用Selenium进行百度搜索结果简单提取
利用Selenium访问百度,输入搜索关键字后,提取搜索页面的查询结果。
1. 以headless chrome方式访问百度首页
#chrome选项
options = webdriver.ChromeOptions()
#使用无头chrome
options.set_headless()
#配置并获得WebDriver对象
driver = webdriver.Chrome(
'D://chromedriver_win32//chromedriver', chrome_options=options)
#发起get请求
driver.get('http://www.baidu.com/')2. 百度首页用来输入搜索关键词的组件是
使用selenium通过id,name或class的方式来获取到这个input标签,输入内容并提交:
input_element = driver.find_element_by_name('wd')
input_element.send_keys('python')
input_element.submit()通过name属性获得input标签后,输入要查询的内容是'python'
3. 等待百度的查询结果页:
当以python作为关键字查询时,百度返回查询结果页面时会在浏览器的标题(title)中包含查询的关键字:

所以利用这个特点,当WebDriver的标题中出现包含'python'的文字即说明百度返回了搜索结果页面
try:
#最多等待10秒直到浏览器标题栏中出现我希望的字样(比如查询关键字出现在浏览器的title中)
WebDriverWait(driver, 10).until(
expected_conditions.title_contains('python'))
finally:
#关闭浏览器
driver.close()4. 对搜索结果页中的内容进行提取:
首先是"百度为您找到相关结果约100,000,000个",这个结果是存放在一个span中:
百度为您找到相关结果约100,000,000个利用class属性可以找到标签span,并提取span中的文本,再进一步只提取其中的数字100,000,000
try:
#最多等待10秒直到浏览器标题栏中出现我希望的字样(比如查询关键字出现在浏览器的title中)
WebDriverWait(driver, 10).until(
expected_conditions.title_contains('python'))
print(driver.title)
bsobj = BeautifulSoup(driver.page_source)
num_text_element = bsobj.find('span', {'class': 'nums_text'})
print(num_text_element.text)
nums = filter(lambda s: s == ',' or s.isdigit(), num_text_element.text)
print(''.join(nums))
finally:
#关闭浏览器
driver.close()使用BeautifulSoup帮助提取内容。
利用页面的内容生成BeautifulSoup对象后,调用find方法找到class属性为nums_text的span标签,取出它的文本内容。
如果有必要,可以使用filter函数,过滤出文本内容中需要的部分(比如,数字和逗号)
5. 进一步利用BeautifulSoup提取结果页面中的链接和标题
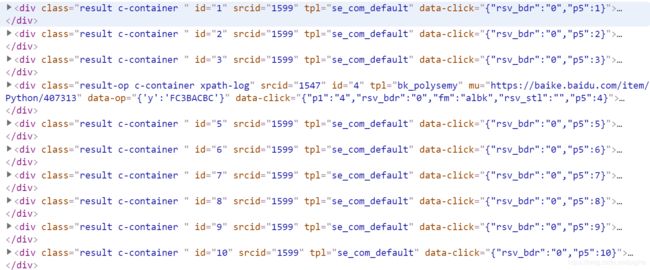
搜索结果是存放在class属性包含c-container的div标签中。
打开一个div标签:
可以看到在div标签下的h3标签下有一个a标签,这个a标签的href属性值就是一个搜索结果的链接地址,而a标签的文本内容就是一个搜索结果的文本内容。
try:
#最多等待10秒直到浏览器标题栏中出现我希望的字样(比如查询关键字出现在浏览器的title中)
WebDriverWait(driver, 10).until(
expected_conditions.title_contains('python'))
print(driver.title)
bsobj = BeautifulSoup(driver.page_source)
num_text_element = bsobj.find('span', {'class': 'nums_text'})
print(num_text_element.text)
nums = filter(lambda s: s == ',' or s.isdigit(), num_text_element.text)
print(''.join(nums))
elements = bsobj.findAll('div', {'class': re.compile('c-container')})
for element in elements:
print('标题:', element.h3.a.text)
print('链接:', element.h3.a['href'])
print(
'===============================================================')
finally:
#关闭浏览器
driver.close()为了提现class属性中包含c-container,所以使用了一个简单的正则表达式。
找到了div标签后,就很容易找到子孙标签a,打印a标签的href属性值和文本即可。