数仓分层 数据库仓库实战

回到顶部
数仓分层
ODS:Operation Data Store
原始数据
DWD(数据清洗/DWI) data warehouse detail
数据明细详情,去除空值,脏数据,超过极限范围的
明细解析
具体表
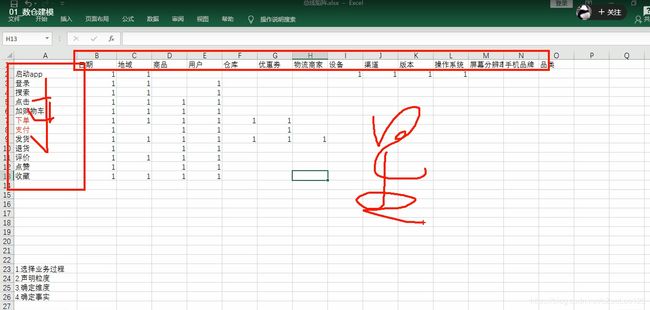
DWS(宽表-用户行为,轻度聚合) data warehouse service ----->有多少个宽表?多少个字段
服务层--留存-转化-GMV-复购率-日活
点赞、评论、收藏;
轻度聚合对DWD
ADS(APP/DAL/DF)-出报表结果 Application Data Store
做分析处理同步到RDS数据库里边
数据集市:狭义ADS层; 广义上指DWD DWS ADS 从hadoop同步到RDS的数据
回到顶部
数仓搭建之ODS & DWD
1)创建gmall数据库
hive (default)> create database gmall;
说明:如果数据库存在且有数据,需要强制删除时执行:drop database gmall cascade;
2)使用gmall数据库
hive (default)> use gmall;
1. ODS层
原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
① 创建启动日志表ods_start_log
1)创建输入数据是lzo输出是text,支持json解析的分区表

hive (gmall)> drop table if exists ods_start_log; CREATE EXTERNAL TABLE ods_start_log (`line` string) PARTITIONED BY (`dt` string) STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_start_log';
Hive的LZO压缩:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
加载数据;
时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
hive (gmall)> load data inpath '/origin_data/gmall/log/topic_start/2019-02-10' into table gmall.ods_start_log partition(dt="2019-02-10"); hive (gmall)> select * from ods_start_log limit 2;
② 创建事件日志表ods_event_log
创建输入数据是lzo输出是text,支持json解析的分区表
drop table if exists ods_event_log; create external table ods_event_log (`line` string) partitioned by (`dt` string) stored as INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' location '/warehouse/gmall/ods/ods_event_log'; hive (gmall)> load data inpath '/origin_data/gmall/log/topic_event/2019-02-10' into table gmall.ods_event_log partition(dt="2019-02-10");
ODS层加载数据的脚本
1)在hadoop101的/home/kris/bin目录下创建脚本
[kris@hadoop101 bin]$ vim ods_log.sh
#!/bin/bash # 定义变量方便修改 APP=gmall hive=/opt/module/hive/bin/hive # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi echo "===日志日期为 $do_date===" sql=" load data inpath '/origin_data/gmall/log/topic_start/$do_date' into table "$APP".ods_start_log partition(dt='$do_date'); load data inpath '/origin_data/gmall/log/topic_event/$do_date' into table "$APP".ods_event_log partition(dt='$do_date'); " $hive -e "$sql"
[ -n 变量值 ] 判断变量的值,是否为空
-- 变量的值,非空,返回true
-- 变量的值,为空,返回false
查看date命令的使用,[kris@hadoop101 ~]$ date --help
增加脚本执行权限 [kris@hadoop101 bin]$ chmod 777 ods_log.sh 脚本使用 [kris@hadoop101 module]$ ods_log.sh 2019-02-11 查看导入数据 hive (gmall)> select * from ods_start_log where dt='2019-02-11' limit 2; select * from ods_event_log where dt='2019-02-11' limit 2; 脚本执行时间 企业开发中一般在每日凌晨30分~1点
2. DWD层数据解析
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据,行式存储改为列存储,改压缩格式)
DWD解析过程,临时过程,两个临时表: dwd_base_event_log、dwd_base_start_log
建12张表外部表: 以日期分区,dwd_base_event_log在这张表中根据event_name将event_json中的字段通过get_json_object函数一个个解析开来;
DWD层创建基础明细表
明细表用于存储ODS层原始表转换过来的明细数据。
1) 创建启动日志基础明细表:
drop table if exists dwd_base_start_log; create external table dwd_base_start_log( `mid_id` string, `user_id` string, `version_code` string, `version_name` string, `lang` string, `source` string, `os` string, `area` string, `model` string, `brand` string, `sdk_version` string, `gmail` string, `height_width` string, `app_time` string, `network` string, `lng` string, `lat` string, `event_name` string, `event_json` string, `server_time` string) partitioned by(`dt` string) stored as parquet location "/warehouse/gmall/dwd/dwd_base_start_log"
其中event_name和event_json用来对应事件名和整个事件。这个地方将原始日志1对多的形式拆分出来了。操作的时候我们需要将原始日志展平,需要用到UDF和UDTF。
2)创建事件日志基础明细表
drop table if exists dwd_base_event_log; create external table dwd_base_event_log( `mid_id` string, `user_id` string, `version_code` string, `version_name` string, `lang` string, `source` string, `os` string, `area` string, `model` string, `brand` string, `sdk_version` string, `gmail` string, `height_width` string, `app_time` string, `network` string, `lng` string, `lat` string, `event_name` string, `event_json` string, `server_time` string) partitioned by(`dt` string) stored as parquet location "/warehouse/gmall/dwd/dwd_base_event_log"
自定义UDF函数(解析公共字段)
UDF:解析公共字段 + 事件et(json数组)+ 时间戳
自定义UDTF函数(解析具体事件字段) process 1进多出(可支持多进多出)
UDTF:对传入的事件et(json数组)-->返回event_name| event_json(取出事件et里边的每个具体事件--json_Array)
解析启动日志基础明细表
将jar包添加到Hive的classpath
创建临时函数与开发好的java class关联
hive (gmall)> add jar /opt/module/hive/hivefunction-1.0-SNAPSHOT.jar; hive (gmall)> create temporary function base_analizer as "com.atguigu.udf.BaseFieldUDF"; hive (gmall)> create temporary function flat_analizer as "com.atguigu.udtf.EventJsonUDTF"; hive (gmall)> set hive.exec.dynamic.partition.mode=nonstrict;
1)解析启动日志基础明细表
insert overwrite table dwd_base_start_log partition(dt) select mid_id,user_id,version_code,version_name,lang,source,os,area,model,brand,sdk_version,gmail,height_width,app_time,network, lng,lat,event_name, event_json,server_time,dt from( select split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time, dt from ods_start_log where dt='2019-02-10' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>'' ) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
将ops lateral view 成event_name和event_json;
+-------------+-------------------------------------------------------------------------------------------------------------------------+----------------+--+
| event_name | event_json | server_time |
+-------------+-------------------------------------------------------------------------------------------------------------------------+----------------+--+
| start | {"ett":"1549683362200","en":"start","kv":{"entry":"5","loading_time":"4","action":"1","open_ad_type":"1","detail":""}} | 1549728087940 |
+-------------+-------------------------------------------------------------------------------------------------------------------------+----------------+--+
解析事件日志基础明细表
1)解析事件日志基础明细表
insert overwrite table dwd_base_event_log partition(dt='2019-02-10') select mid_id,user_id,version_code,version_name,lang,source,os,area,model,brand,sdk_version,gmail,height_width,app_time,network, lng,lat,event_name, event_json,server_time from( select split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[0] as mid_id, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[1] as user_id, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[2] as version_code, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[3] as version_name, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[4] as lang, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[5] as source, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[6] as os, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[7] as area, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[8] as model, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[9] as brand, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[10] as sdk_version, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[11] as gmail, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[12] as height_width, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[13] as app_time, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[14] as network, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[15] as lng, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[16] as lat, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[17] as ops, split(base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la'),'\t')[18] as server_time from ods_event_log where dt='2019-02-10' and base_analizer(line,'mid,uid,vc,vn,l,sr,os,ar,md,ba,sv,g,hw,t,nw,ln,la')<>'' ) sdk_log lateral view flat_analizer(ops) tmp_k as event_name, event_json;
测试 hive (gmall)> select * from dwd_base_event_log limit 2;
DWD层加载数据脚本
1)在hadoop101的/home/kris/bin目录下创建脚本
[kris@hadoop101 bin]$ vim dwd.sh
 View Code
View Code
[kris@hadoop101 bin]$ chmod +x dwd_base.sh [kris@hadoop101 bin]$ dwd_base.sh 2019-02-11 查询导入结果 hive (gmall)> select * from dwd_start_log where dt='2019-02-11' limit 2; select * from dwd_comment_log where dt='2019-02-11' limit 2; 脚本执行时间 企业开发中一般在每日凌晨30分~1点
3. DWD层
1) 商品点击表
View Code
2 )商品详情页表
View Code
3 )商品列表页表
View Code
4 广告表
View Code
5 消息通知表
View Code
6 用户前台活跃表
View Code
7 用户后台活跃表
View Code
8 评论表
View Code
9 收藏表
View Code
10 点赞表
View Code
11 启动日志表
View Code
12 错误日志表
View Code
DWD层加载数据脚本
1)在hadoop101的/home/kris/bin目录下创建脚本
[kris@hadoop101 bin]$ vim dwd.sh
View Code