从机器学习概论到房价回归预测
一、机器学习
机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。它的研究与应用方向包括:图像识别、自然语言处理、语音识别、搜索与推荐、语音助手、预测分析等,其中机器学习研究分为:传统的机器学习方法、深度学习方法。
传统机器学习方法包含监督学习和非监督学习:监督学习:(训练模型使用的数据集有已知label,通常通过训练模型,使得预测值和真实值最小化);非监督学习:(么有已知的label,通过数据集特征的相似性来对数据分类,如用户分割:将用户划分到不同的组别中,并根据簇的特性而推送不同的广告欺诈检测:发现正常与异常的用户数据,识别其中的欺诈行为)
分类:决策树(ID3(运用信息增益选择特征建立分类树)、C4.5(运用信息增益比选择特征建立分类树))、KNN、SVM、神经网络、EM、贝叶斯分类、集成方法 (监督)
回归:线性回归、逻辑回归 (监督)
聚类:Kmeans、层次聚类、谱聚类等 (非监督)
机器学习的过程通常是:

二、 线性回归

例如:在西瓜问题上 学习到
![]()
也就意味着我们可以通过 色泽 根蒂 敲声 来识别一个西瓜是否是好瓜。
对于回归模型的学习模型可假设为:
![]()
其中 xi 为特征,θ为我们需要学习的参数。我们引入了代价函数(0-1损失函数 平方损失函数 指数损失函数 对数损失函数),建立的模型对真实数据的误差,叫建模误差(Modeling Error)。误差越低,模型对数据拟合度越高
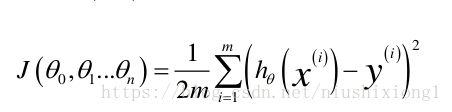 最小二乘法损失函数的概率意义(https://blog.csdn.net/lisi1129/article/details/68925799)
最小二乘法损失函数的概率意义(https://blog.csdn.net/lisi1129/article/details/68925799)
有了代价函数,我们的目的就是找到一组参数theta使得代价最小,稍有常识的人就能知道,这个函数肯定是有最小值的,不会出现负无穷下面两个标题就是讲了最小化J(有了代价函数,我们的目的就是找到一组参数theta使得代价最小,稍有常识的人就能知道,这个函数肯定是有最小值的,不会出现负无穷。
求代价函数的最值,我们通常采用最小二乘优化法(直接求导=0,矩阵可逆 计算量大)、梯度下降法、牛顿迭代法。https://blog.csdn.net/gumpeng/article/details/51191376
梯度下降法:
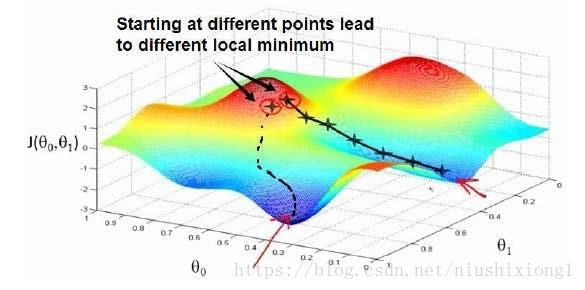
实际就是每次迭代一小步,沿着梯度方向,即坡最陡峭的方向走,这样下山才最快。
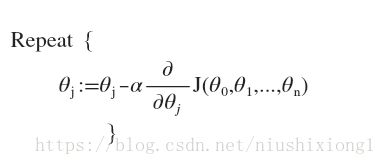
通过这种方法我们求得了函数模型的参数,我们将我们的测试数据输入方程中,得到函数的值作为输出,可用于分类和回归预测。代码实现参考https://blog.csdn.net/u013719780/article/details/77435158。
1 房价回归预测。(下面我们运用sklearn机器学习分类工具包)数据集用了波士顿房价数据集
每个样本包含特征:'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'
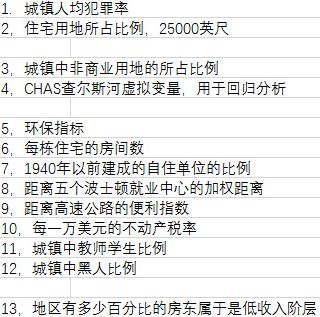 13个特征
13个特征
# 加载数据 from sklearn.datasets import load_boston from sklearn.preprocessing import scale from sklearn.cross_validation import train_test_split data = load_boston() X = data.data y = data.target #真实值 X_scaled = scale(X) #标准化 X_train,X_test,y_train,y_test = train_test_split(X_scaled,y,test_size = 0.3) #划分数据集 #线性模型 lasso from sklearn.linear_model import Lasso from sklearn.metrics import r2_score lasso = Lasso() y_pred_lasso = lasso.fit(X_train, y_train).predict(X_test) r2_score_lasso = r2_score(y_test, y_pred_lasso) print(r2_score(y_train,lasso.predict(X_train))) print(r2_score_lasso) # 线性模型 ElasticNet from sklearn.linear_model import ElasticNet enet = ElasticNet() y_pred_enet = enet.fit(X_train, y_train).predict(X_test) r2_score_enet = r2_score(y_test, y_pred_enet) print(r2_score(y_train,enet.predict(X_train))) print(r2_score_enet) #支持向量机做回归 from sklearn import svm svr = svm.SVR() svr.fit(X_train,y_train) y_pred_svr = svr.predict(X_test) print(r2_score(y_train,svr.predict(X_train))) print(r2_score(y_test,y_pred_svr)) # 深层网络,全连接 from keras.models import Sequential from keras.layers import Dense seq = Sequential() seq.add(Dense(13, activation='relu',input_dim=X.shape[1])) seq.add(Dense(13, activation='relu')) seq.add(Dense(1, activation='relu')) seq.compile(loss='mse', optimizer='adam') seq.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=200, batch_size=10) y_pred_neural = seq.predict(X_test) print(r2_score(y_test,y_pred_neural)) import pandas as pd df = pd.DataFrame(columns=['真实价格','DNN','SVR','ENET','LASSO']) df['真实价格']=y_test[:20] df['DNN'] = seq.predict(X_test[:20]).reshape(20,) df['SVR'] = svr.predict(X_test[:20]).reshape(20,) df['ENET'] = enet.predict(X_test[:20]).reshape(20,) df['LASSO'] = lasso.predict(X_test[:20]).reshape(20,) print(df) import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt def plotRealVsPredict(y_pred): t=np.arange(len(y_pred)) mpl.rcParams['font.sans-serif']=[u'simHei'] mpl.rcParams['axes.unicode_minus']=False plt.figure(facecolor='w') plt.plot(t,y_test.ravel(),'r-',lw=2,label=u'真实值') plt.plot(t,y_pred,'g-',lw=2,label=u'估计值') plt.legend(loc='best') plt.title(u'波士顿房价预测',fontsize=18) plt.xlabel(u'样本编号',fontsize=15) plt.ylabel(u'房屋价格',fontsize=15) plt.show() plt.grid() plotRealVsPredict(y_pred_lasso) plotRealVsPredict(y_pred_enet) plotRealVsPredict(y_pred_svr) plotRealVsPredict(y_pred_neural)