Cooperative Holistic Scene Understanding: Unifying 3D Object, Layout, and Camera Pose Estimation2018
加利福尼亚大学洛杉矶分校, RGB,整体场景理解(目标检测、布局检测、相机位姿预测)
总结:
以单个RGB图像为输入,提出了一种实时(2.5fps)恢复三维室内场景的端到端模型,包括三维房间布局、相机位姿和目标边界框。引入三维目标框的参数化和二维投影loss,增强了二维与三维的一致性,设计了可微的协同loss,有助于两个主要模块的协同高效训练。
以往的三维重建和整体场景理解通过增加一些2D-3D约束来维持2D-3D的一致性,而本文使用新的参数化方法使得一开始就解决了一致性的问题。
论文摘要
3D整体室内场景的理解需要联合获取目标框、室内布局以及相机位姿多个方面的3D数据,现有方法只能解决部分问题,并不能同时解决以上三个问题。
本文提出了一个端到端的模型,能够根据输入的RGB图像 同时解决目标检测、布局检测、相机定位三个任务。
该方法的特点:
- 将目标参数化,而不是直接预测目标框
- 多个模块之间联合训练,而不是单独分开训练
该方法的优势:
- 参数化能够保留2D图像于三维世界之间的一致性,极大地减小了三维坐标的预测方差。
- 可同时对不同模块的参数化施加约束, 这些约束使联合训练和推理成为可能,因此称为“联合损失”。 作者对三维边界框、二维投影和物理约束采用三种联合损失来估计几何上一致且物理上合理的三维场景
在SUN-RGBD数据集上的实验表明,该方法在三维目标检测、三维布局估计、三维像机位置估计和整体场景理解等方面都明显优于现有方法
背景介绍
整体场景理解的困难之处在于:输入为有限的RGB信息,但是需要从其中恢复出大量未知的三维信息。整体场景理解包含三个任务:
- 估计三维相机位姿,以维护RGB图像于三维世界之间的一致性
- 估计三维房间布局,联合相机位姿则可以恢复全局几何
- 检测三维目标框,恢复场景中的局部细节
现有方法可以分为:
- 基于采样和优化的方法:计算量大,收敛慢,容易困在局部极小值,鲁棒性和泛化性均不好
- 基于深度学习的方法:没有采用联合训练的模式,而是分开训练,进而损失了一些约束条件
- 输入冗余的方法:把RGBD和相机位姿作为输入,提供了充足的几何信息,因而更少依赖于不同模块之间的协调一致。
本文方法不属于以上任何一种: 仅从一幅RGB图像中恢复真实的几何一致和物理上合理的三维场景,并以高效、协同的方式共同解决所有三个任务。 具体的,本文解决了一下三个问题:
- 如何维护2D-3D坐标之间的一致性?
- 如何设计算法使得能够协同各个任务,不同的模块相互加强?
- 如何以一种物理上似乎合理的方式估计三维场景,或者至少具有某种物理意义?
论文提出的解决方法是:
- 提出了一种新的参数化3D目标框的方法,使得能够从2D目标框的中心重建3D目标框, 因此维护了2D-3D的一致性(相比于直接预测相机位姿的方法)。 参数化的另一个优点是通过减少3D目标框预测的方差来提高训练的稳定性,因为估计的2D偏移具有相对较低的方差,并且论文采用分类和回归的混合方法来估计方差较大的变量。
- 联合损失函数: 除了原有的损失之外,参数化还将带来合作损失,以实现所有单个模块之间的联合训练。 具体的,在参数化上使用三个合作损失来分别约束3D边界框、投影2D边界框和物理真实性。
- 三维目标框损失有助于精确的三维估计
- 可导的2D投影损失度量了3D和2D边界框之间的一致性,这使得网络只需要2D标签就可以学习3D结构,而不需要3D的标签
- 物理合理性损失负责惩罚重建的三维目标盒和三维房间布局之间的重叠,这促使网络产生物理合理的估计
综上,论文的贡献为:
- 提出了一个端到端的多任务联合预测的全场景理解模型
- 提出了一种新颖的三维目标框的参数化方法,并结合物理约束,实现了多个任务的协同训练。
- 通过在二维和三维边界框之间引入可导的目标函数来缩小二维图像平面和三维世界之间的差距
- 该方法明显优于最新的SOTA方法,并且能够实时运行
论文方法
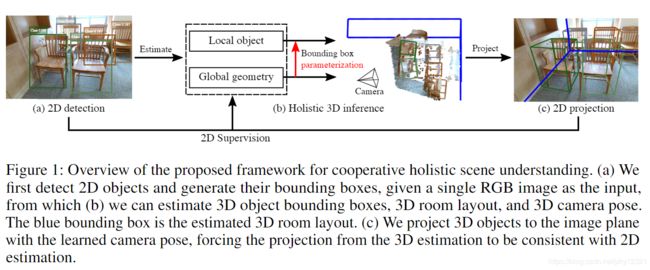
论文框架概述:
- 根据RGB输入来检测2D目标框
- 根据RGB图像以及预测的2D目标框,global geometric network(GGN) 负责预测三维房间布局以及相机位姿, local object network(LON) 负责推断每个目标的三维目标框
- 根据所估计的相机姿态将三维目标投影到图像平面上,迫使来自三维估计的投影与二维估计一致
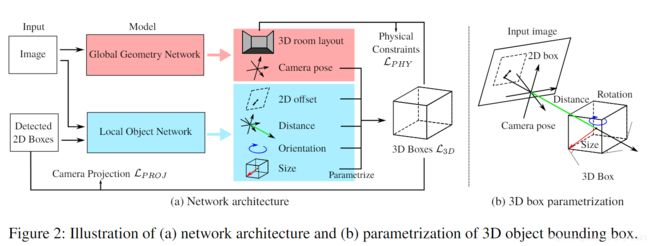
1. 参数化
1.1 3D目标框Xw∈R3×8
其中h(.)是三维目标框的生成函数,三维中心Cw∈R3,尺寸Sw∈R3,朝向 R(θw)∈R3×3, θ 为沿着垂直轴的朝向角。
预测三维中心Cw∈R3
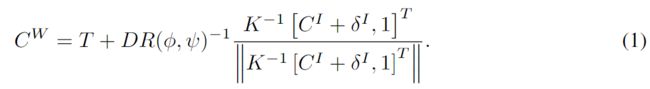
其中R(φ,ψ),T为相机位姿,K为相机内参,D为相机中心到三维目标中心的距离, CI为2D目标框的中心坐标, δI为2D目标框中心到3D目标框中心投影到2D的偏移。
当数据以第一人称视角采集时,T=0,此时上式变为一个可导的仿射变换,可以写为:
这样就实现了将3D中心CW与2D中心CI参数化的目的,减少了3D目标框预测时的误差。同时结合了目标检测与相机位姿预测模块的信息,实现了两个网络的联合预测。
1.2 预测3D房间布局
将世界坐标系中的三维房间布局参数化为一个三维目标框XL ∈R3×8,
包括: 3D 中心CL∈R3, 尺寸SL∈R3, 朝向R(θL)∈R3x3,
本文通过预测与预先计算的平均布局中心的偏移量 来估计房间布局的中心
2.直接预测
-
GGN( global geometry network ):(输入:RGB图像)
三维布局与相机位姿的预测均依赖于底层级的全局几何特征,因此使用GGN( global geometry network )预测。预测的具体参数为:3D 中心CL∈R3, 尺寸SL∈R3, 朝向R(θL)∈R3x3,以及相机的转向角 φ、ψ。 -
local object network(LON) :(输入: 2D image patches )
LON负责目标检测,预测: 距离D,目标尺寸SW, 朝向θW, 2D 偏移δI
两个网络的损失函数为:
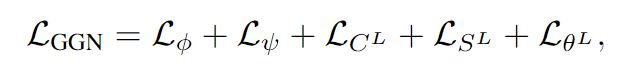
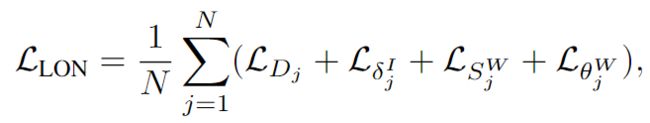
N为场景中的目标数目。
实际中直接预测目标的信息(如朝向角)会导致非常大的error,因此作者采用了二阶段的基于bins的检测方法。
具体来说,预先定义了几个大小模板,或者将空间平均分割成一组角度bin。模型首先将大小和航向角度分类到那些预先定义的类别,然后预测每个类别中的残差。例如,在旋转角φ的情况下,定义:
![]()
Softmax用于分类,smooth-L1(Huber)损失用于回归。
3.联合预测
使用三个联合损失函数实现两个网络之间的联合优化:
-
3D Bounding Box Loss:
由于GGN和LON都不是直接预测出结果,因此从两个网络直接学习是不够的,这里采用目标框的8角点的损失
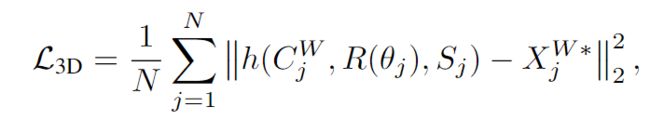
其中XW*表示3D目标框的真值 -
2D Projection Loss :
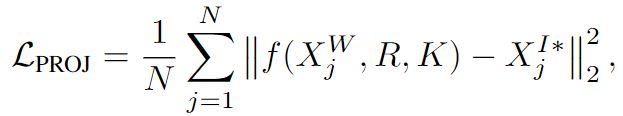
其中f(.)表示可导的投影函数(3D到2D),XI*j表示2D目标框真值。
-
Physical Loss :
该损失负责惩罚3D目标框与房间布局之间的重叠部分。
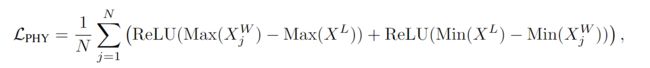
Max(·)/Min(·)函数的输入为3D目标框,输出为目标框在三个轴上的最大/最小值。
最终,总的损失函数为:
![]()
λcoop为权重参数,调节direct loss与cooperative loss的权重
实现细节
GGN与LON都是用ResNet34作为encoder,将256X256的图像编码为2048的特征向量。在后面加两个全连接层 (2048-1024, 1024-L) 负责输出预测值。
训练分为2步:
- 首先用最常见的30个目标类别fine-tune二维目标检测器。
- 训练GGN和LON。为了更好的初始化,先在 SUNCG 上单独训练这两个网络。然后固定他们的6个blocks,在 SUN RGBD 上进行联合的训练。
实验评估
数据集: SUN RGB-D
分为5个方面进行评估:
- 3D layout estimation
- 3D object detection
- 3D boxestimation
- 3D camera pose estimation
- holistic scene understanding
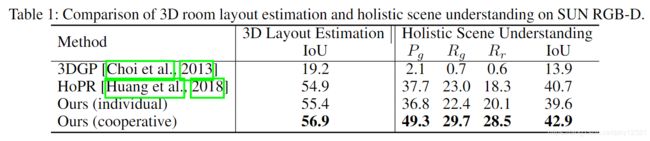
3D layout estimation
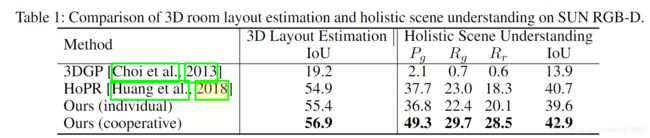
3D object detection

3D box estimation

3D camera pose estimation
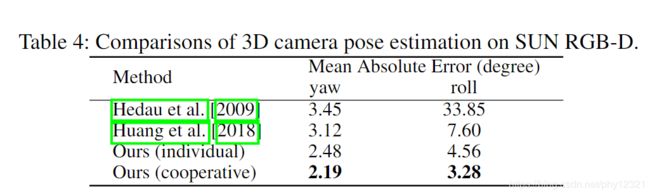
holistic scene understanding
实时性:2.5fps,on a single titan Xp