278 Jps
1678 JournalNode
2014 NameNode
--------------------hadoop103 jps----------------------
2053 DataNode
4280 Jps
1977 NameNode
3370 DFSZKFailoverController
2682 QuorumPeerMain
2522 NodeManager
2426 ResourceManager
2172 JournalNode
--------------------hadoop104 jps----------------------
1920 NameNode
2468 NodeManager
2372 ResourceManager
4358 Jps
2118 JournalNode
3000 DFSZKFailoverController
3176 QuorumPeerMain
1996 DataNode
五、web端访问查询
1、namenode web端查询,端口9870,结果如下



2、resourcemanager web端查看,端口号:8088,结果如下:
好啦,到此hadoop HA 高可用集群就搭建好,可以尝试断开Active Namenode或Active ResouceManager来验证单点故障的自动转移。
