kafka初步介绍
kafka是什么
kafka是一个高吞吐量的分布式的发布订阅消息系统。

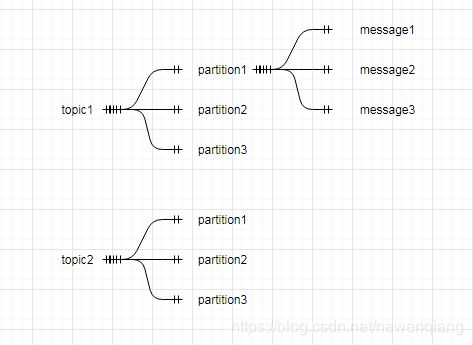
kafka数据结构
我们以关系型数据库为例子,toppic好比数据表,partition好比数据库分区,每个分区下面是每条消息(数据)。
kafka集群结构
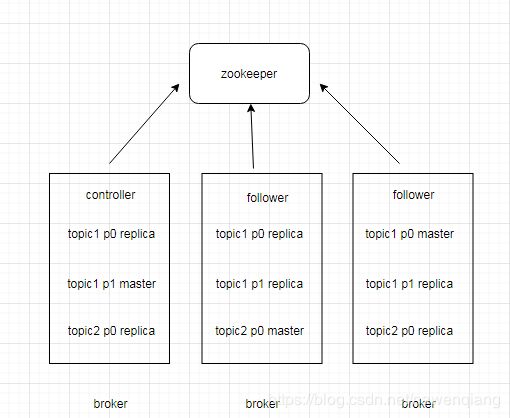
controller选取方法:谁先在zookeeper创建元数据,谁就是controller;
controller与follower区别:
controller和follower都会监听zookeeper,controller出问题,follower会竞争controller;
controller用于同步元数据,比如,创建topic时,主题元数据会存储在zookeeper和controller中,follower会从controller同步元数据,所以整个系统都存储了元数据;
数据安全性实现:每个partition都有主和从,从用于同步数据保证数据安全,主用于读写,供消费者生产者使用;
数据位置记录:生产offset、消费offset,生产者和消费者会对其offset进行操作
kafka能力分析:
kafka是高并发,高性能,高可用的消息系统;
高可用:我们从上面的broker的controller、follower以及partition的replica可以看出他的高可用性;
高并发:网络模块处理,达到高并发效果;
高性能:在高并发的前提下,我们需要高性能才能维护高并发,通过高效利用CPU,内存,硬盘达到效果;
kafka模块分析:
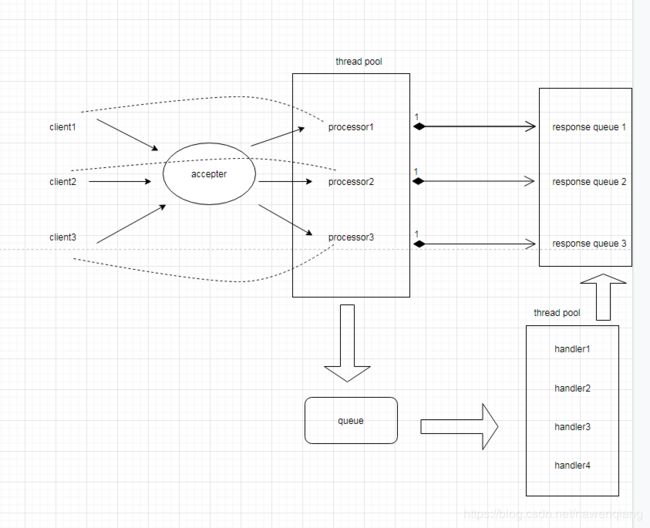
网络模块:
NIO模型配合reactor模式
num.io.threads handler线程数目
num.network.threads processor线程数目
磁盘模块:
1. 磁盘顺序读写性能远高于随机读写;
2. partition会生成很多小文件,其中,log文件存储数据,index文件存储索引信息(记录offset,磁盘物理位置),且成对出现,文件名是以log文件第一条信息偏移量命名;
3.零拷贝 节约两次拷贝(系统缓存到进程,socket缓存到网卡)
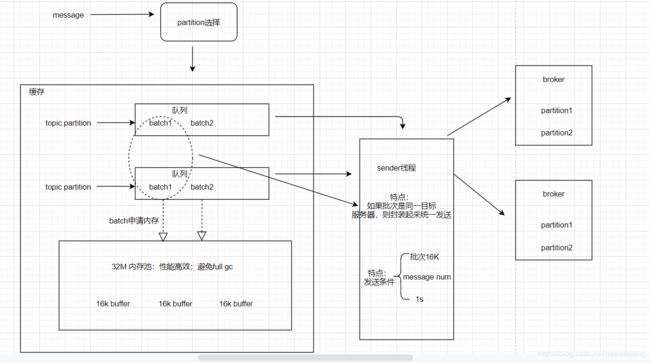
producer设计:
生产:消息-》封装为ProducerRecord-》序列化-》partition选择-》缓存-》sender线程(批处理)-》broker-》系统缓存-》磁盘(定时刷新)
生产结构:
consumer设计:
p2p模型:同一条消息只能被一个消费者消费
发布订阅模型:允许消息被多个消费者消费,需要订阅topic的所有partition
consumer group设计:
同一组ID的消费者属于P2P模型,一个消息只能被同一个组的一个消费者消费;
不同组ID的消费者属于发布订阅模式;一个消息可以被不同组的消费者消费;
一个partition同一时间只会被一个消费者消费;
消费offset存储:
_consumer_offsets topic,默认50个分区
消费:offset通过跳表算法查找对应文件,然后,查看是否在系统缓存中(在则拷贝到网卡,结束),否则通过稀松索引index文件找到offset所在磁盘物理位置,然后,加载到系统缓存,拷贝到网卡,结束;