HDFS NameNode High Availability中一个关键的问题就是Editlog如何保存,怎么才能保证在Active和Standby的NameNode切换时Editlog不丢失记录,也不会重复计算。这就需要对NameNode的元数据持久化机制(metadata persistent storage)有比较深的理解。目前Hadoop EditLogs Re-write由Cloudera的工程师发起重构,有将近10000行代码,对整个EditLog整体架构进行重写,以适应Hadoop的进化。
目前HDFS的EditLog文件可以存放在多种容器里,比如Local Filesystem, shared NFS, Bookkeeper等(其对应的日志管理接口分别定义在FileJournalManager,BookkeeperJournalManager,BackupJournalManager等),而对应的管理这些不同容器内的文件的方法也有多种。目前主要是采用了基于transactionId的日志管理方法(FSImageTransactionalStorageInspector这个类是具体的实现方法)。这篇文章从NameNode的启动代码来分析metadata persistent storage。
例如,我们一般用如下命令格式化文件系统:
bin/hdfs namenode –format –clusterid eric
这个过程的函数调用关系如下图所示:
Main()->createNameNode()静态方法创建NameNode实例->根据参数进入format函数。
private static boolean format(Configuration conf, boolean force,
boolean isInteractive) throws IOException {
//首先是一系列的参数初始化,例如nsId(nameserviceid),namenodeId
String nsId = DFSUtil.getNamenodeNameServiceId(conf);
String namenodeId = HAUtil.getNameNodeId(conf, nsId);
initializeGenericKeys(conf, nsId, namenodeId);
checkAllowFormat(conf);
//获取存放FsImage(dfs.namenode.name.dir)
//和EditLog(包括dfs.namenode.shared.edit.dir和dfs.namenode.edit.dir)的目录。
Collection dirsToFormat = FSNamesystem.getNamespaceDirs(conf);
List editDirsToFormat =
FSNamesystem.getNamespaceEditsDirs(conf);
if (!confirmFormat(dirsToFormat, force, isInteractive)) {
return true; // aborted
}
// if clusterID is not provided - see if you can find the current one
String clusterId = StartupOption.FORMAT.getClusterId();
if(clusterId == null || clusterId.equals("")) {
//Generate a new cluster id
clusterId = NNStorage.newClusterID();
}
System.out.println("Formatting using clusterid: " + clusterId);
//下面三行开始正式创建FSImage,EditLog,FSNamesystem,然后把元数据写入磁盘文件。
FSImage fsImage = new FSImage(conf, dirsToFormat, editDirsToFormat);
FSNamesystem fsn = new FSNamesystem(conf, fsImage);
fsImage.format(fsn, clusterId);
return false;
}
然后我们分别看看最下面这三行代码是怎么创建和格式化文件系统的。
protected FSImage(Configuration conf,
Collection imageDirs,
List editsDirs)
throws IOException {
this.conf = conf;
//storage用于管理NameNode的元数据持久化存储在本地文件系统的文件和目录。
storage = new NNStorage(conf, imageDirs, editsDirs);
if(conf.getBoolean(DFSConfigKeys.DFS_NAMENODE_NAME_DIR_RESTORE_KEY,
DFSConfigKeys.DFS_NAMENODE_NAME_DIR_RESTORE_DEFAULT)) {
storage.setRestoreFailedStorage(true);
}
//声明与此FSImage相关的EditLog对象(包括shared和local)。
this.editLog = new FSEditLog(conf, storage, editsDirs);
String nameserviceId = DFSUtil.getNamenodeNameServiceId(conf);
//下面这个判断比较关键,如果HA机制没有开启,那么直接initJournalsForWrite()
//如果HA机制开启,那么initSharedJournalsForRead()
if (!HAUtil.isHAEnabled(conf, nameserviceId)) {
editLog.initJournalsForWrite();
} else {
editLog.initSharedJournalsForRead();
}
archivalManager = new NNStorageRetentionManager(conf, storage, editLog);
}
我们重点看下EditLog是怎么initJournalsForWrite()和initSharedJournalsForRead()的。
特意把这两个函数放在一起对照着看,因为新版的HDFS已经把EditLog的不同时期划分为不同的状态。目前有以下几种状态:
private enum State {
UNINITIALIZED,
BETWEEN_LOG_SEGMENTS,
IN_SEGMENT,
OPEN_FOR_READING,
CLOSED;
}
这两个函数首先都是检查EditLog的状态,然后初始化Journals,最后设置成新的状态。要特别注意初始化Journal和打开Journal的区别。
对于非HA机制的情况下,EditLog应该开始于UNINITIALIZED或者CLOSED状态(因为在构造对象时,EditLog的成员变量state默认为State.UNINITIALIZED)。初始化完成之后进入BETWEEN_LOG_SEGMENTS状态,表示前一个segment已经关闭,新的还没开始,已经做好准备了。在后面打开服务的时候会变成IN_SEGMENT状态,表示可以写EditLog日志了。
对于HA机制的情况下,EditLog同样应该开始于UNINITIALIZED或者CLOSED状态,但是在完成初始化后并不进入BETWEEN_LOG_SEGMENTS状态,而是进入OPEN_FOR_READING状态(因为目前NameNode启动的时候都是以Standby模式启动的,然后通过dfsHAAdmin发送命令把其中一个Standby的NameNode转化成Active的)。
public synchronized void initJournalsForWrite() {
Preconditions.checkState(state == State.UNINITIALIZED ||
state == State.CLOSED, "Unexpected state: %s", state);
initJournals(this.editsDirs);
state = State.BETWEEN_LOG_SEGMENTS;
}
public synchronized void initSharedJournalsForRead() {
if (state == State.OPEN_FOR_READING) {
LOG.warn("Initializing shared journals for READ, already open for READ",
new Exception());
return;
}
Preconditions.checkState(state == State.UNINITIALIZED ||
state == State.CLOSED);
initJournals(this.sharedEditsDirs);
state = State.OPEN_FOR_READING;
}
这两个函数都调用了initJournals(List dirs)这个函数用于初始化日志系统。
private synchronized void initJournals(List dirs) {
int minimumRedundantJournals = conf.getInt(
DFSConfigKeys.DFS_NAMENODE_EDITS_DIR_MINIMUM_KEY,
DFSConfigKeys.DFS_NAMENODE_EDITS_DIR_MINIMUM_DEFAULT);
//JournalSet就是存放一系列的JournalAndStream的容器
//对于容器中的一个元素JournalAndStream表示一个JournalManager和一个输出流
//JournalManager有多种实现,例如FileJournalManager,
//BookkeeperJournalManager,BackupJournalManager等。
journalSet = new JournalSet(minimumRedundantJournals);
for (URI u : dirs) {
boolean required = FSNamesystem.getRequiredNamespaceEditsDirs(conf)
.contains(u);
//对于这些dirs,如果从scheme中得知其是本地文件系统的目录,
//那么这个Journal对应的JournalManager为FileJournalManager,并把其加入JournalSet
if (u.getScheme().equals(NNStorage.LOCAL_URI_SCHEME)) {
StorageDirectory sd = storage.getStorageDirectory(u);
if (sd != null) {
journalSet.add(new FileJournalManager(sd, storage), required);
}
} else {
//如果不是本地文件,有可能是BookKeeperJournalManager或者类似的插件式JournalManager,
//那么根据配置文件dfs.namenode.edits.journal-plugin.*生成对应的JournalManager。
journalSet.add(createJournal(u), required);
}
}
if (journalSet.isEmpty()) {
LOG.error("No edits directories configured!");
}
}
至此FSImage fsImage = new FSImage(conf, dirsToFormat, editDirsToFormat);这行代码所涉及到的内容分析完毕。
然后看FSNamesystem fsn = new FSNamesystem(conf, fsImage);这行代码都干了啥。FSNamesystem这个构造函数在FSNamesystem.java的411-482行,首先获取resourceRecheckInterval,生成BlockManager对象、usergroup信息、supergroup等。然后设置了一个很重要的变量persistBlocks。我们都知道在hadoop中Block location信息是启动时由DataNode向NameNode汇报的,并没有持久化。但是这里增加了这个参数,并且在开启HA机制时,persistBlocks设置为true,也就是在shared edit directory中保存block location的信息。这个难道是为了节省启动集群时block report的时间?但是这样做和Hadoop/GFS的初衷就不一样了。(注:后来进一步分析代码得知,这里的persistBlocks是持久化block的元数据,例如GS、大小等,但是并不包括block的replica都分布在哪些DataNode上,这个信息还是得靠DataNode report给NameNode的) 然后就是设置这个HDFS文件系统的一些默认参数(blockSize,bytesPerChecksum,writePacketSize,replication,fileBufferSize)和一系列文件系统相关变量信息。最后调用this.dir = new FSDirectory(fsImage, this, conf);这行代码生成目录树相关的信息。然后调用fsImage.format(fsn, clusterId);把这些元数据信息持久化到dfs.namenode.name.dir,dfs.namenode.edit.dir,dfs.namenode,shared.edit.dir中。生成以下文件:
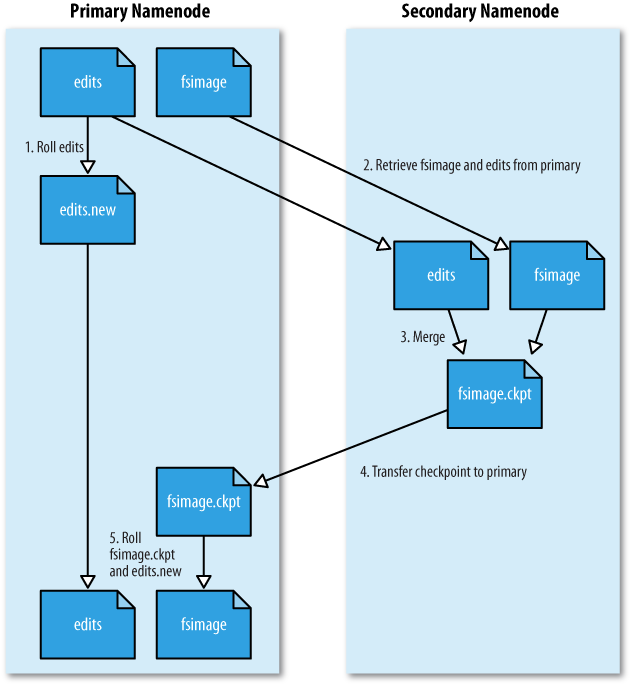
我们知道FSImage是格式化时生成的或者由NameNode定期在后台checkpoint出来的,不是每次操作都涉及到FSImage的变化;而EditLog是与client的每次RPC操作紧密相关的,每次EditOp的变化也是与我们前面提到的transactionId的变化紧密相关的。那么在我们格式化完NameNode之后,启动NameNode时,这个EditLog的状态是怎么变换的就比较重要了。
在正常启动NameNode时,函数调用关系是:
NameNode.main()->NameNode.createNameNode()->NameNode.NameNode()->NameNode.initialize()->NameNode.loadNamesystem()->FSNamesystem.loadFromDisk()
在FSNamesystem.loadFromDisk()函数中同样会new FSImage和FSNamesystem对象,和前面讲format的流程是一样的。不同的是在这之后会调用Namesystem.loadFSImage(startOpt,fsImage, HAUtil.isHAEnabled(conf,nameserviceId))来加载已有的文件系统镜像。
void loadFSImage(StartupOption startOpt, FSImage fsImage, boolean haEnabled)
throws IOException {
// format before starting up if requested
if (startOpt == StartupOption.FORMAT) {
fsImage.format(this, fsImage.getStorage().determineClusterId());
startOpt = StartupOption.REGULAR;
}
boolean success = false;
writeLock();
try {
// We shouldn't be calling saveNamespace if we've come up in standby state.
MetaRecoveryContext recovery = startOpt.createRecoveryContext();
//这个fsImage.recoverTransitionRead()函数首先会做些update,import,rollback方面的工作。
//对于我们这种启动参数regular的,会调用FsImage.loadFSImage()函数。
if (fsImage.recoverTransitionRead(startOpt, this, recovery) && !haEnabled) {
fsImage.saveNamespace(this);
}
// This will start a new log segment and write to the seen_txid file, so
// we shouldn't do it when coming up in standby state
// 非HA模式下,因为在前面format的时候已经调用了initJournalsForWrite,
// EditLog进入State.BETWEEN_LOG_SEGMENTS状态。
// 在此函数里进一步更改状态进入State.IN_SEGMENT状态。
// 在HA模式,这个状态变化在FSNamesystem.startActiveServices()这个函数中。
if (!haEnabled) {
fsImage.openEditLogForWrite();
}
success = true;
} finally {
if (!success) {
fsImage.close();
}
writeUnlock();
}
dir.imageLoadComplete();
}
其中fsImage.recoverTransitionRead(startOpt, this, recovery)会调用到FsImage.loadFSImage()函数。这个FsImage.loadFSImage()函数选择最新的image文件加载并与在它之后生产的EditLog文件merge成新的FSImage文件。
boolean loadFSImage(FSNamesystem target, MetaRecoveryContext recovery)
throws IOException {
FSImageStorageInspector inspector = storage.readAndInspectDirs();
isUpgradeFinalized = inspector.isUpgradeFinalized();
//真正调用的是FSImageTransactionalStorageInspector.getLastestImage()获取最新的Image
FSImageStorageInspector.FSImageFile imageFile
= inspector.getLatestImage();
boolean needToSave = inspector.needToSave();
Iterable editStreams = null;
if (editLog.isOpenForWrite()) {
// We only want to recover streams if we're going into Active mode.
editLog.recoverUnclosedStreams();
}
if (LayoutVersion.supports(Feature.TXID_BASED_LAYOUT,
getLayoutVersion())) {
// If we're open for write, we're either non-HA or we're the active NN, so
// we better be able to load all the edits. If we're the standby NN, it's
// OK to not be able to read all of edits right now.
long toAtLeastTxId = editLog.isOpenForWrite() ? inspector.getMaxSeenTxId() : 0;
// 选择从imageFile.getcheckpointTxId()+1到toAtLeastTxId这些TxId所对应的EditLog文件
// 作为与当前FSImage文件merge的输入流
editStreams = editLog.selectInputStreams(imageFile.getCheckpointTxId() + 1,
toAtLeastTxId, false);
} else {
editStreams = FSImagePreTransactionalStorageInspector
.getEditLogStreams(storage);
}
LOG.debug("Planning to load image :\n" + imageFile);
for (EditLogInputStream l : editStreams) {
LOG.debug("\t Planning to load edit stream: " + l);
}
try {
StorageDirectory sdForProperties = imageFile.sd;
storage.readProperties(sdForProperties);
if (LayoutVersion.supports(Feature.TXID_BASED_LAYOUT,
getLayoutVersion())) {
// For txid-based layout, we should have a .md5 file
// next to the image file
// 这个函数调用FSImage的loader(FSImageFormat.load()函数)加载文件系统元数据到内存中
loadFSImage(imageFile.getFile(), target, recovery);
} else if (LayoutVersion.supports(Feature.FSIMAGE_CHECKSUM,
getLayoutVersion())) {
// In 0.22, we have the checksum stored in the VERSION file.
String md5 = storage.getDeprecatedProperty(
NNStorage.DEPRECATED_MESSAGE_DIGEST_PROPERTY);
if (md5 == null) {
throw new InconsistentFSStateException(sdForProperties.getRoot(),
"Message digest property " +
NNStorage.DEPRECATED_MESSAGE_DIGEST_PROPERTY +
" not set for storage directory " + sdForProperties.getRoot());
}
loadFSImage(imageFile.getFile(), new MD5Hash(md5), target, recovery);
} else {
// We don't have any record of the md5sum
loadFSImage(imageFile.getFile(), null, target, recovery);
}
} catch (IOException ioe) {
FSEditLog.closeAllStreams(editStreams);
throw new IOException("Failed to load image from " + imageFile, ioe);
}
//在这从我们找到的editStreams输入流中输入EditLog并且在内存中merge成新的FSImage
long txnsAdvanced = loadEdits(editStreams, target, recovery);
//如果上一步merge了新的EditLog,就需要持久化到硬盘成新的FSImage。
needToSave |= needsResaveBasedOnStaleCheckpoint(imageFile.getFile(),
txnsAdvanced);
editLog.setNextTxId(lastAppliedTxId + 1);
return needToSave;
}
这里面很重要的就是transactionId是怎么变化的。在format之后,文件系统的元数据目录/dfs/name/current下是这样的结构:
Seen_txid就是存放transactionId的文件,format之后是0。但是当文件系统运行了一段时间之后,就会变成类似的样子:
这时候seen_txid里存放的数据时65,也就是现在正在进行的EditOp的txid是65。
然后看看在非HA模式下EditLog是怎么从State.BETWEEN_LOG_SEGMENTS到State.IN_SEGMENT转化的。这个过程是通过openEditLogForWrite()这个函数完成的。
void openEditLogForWrite() throws IOException {
assert editLog != null : "editLog must be initialized";
//这个函数负责检查transactionId的合法性,并打开edits_*****文件输出流
editLog.openForWrite();
//既然上面已经打开了一个editlog输出流,那么需要把当前的transactionId写到seen_txid文件中。
storage.writeTransactionIdFileToStorage(editLog.getCurSegmentTxId());
};
synchronized void openForWrite() throws IOException {
Preconditions.checkState(state == State.BETWEEN_LOG_SEGMENTS,
"Bad state: %s", state);
//getLastWrittenTxId获取已经写到日志文件中的最后的transactionId,
//对于上图中的例子返回的是64(不是65),segmentTxId是65
long segmentTxId = getLastWrittenTxId() + 1;
// Safety check: we should never start a segment if there are
// newer txids readable.
// 要检查有没有比segmentTxId更大的Id已经写到日志了,因为我们要开始一个以segmentTxId为开始的
// segment,如果有更大的Id已经写到日志就会出现两个日志TxId交叉的情况。
// 下面这行函数就是通过提供segmentTxId看是否有edits_******的文件中包含这个transactionId的,
// 如果有的话就说明不能以这个Id开始一个editlog segment
EditLogInputStream s = journalSet.getInputStream(segmentTxId, true);
try {
Preconditions.checkState(s == null,
"Cannot start writing at txid %s when there is a stream " +
"available for read: %s", segmentTxId, s);
} finally {
IOUtils.closeStream(s);
}
// 到这了,说明可以以segmentTxId为起点开启一个edits_*****的文件。
startLogSegmentAndWriteHeaderTxn(segmentTxId);
assert state == State.IN_SEGMENT : "Bad state: " + state;
}
在startLogSegmentAndWriteHeaderTxn这个函数里面,EditLog的状态从BETWEEN_LOG_SEGMENTS转化成了IN_SEGMENT状态,并且开启了与对应的edits_*****的文件输出流。然后把我们的这个开启日志段(OP_START_LOG_SEGMENT)的操作记录在这个流对应的文件中。
synchronized void startLogSegmentAndWriteHeaderTxn(final long segmentTxId
) throws IOException {
startLogSegment(segmentTxId);
logEdit(LogSegmentOp.getInstance(cache.get(),
FSEditLogOpCodes.OP_START_LOG_SEGMENT));
logSync();
}
前面已经说过,对于开启HA模式的EditLog的状态变化是在startActiveServices函数中完成的。所以在startActiveServices这个函数之后,EditLog文件就进入IN_SEGMENT状态,可以接受写入了。那么这个时候NameNode就可以接收来自client和DataNode的RPC请求并执行这些操作了。
void startActiveServices() throws IOException {
LOG.info("Starting services required for active state");
writeLock();
try {
FSEditLog editLog = dir.fsImage.getEditLog();
if (!editLog.isOpenForWrite()) {
//由于在initialization的时候,我们已经把共享目录下的EditLog的状态设为OPEN_FOR_READING
//所以此时必须进入这个if分支来进一步初始化editlog
editLog.initJournalsForWrite();
// May need to recover
editLog.recoverUnclosedStreams();
LOG.info("Catching up to latest edits from old active before " +
"taking over writer role in edits logs.");
editLogTailer.catchupDuringFailover();
LOG.info("Reprocessing replication and invalidation queues...");
blockManager.getDatanodeManager().markAllDatanodesStale();
blockManager.clearQueues();
blockManager.processAllPendingDNMessages();
blockManager.processMisReplicatedBlocks();
if (LOG.isDebugEnabled()) {
LOG.debug("NameNode metadata after re-processing " +
"replication and invalidation queues during failover:\n" +
metaSaveAsString());
}
long nextTxId = dir.fsImage.getLastAppliedTxId() + 1;
LOG.info("Will take over writing edit logs at txnid " +
nextTxId);
editLog.setNextTxId(nextTxId);
dir.fsImage.editLog.openForWrite();
}
if (haEnabled) {
// Renew all of the leases before becoming active.
// This is because, while we were in standby mode,
// the leases weren't getting renewed on this NN.
// Give them all a fresh start here.
leaseManager.renewAllLeases();
}
leaseManager.startMonitor();
startSecretManagerIfNecessary();
} finally {
writeUnlock();
}
}