【论文笔记】Bidirectional Attention Flow for Machine Comprehension(2017)
这篇论文提出了经典的BiDAF模型,即使现在BERT出现,但这篇论文提出的模型仍是具有参考价值,并且这篇论文中对模型和注意力机制进行了详细的探究,帮助我们加深理解整个机器阅读理解过程。
1.介绍
在2017年,注意力机制已经被很广泛地应用,在机器阅读理解( machine comprehension,MC)中,注意力机制被用于聚焦上下文中与问题最相关的一段,从而实现一种信息提取的作用。
在其他论文中的另一种表述是,注意力机制具有软对齐的作用,能让两项不同长度(或其他属性)的信息进行对齐,从而结合他们的信息,或者是用一项信息去提取另一项中的关键信息。实际上这两种表述相同,但描述的是不同方面。
作者认为当时在端对端的MC任务中,注意力机制主要有三种方式:
- 使用所谓的“动态注意力”,意思是对当前的time-step时间步骤,注意力的计算中包括之前时间步骤的注意力输出。这通常是将LSTM与注意力机制相结合。
- 只计算一次注意力权重,并将它们送入输出层进行预测。(这里作者可能是指将注意力权重与输入序列结合变为一个固定长度向量这种方式)
- 在多层之间反复计算一个问题和上下文之间的注意力向量,通常称为多跳结合内存网络和强化学习,以动态控制跳数。(论文:Iterative alternating neural attention for machine reading,Gated-attention readers for text comprehension, Reasonet: Learning to stop reading in machine comprehension)
而作者提出BiDAF,计算了两种注意力(从上下文到问题,以及从问题到上下文),将这种计算方式称为“双向的”。
另外,作者在计算注意力时没有使用动态注意力,认为这减少了内存消耗。
这种方式在实验中与动态注意力相比,带来了准确率的提升,作者推论这是由于让注意力层和建模层(指在注意力层之后的LSTM)的分工更加明确,让建模层更专注从表示中学习交互模式,让注意力层不受前一时间步骤错误信息的误导,并且,作者认为由于使用了这种分离加双向的模式,能够让问题和上下文的信息相互“流动”。
2.模型
先放图:

模型实际上有很多博客已经详细描述了,在这里我只简单描述结构供下文分析。
如需详细了解模型,建议直接从作者的github查看源码,TensorFlow版: allenai.github.io/bi-att-flow/
其他人对BiDAF的PyTorch版本的实现:https://github.com/galsang/BiDAF-pytorch
2.1 Character Embedding Layer
对原文使用了Char-CNN,进行了字符级的词嵌入。
Char-CNN 相关论文:Yoon Kim. Convolutional neural networks for sentence classification. In EMNLP, 2014.
2.2 Word Embedding Layer
使用GloVe进行词嵌入。并且与上文的Character Embedding进行拼接,输入两层Highway网络。
2.3 Contextual Embedding Layer
将刚才的表示使用Bi-LSTM进行编码,得到文本序列的上下文相关表示。
形式化的表示,这一层的输出是 H ∈ R 2 d × T H \in R^{2d×T} H∈R2d×T 和 U ∈ R 2 d × J U \in R^{2d×J} U∈R2d×J 两个矩阵。
其中 d d d是词嵌入和字符嵌入得到的表示的长度, T T T和 J J J分别表示上下文和问题的长度。到这一步位置,问题和上下文是分开并行处理的。
2.4 Attention Flow Layer
这一层进行注意力的计算,首先得到相似度矩阵 S ∈ R T × J S \in R^{T×J} S∈RT×J,其中
S t , j = α ( H : , t , U : , j ) S_{t,j}=\alpha(H_{:,t}, U_{:,j}) St,j=α(H:,t,U:,j)
α \alpha α是一个计算两个向量之间相似度的可训练的标量函数。在论文中,作者选取:
α ( h , u ) = w S T [ h ; u ; h ○ u ] \alpha(h,u)=w^{T}_{S}[h;u;h○u] α(h,u)=wST[h;u;h○u]
其中";"代表拼接向量,"○"代表按位乘。
在计算Context-to-query Attention时,作者令
a t = s o f t m a x ( S t , : ) ∈ R J a_t=softmax(S_{t,:}) \in R^J at=softmax(St,:)∈RJ
U ^ : , t = ∑ j J a t , j U : , j \hat{U}_{:,t}=\sum_j^Ja_{t,j}U_{:,j} U^:,t=j∑Jat,jU:,j
得到了 U ^ ∈ R 2 d × T \hat{U}\in R^{2d×T} U^∈R2d×T.
在计算Query-to-context Attention时,作者令
b = s o f t m a x ( m a x c o l ( S ) ) ∈ R T b=softmax(max_{col}(S)) \in R^{T} b=softmax(maxcol(S))∈RT
h ^ = ∑ t T b t H : , t ∈ R 2 d \hat{h}=\sum_t^Tb_tH_{:,t} \in R^{2d} h^=t∑TbtH:,t∈R2d
将 h ^ \hat{h} h^ 堆叠 T T T 次,就得到了 H ^ ∈ R 2 d × T \hat{H}\in R^{2d×T} H^∈R2d×T。
最后,再加上原有的上下文嵌入所表示的上下文,就构成了每个上下文词的问题感知(query-aware)表示 G G G G : , t = β ( H : , t , U ^ : , t , H ^ : , t ) G_{:,t}=\beta(H_{:,t},\hat{U}_{:,t},\hat{H}_{:,t}) G:,t=β(H:,t,U^:,t,H^:,t)
其中 β \beta β 是对这些信息的结合,在论文中,作者选取
β ( h , u ^ , h ^ ) = [ h ; u ^ ; h ○ u ^ ; h ○ h ^ ] \beta(h,\hat{u},\hat{h})=[h;\hat{u};h○\hat{u};h○\hat{h}] β(h,u^,h^)=[h;u^;h○u^;h○h^]
在这种情况下, G ∈ R 8 d × T G\in R^{8d×T} G∈R8d×T,也可以视情况选取MLP等操作作为 β \beta β。
2.5 Modeling Layer
建模层接收G作为输入,经过两层Bi-LSTM进行输出,得到 M ∈ R 2 d × T M\in R^{2d×T} M∈R2d×T,这是获取问题感知(query-aware)表示 G G G 的内部相互作用的编码。
2.6 Output Layer
这一层是问题相关的。在QA任务中,需要从文章的内部摘出一段作为回答,即给出一个开始位置和一个结束位置,分别表示为 p 1 p1 p1和 p 2 p2 p2。
在计算 p 1 p1 p1时,简单地通过一个全连接层并做softmax得到概率:
p 1 = s o f t m a x ( w p 1 T [ G ; M ] ) p^1=softmax(w^T_{p^1}[G;M]) p1=softmax(wp1T[G;M])
需要注意的是这里得到的是长度为 T T T的向量,使用 a r g m a x argmax argmax操作得到 p 1 p1 p1。
对于 p 2 p2 p2,通过如下计算得到:
p 2 = s o f t m a x ( w p 2 T [ G ; B i L S T M ( M ) ] ) p^2=softmax(w^T_{p^2}[G;BiLSTM(M)]) p2=softmax(wp2T[G;BiLSTM(M)])
即对M又进行了一次BiLSTM操作,作者没有对这个操作进行解释。
2.7 LOSS
作者将 p 1 p1 p1和 p 2 p2 p2作为简单的分类看待,定义loss时简单地使用交叉熵相加的形式:
L ( θ ) = − 1 N ∑ i N l o g ( p y i 1 1 ) + l o g ( p y i 2 2 ) L(\theta)=-\frac{1}{N}\sum^{N}_{i}log(p^1_{y_i^1})+log(p^2_{y_i^2}) L(θ)=−N1i∑Nlog(pyi11)+log(pyi22)
3.分析
3.1 消融分析(ablation)
作者对模型的各个部分做了消融分析,以分析各层的作用和贡献。

可以看出,char和word的embedding都起了作用,这是一个经典想法,char embedding可以更好地处理OOV问题,而word embedding可以提供一些语义解释。
两个方向的Attention都有很大的作用。值得一提的是,作者在对C2Q方向的注意力消融时,是将对问题的contextual embedding layer 输出的平均值作为 U ^ \hat{U} U^。而在Q2C方向,则是直接不加入(也许是发现这部分作用没那么大哈哈,我也没做过实验)。
而是用动态注意力机制,准确率反而下降了。推测这是由于将注意力层与建模层分开,可以让前四层专注于学习特征,使得特征更加丰富,之后共同输入进建模层,建模相互关系。
作者也尝试使用了不同的 α \alpha α和 β \beta β,不详细描述了。
3.2 表示层分析
作者首先摘取出一些在问题中高频出现的词汇(When,Where…),分析其不同的表示,具体做法是,在word embedding层和contextual embedding层,将和它们的表示余弦相似度最高的几个词拿出来比较,得到下表:
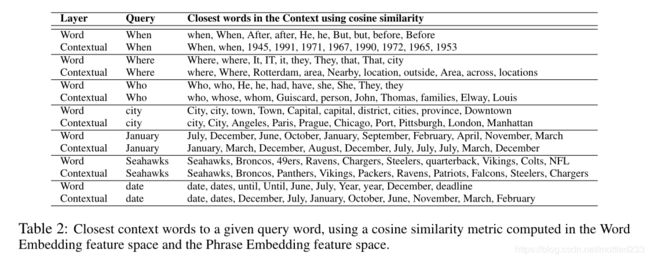
可以看出,在word层,词更会和他们的近义词邻近。但在contextual层,这些词与他们的答案的可能形式更加临近。
作者还举了另外的例子,对英语中的“May”,这是个多义词,它既有五月的意思,又有可能的意思。
分别在word层和contextual层,将其使用t-SNE进行降维后可视化得到下图:

可以看出在进入contextual层后,原本的语义被分开了,更贴合于实际。
之前我在Danqi Chen的综述中,对注意力机制的理解是:注意力实际上就是做相似的匹配,基于的是“问题和答案具有相同的形式”这一前提。但是在阅读这篇文章时,我发现我之前存在一个误区,就是“相似性”这一概念。我之前以为的相似性是之前说的word级,但我忽略了相似性也是可以训练的。在训练的过程中,这些层会令“相似”这一概念从字面的相似。但是,这种技术实际上还是一种统计意义上的模式匹配。虽然可以解决很多信息抽取类的问题,但会依然还无法真正将语义信息融入到模型中,这也是这个领域的究极难题吧。
最后,作者对于一个样本,对计算出的相似性矩阵 S S S进行了可视化:

图片左边是上下文,答案用红字标出,中间是相似性矩阵,右边是颜色最深的代表的几个词。颜色越深表示值越大。
作者简单地利用了softmax和max来对相似性矩阵进行操作,但这一步可否利用一些更复杂的操作?但是这样又破坏了注意力机制的完整,还需要研究。
3.3 错误分析
作者抽出了50个被错误分类的样例进行分析,根据原因将它们分为六类,分别是:
- 边界划分不准确
- 复杂语法和歧义
- 释义错误
- 需要外部知识
- 需要多段话来回答
- 在tokenization时将其错误拆分或合并造成的错误
其中,第一类错误可以被理解为是模型误差,第四第五类错误可以被理解为是模型本身没有被设计为回答这类问题,第二第三类问题来源于这种匹配模式带来的固有缺陷,第六类错误是语言工具带来的错误。在这里我更深切地理解了之前Danqi Chen提到过的当前MC的缺陷和前景,一是匹配模式存在瓶颈,需要开发更能理解语义的模式,二是外部知识引入。
4. 完形填空
作者将输出层略作改动,将模型运用到完形填空任务中。在这个任务中,因为只回答一个实体,所以只预测 p 1 p1 p1就足够,另外,还在输出层mask掉了所有非实体的词,并对于一个实体多次出现的问题,将所有出现的可能性的值相加。我觉得这是一个很好的trick。