MYSQL || 的BUG // MYSQL 不同库自增id的问题 //MySQL根据表注释查找对应的表 //hive -mysql 日期比较
MYSQL 中的|| 与oracle 的concat 含义不同,它的含义是 or
delete from table
where 1=1 and code ='CW1111'
and period_wid =2020||04
的真正含义是
delete from table
where 1=1 and code ='CW1111'
and period_wid =2020
加上
delete from table
where 04
也就是全表扫描。
和
delete from table
where 1=1 and code ='CW1111'
and period_wid =202004
含义不同
mysql insert插入时实现如果数据表中主键重复则更新,没有重复则插入的四种方法
1、replace语句:替换已有的行
replace语句是insert语句的一个变种
当添加新行时
1)如果主键值重复,那么覆盖表中已有的行
2)如果没有主键值重复,则插入该行
2、ignore
insert语句可以使用ignore选项来当insert语句出现错误时,不显示错误信息,但是insert语句不执行。
insert ignore into 。。。。。
3、可以采用异常抓捕的方式来实现handler,相当于sqlserver中的try catch
4、如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,
则在出现重复值的行执行UPDATE;如果不会导致唯一值列重复的问题,则插入新行。
四个方法分步解析:
操作表test表结构如下

1、replace语法
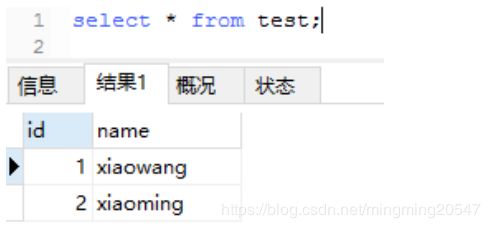
select * from test;![]()
现在插入(1,’xiaohong’)数据,发现出现错误,错误提示(主键重复输入’1’),证明当insert插入相同主键时是会报错的。
现在我们来replace语句测试一下会不会不报错,执行成功
 查
查
询一下我们的表信息,发现之前的记录(1,’xiaozhang’)已经被替换成(1,’xiaohong’),
证明我们插入相同的主键信息,replace会替换原有信息。

replace语法执行和数据库中主键重复的数据会替换原有信息,那么执行不同的信息会有怎么样的操作呢?(发现执行和数据库中没有主键重复的数据,则执行插入操作)

2、ignore
这里我们应用insert ignore执行插入(1,’xiaoplan’),运行成功,但是数据没有插入到test表中。


insert ignore 和update联合使用(发现主键为’1’的’xiaohong’被更新为’xiaolan’)

运行结果图
3、可以采用异常抓捕的方式来实现handler,相当于sqlserver中的try catch
handler是mysql的自定义异常处理。
定义异常处理语法
DECLARE handler_type HANDLER FOR condition_value sp_statement
语法解析
handler_type:为异常的处理方式,也就是当发生异常时怎么处理,有三个参数
1)exit ,表示遇到异常马上退出
2)continue ,表示遇到异常不处理,继续执行sql代码
3)undo ,mysql不支持,是一个回滚操作
condition_value:表示错误类型
1)SQLSTATE [VALUE] sqlstate_value 为包含5个字符的字符串错误值
2)SQLWARNING 匹配所有以01开头的SQLSTATE错误代码
3)NOT FOUND 匹配所有以02开头的SQLSTATE错误代码
4)SQLEXCEPTION 匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码
5)mysql_error_code 匹配数值类型错误代码
condition_name:标志定义错误的名称
这边我们要实现插入时如果主键重复则更新,主键不重复则插入的效果,所以我们要先了解主键重复的异常是什么,然后抓捕异常,将异常处理类型定义为continue,然后执行我们的update操作
先找出主键重复错误的异常编号,标号为’1062’

直接上代码
drop procedure if exists test;
create procedure test() #创建存储过程
BEGIN
DECLARE done INT default 0 ; #定义变量
#定义主键重复异常发生时将done赋值为1;同时异常的处理方式是continue,异常发生继续执行
DECLARE CONTINUE HANDLER for 1062 SET done=1;
#执行插入操作,插入过程中可能发生主键重复,如果主键重复那么done被赋值为1
insert into test(id,name) values(1,'xiaowang');
#如果done的值为1的话,实现更新原有数据
if done = 1 then
update test set name='xiaowang' where id=1;
end if;
END
执行存储过程后结果截图(各位可以尝试建表操作),功能实现
4、如果在insert语句末尾指定了on duplicate key update
insert into test(id,name) values(1,'如来') on duplicate key update name=values(name); #on duplicate key update 后面加入如果主键重复更新的列和更新的值,这里面更新test表的name列,更新的值是values('如来'),但是要写成values(name).
运行截图,实现将已有数据更新的效果

插入不同数据,如果主键不同,则插入

看一下主键相同情况是否可以更新多列,(可以执行)

MySQL根据表注释查找对应的表
SELECT table_name ,TABLE_COMMENT,COLUMN_NAME, DATA_TYPE, IS_NULLABLE, COLUMN_DEFAULT
FROM INFORMATION_SCHEMA.COLUMNS //INFORMATION_SCHEMA.TABLES
WHERE table_name LIKE 'tbl_name'
[AND table_schema = 'db_name']
常用
Select table_name ,TABLE_COMMENT from INFORMATION_SCHEMA.TABLES
Where `TABLE_NAME` like 'S_XM_MAPPING'hive -mysql 日期比较
SELECT CASE WHEN '2020-01-01' >= '2020-01' AND '2020-01-31' < '2020-02' THEN 'T' ELSE 'F' END
SELECT CASE WHEN '20200101' >= '202001' AND '20200131' < '202002' THEN 'T' ELSE 'F' END
SELECT CASE WHEN 20200101 >= 202001 AND 20200131 < 202002 THEN 'T' ELSE 'F' END'
结果分别是TTF