Hadoop3完全分布式搭建
一、第一台的操作搭建
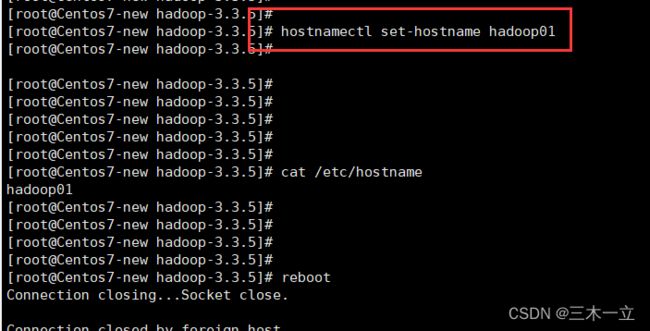
修改主机名
使用hostnamectl set-hostname 修改当前主机名
关闭防火墙和SELlinux
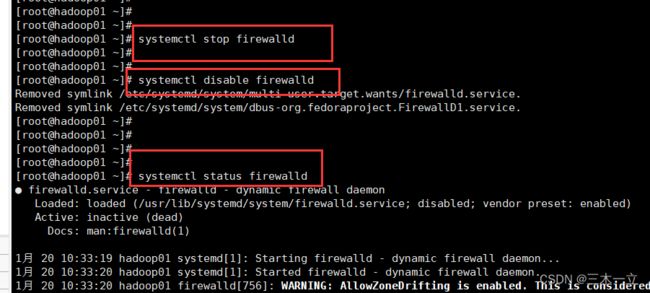
1,使用
systemctl stop firewalld
systemctl disable firewalld
关闭防火墙
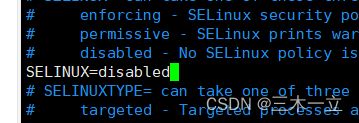
2,使用
vim /etc/selinux/config
修改为 SELINUX=disabled
使用NAT模式配置静态IP
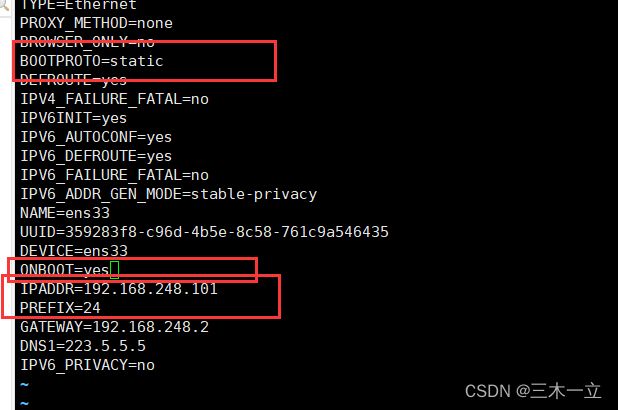
1,修改网络配置
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改如下三项内容:
BOOTPROTO=static
ONBOOT=yes
IPADDR=自己想要设置的IP。这个ip参考vmware的虚拟网络编辑器的vmnet8的IP地址进行设置。
2,重启网络。

二、克隆虚拟机
克隆虚拟机
1,克隆

2,
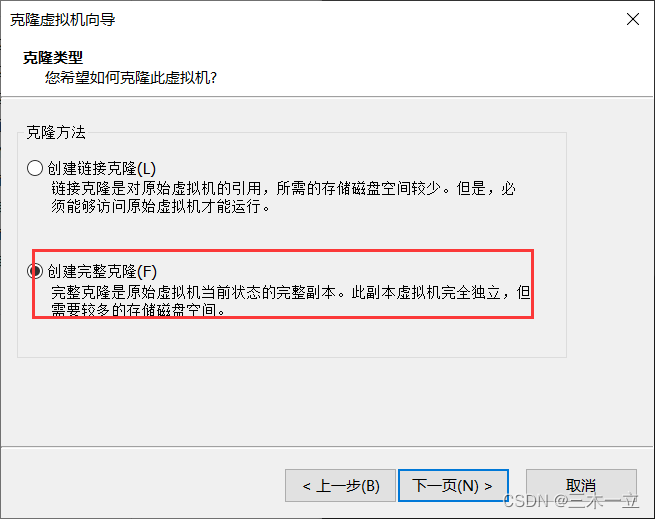
3,
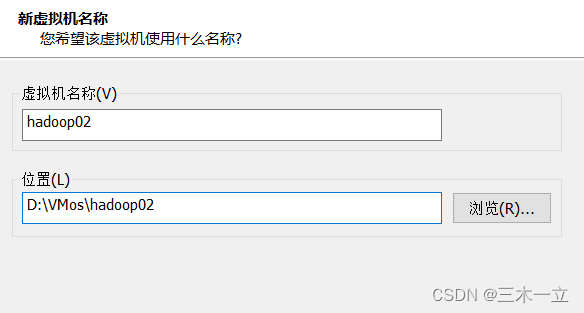
修改克隆后的虚拟机的静态IP
修改IP为192.168.248.102. 同理第三台虚拟机同样的修改。

可以修改一下hadoop02,hadoop03的主机名
使用hostnamectl set-hostname 修改当前主机名
三、主机映射
为后面的hadoop的核心配置文件做准备的。
vim /etc/hosts
因为配置三个集群节点。所以如下配置。
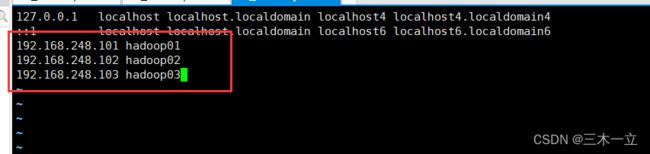
在另外两台节点,也修改上面的文件vim /etc/hosts
四、设置免密登录
管理集群不可能每个都要输入账号密码进行登录,那可太费劲了。
所以需要借助公钥、私钥免密登录
1,在第一台节点上,使用 ssh-keygen -t rsa 生成公钥私钥

2,使用ssh-copy-id 目标节点。拷贝到这三台节点上
(1)先拷贝给自己。 先拷贝到hadoop01, 然后会要求输入当前节点的登录密码。

(2)拷贝到hadoop02

(3)拷贝到hadoop03

3,在hadoop02, hadoop03 两个节点上,重复上面的1和2步骤
五、集群时间同步
一种是从节点同步主节点的时间。
一种是所有节点同步网络时间。
这里让所有节点同步网络时间
1,在3台节点上都执行如下命令
crontab -e
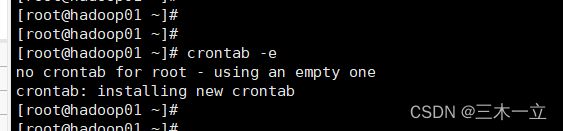
2,然后输入如下内容:
* * * * * /usr/sbin/ntpdate -u ntp.aliyun.com >/var/null 2>&1
![]()
六、在第一台虚拟机上安装配置jdk和hadoop
参考:https://blog.csdn.net/qq_45860901/article/details/135676494?spm=1001.2014.3001.5502
七、配置hadoop配置文件
1,切换到hadoop的home 目录下。

2,切到etc目录下, 里面只有一个hadoop文件夹
3,进入到这个hadoop文件夹,就有我们的核心配置文件了。
4,修改配置core-site.xml 文件
注意端口:在hadoop1.x 使用9000端口
hadoop2.x使用8020
hadoop3.x使用9820
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.248.101:9820</value>
</property>
<!--hdfs基础数据路径,放在hadoop文件夹下的tmp文件夹,这个文件不需要提前创建,让hadoop自己创建-->
</configuration>
5,修改hdfs-site.xml
对外http服务的地址
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.248.102:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.248.101:9870</value>
</property>
<!--namenode守护进程运行数据路径-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/app/hadoop/hadoop-3.3.5/tmp/name</value>
</property>
<!--datanode守护进程运行数据路径-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/app/hadoop/hadoop-3.3.5/tmp/data</value>
</property>
</configuration>
6,修改hadoop-env.sh 文件
配置hadoop允许的配置
export JAVA_HOME=/usr/local/app/java/jdk8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
7,配置workers 集群文件。 这个是指定datanode 在哪些节点上,因为要在三台节点上都要配置Datanode,所以都要写。 里面会有一个localhost ,要去掉。
hadoop01
hadoop02
hadoop03
拷贝
为了避免再去多个主机上进行上面的配置操作,使用scp 命令拷贝分发。
1,拷贝hadoop和Jdk文件分发给其他节点.
(1)下面命令是递归的将hadoop-3.3.5文件夹,拷贝到hadoop02的当前目录下,当前目录就是在hadoop01同级的目录下。
scp -r hadoop-3.3.5/ hadoop02:$PWD

(2)hadoop03也执行上面操作。
2, 拷贝 /etc/profile 给其他节点
(1)将 profile 文件,拷贝到 hadoop02的 /etc目录下。
scp /etc/profile hadoop02:/etc/
(2)hadoop03也执行上面操作。
格式化集群
在 hadoop01节点上执行下面的命令:hdfs namenode -format

得到如下结果:

启动集群
执行:start-dfs.sh
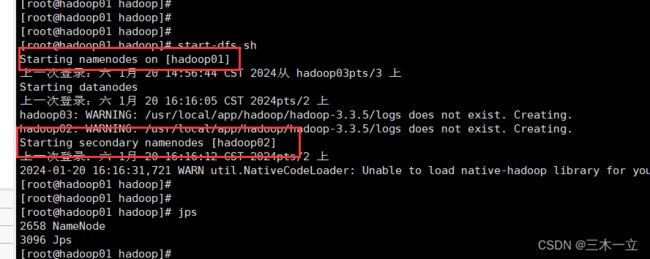
使用JPS命令查看所有运行的java程序:

访问hadoop的web界面
http://192.168.248.101:9870

成功进入:
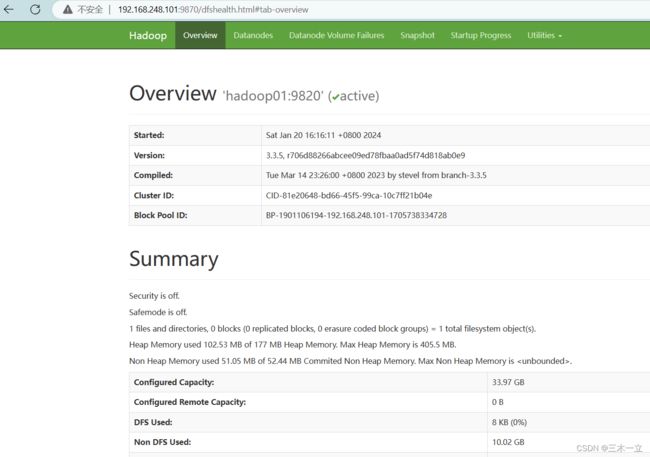
界面介绍
1,Datanode相关界面负载信息

2,这个查看 HDFS的相关信息

如果重启后没有Datanode节点
先停止集群:stop-all.sh
如果按照上面配置代码,则把/usr/local/app/hadoop/hadoop-3.3.5/tmp 文件夹彻底清空删除。
然后再重新格式化:hdfs namenode -format
然后再启动。