梯度提升回归树(GBDT)
一.从Boosting思想开始
1.梯度提升回归树是一种从它的错误中进行学习的技术。它本质上就是集思广益,集成一堆较差的学习算法进行学习。
2.GBDT是基于Boosting思想的,Adaboosting是最著名的Boosting算法,其基本思想是使用多个弱分类器来构建一个强分类器。 3.Adaboosting构造方法是一个迭代的过程,大致思路是:
*针对同一个训练集训练多层的弱分类器,每层使用训练集训练一个弱分类模型,我们从训练出的模型中得到预测结果。
*之后根据训练集中样本分类是否正确、总体分类的准确率来确定每个样本上应重新分配的权值,将修改过权重后的新数据集训练一个下层的分类器
*这样不断进行训练直到有很少的错分样本,最后将每层的分类器有权重分配的融合在一起,这样下来就组成了最终的决策分类器。
可以简化上述过程为:

4.每次迭代需要三次计算,
*一次计算分类误差率(w是每次的权重):

*第二次计算分配给当前分类器的系数:

*第三个是计算新的数据集的权值(y与Gm的值相同表示分对了,变大),其中Zm为规划因子:
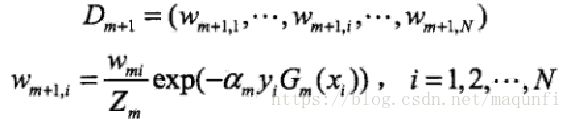
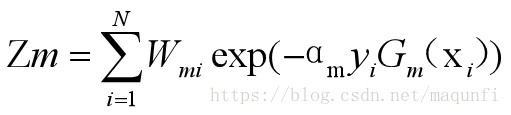
最终得到将所有层分类器的组合: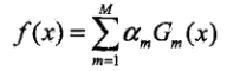
5.下面是图的目标是对红蓝样本进行分类,可发现伴随着多层分类器的增加,分类效果越来越好。
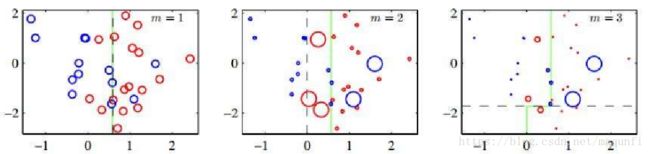

以上就是Adaboost的思想。
二.介绍GBDT
1.GBDT中的Gradient Boosting与Adaboosting方法的区别是:每一次计算都是为了减少上一次计算的残差(利用残差学模型),为了消除残差,我们会在残差减少的梯度方向上创建一个新的模型。
2.可以看出GB和Boosting都是不断堆加模型的方式,只不过Boosting是为了减少误分样本的数量,而GB的目的是为了减小残差值。
GBDT的思想主要三部分:
三.GBDT之RT
1.决策树分为两大类:回归树和分类树。回归树用于预测实数值,数值本身有意义,进行运算的结果仍有意义,而分类树用于分类标签值,如阴/晴天这种,所以其加减是不具有意义的。
2.回归树的总体流程跟分类树很相似,不过在每个节点都可以得到一个预测值,以预测年龄为例,结点处代表的预测值并不是一个具体值,而是所有分到这个节点的所有年龄的平均值(就是经过feature阈值分开后的每部分的平均值)。
3.回归树在进行分枝子时,会穷举每个feature的每个阀值找到最佳的分割点,但是衡量最好分割的标准不再是使用最大熵值进行选择(分类树方式),而是计算最小化均方差,即为:  ,平均年龄代表结点代表的预测值,当错的越多,均方差就会越大。
,平均年龄代表结点代表的预测值,当错的越多,均方差就会越大。
4.通过不断令均方差最小来找到最靠谱的分枝依据(按特征分开后每部分损失最小)。 回归树会不断分枝,直到所有叶子节点上人的年龄都唯一,或者达到预定的叶子上限,若最后叶子节点的年龄不唯一,则选取该结点所有的平均年龄作为预测年龄。
四.GBDT之GB
1.GB是一个算法框架,其可以将已有的分类或者回归算法放入其中,得到一个性能很强大的算法。
2.GB算法共需要M次迭代,每次迭代产生一个模型,我们需要让每次迭代产生的模型对训练集的损失函数最小,为了令损失函数最小,我们采用梯度下降的方法,在每次迭代时通过向损失函数的负梯度方向进行移动, 通过这样的方式来使得损失函数越来越小(基于残差进行学习),最后将每阶段模型加权相加得到最后的结果。
3.假设我们的损失函数是均方根误差,那么算法的思想就是使用梯度下降(针对误差的梯度)和基于损失来更新我们的预测,来找到使得MSE最小的值。
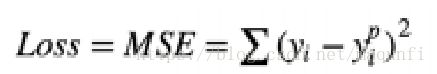

4.下面即为具体过程,左边L是对于每个样本点得到的损失函数下的值,通过这个值去求得负梯度方向 gm。 根据负梯度方向去求得α和β参数。

五.GBDT之Shrinkage
1.Shrinkage的思想认为,每次走一小步逐渐逼近结果的效果相比于每次迈一大步逼近的结果能更好的避免过拟合,即它不完全相信每一棵树,认为每一棵树只学到了真理的一部分。
2.在GBDT中,Shrinkage仍以残差为学习的目标,但对于残差学习的结果只累加一小部分, 来逐渐逼近目标,从而有一种渐变的效果,Shrinkage会为每棵树设置一个weight权重(可以再附加学习率来控制渐变情况),通过乘以权重进行渐进。
GBDT的基本思想比较简单:
(1)初始化设置根节点预测值为所有预测目标的平均值。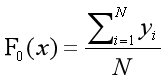
(2) for m=1 到M执行下面的过程:
*计算每个样本当前 ![]() 和yi的残差值:
和yi的残差值: ![]()
*基于所有残差训练一个回归树hm(x), 也就是使用上一步得到的残差集(xi, ![]() )训练一棵回归树。
)训练一棵回归树。
*计算这个回归树所应对应的权重: 
*更新整个模型: ![]()
(3)输出最终结果。
六.GBDT整体思想及案例
1.现在举个简单版本的例子:
假定训练集中有四个人A、B、C、D,年龄分别是14,16,24,26(目标值),划分特征有购物金额<=1,在网时长,经常到百度知道提问,是否上网大于1.1h,是够全天上网这四个特征,使用这些特征构造GBDT模型,去预测对应的年龄。 假如我们使用一个回归树进行训练可以得到下面的树结构。

2.当我们使用GBDT的方法,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1,这样第一次得到的回归树如下。

3.然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值,从而可以构造出第二棵回归树。
4.当此时把两颗进行结合(没有计算权重),就能根据特征得到每个人对应的预测年龄。
* 购物较少,经常到百度知道提问;预测年龄A = 15 – 1 = 14
* 购物较少,经常到百度知道回答;预测年龄B = 15 + 1 = 16
* 购物较多,经常到百度知道提问;预测年龄C = 25 – 1 = 24
* 购物较多,经常到百度知道回答;预测年龄D = 25 + 1 = 26

5.可以看出GBDT相对于只使用回归树,少用了一个特征,因为用的特征更少,所以能防止过拟合。 该版本中用残差作为全局最优的绝对方向,并不需要Gradient求解.
(该版本中用残差作为全局最优的绝对方向,并不需要Gradient求解.)