知识图谱可视化应用研究现状文献综述
信息检索课写的一篇文献综述,这里记录一下,或许以后研究会用到
文章目录
- 摘要
- 关键词
- Abstract
- Key words
- 引言
- 知识图谱概念
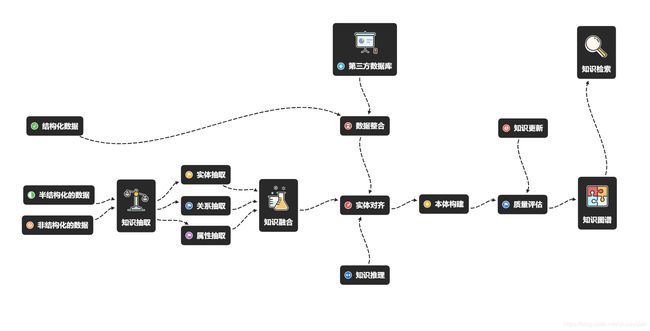
- 知识图谱可视化的构建流程及关键技术
- 1. 数据来源与处理
- 结构化数据处理
- 半结构化数据处理
- 非结构化数据处理
- 2. 知识抽取
- 实体抽取
- 关系抽取
- 属性抽取
- 3. 知识融合
- 4. 知识加工
- 5. 质量评估和知识更新
- 6. 知识图谱可视化
- 知识图谱可视化构建工具
- 知识图谱可视化应用领域
- 搜索引擎
- 知识问答
- 社交网络
- 垂直行业
- 结语
摘要
知识图谱是一种结构化的语义网络知识库,知识图谱可视化应用正在逐渐受到业界关注。简述了知识图谱的相关概念,知识图谱可视化的构建流程。总结了知识图谱可视化用到的工具及其特点。介绍了知识图谱可视化应用领域,并分析了知识图谱的未来发展方向和挑战。
关键词
知识图谱可视化;数据可视化;本体可视化;可视化分析
Abstract
Knowledge graph is a structured semantic network knowledge base, and the application of knowledge graph visualization is gradually gaining attention in the industry. The related concepts of knowledge graph and the construction process of knowledge graph visualization are briefly described. Summarizes the tools and characteristics of knowledge graph visualization. The application field of knowledge graph visualization is introduced, and the future development direction and challenges of knowledge graph are analyzed.
Key words
Knowledge graph visualization; data visualization; ontology visualization; visual analysis
引言
随着人工智能的发展以及大数据时代的到来,人类对知识的需求急剧增加。如何才能让用户在最短的时间内,理解他想要了解的知识逐渐成为一项人类想要解决的难题。2012年,Google公司提出了知识图谱的概念,目的是为了构建下一代搜索引擎。其中所用的知识图谱技术受到业界越来越多人的关注,并逐渐应用到社交网络,搜素引擎、金融、医疗、电商等各个领域。
知识图谱概念
知识图谱(Knowledge Graph),从本质上来说就是语义网络(semantic Network)的知识库,也就是说是一种用来揭示实体之间关系的语义网络。知识是对外部客观规律的归纳和总结,图在数据结构中有节点和边构成。在知识图谱中,将一切事物看成实体,以图的形式来表现来表现各种实体或概念及其关系。图的节点表示实体或者概念,边表示属性或者关系。一个知识可以通过关键词提取抽象成一个三元组,即(实体,关系,属性),这样可以方便知识图谱的存储和可视化展示
知识图谱可视化的构建流程及关键技术
知识图谱的构建一般有两种方式,分别为自顶向下的构建方式和自下向上的构建方式。其中,自顶向下的构建方式一般用于垂直行业知识图谱的构建,比如法律,金融,医疗等。自下向上的构建方式一般用于公共领域知识图谱的构建比如百度搜素,谷歌搜索等。垂直行业领域相关知识相对来说比较固定,数据和数据的组织方式,也相对容易分析,可以根据这些信息来设计知识图谱的数据模型。所以那些知识比较明确,数据关系比较清晰的领域比较适用自顶向下的构建方式。
公共领域的知识图谱涉及到方方面面的知识和海量的数据,不可能提前确定好数据的组织方式和整体架构,只能按照三元组(实体,关系,属性)的方式来收集海量数据,然后根据数据来进行数据建模。比如百度搜索,谷歌搜索等都属于典型的公共领域的知识图谱,因为用户想要搜索的知识千差万别,各方面的知识都有可能涉及到。随着数据的不断收集,不断提炼,知识的架构也就慢慢呈现出来,这就是自下而上的构建方式。
1. 数据来源与处理
结构化数据处理
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
针对结构化数据,通常是关系型数据库的数据,数据结构清晰,把关系型数据库中的数据转换为RDF数据(linked data),普遍采用的技术是D2R技术。D2R主要包括D2R Server,D2RQ Engine和D2RRQ Mapping语言。
半结构化数据处理
半结构化数据介于前两者之间,HTML、XML文档就属于这类,比如百度百科里的数据,一般网页中的数据,Wiki百科中数据。与结构化数据最大的区别在于,半结构化数据的模式结构和内容混在一起,没有明显的区分,也不需要预先定义数据的模式结构。所以我们在处理半结构化数据是,需要用到一定的技术比如正则表达式将其转换成结构化数据。对于有规律的一般页面也可以用正则表达式提取有用
非结构化数据处理
非结构化处理其实就是下面所说的知识抽取的内容。非结构化处理要根据不同的数据环境来采用不同的技术。比如进行关系抽取,可以用深度学习的方法,也可以用句法依存特征,来获取关系。当然,具体情境千差万别,所用方法也不尽相同,当时只要能实现知识抽取,效果不是太差,都可以算是一种方法。日常我们所见到的非结构化数据有:图片、声音、视频等
2. 知识抽取
实体抽取
实体抽取,又称实体识别(named entity recognition,NER),是指从上面收集好的数据中提取出一个个命名实体。
关系抽取
经过实体抽取后,得到的只是一个个离散的实体,他们之间还没有联系。这是我们还需要从数据中将实体之间的关系提取出来,通过关系将一个个离散的实体联系起来,这样就形成了一个网状的知识结构,这个过程称为关系抽取。
属性抽取
属性抽取是从互联网中不同的数据源来进行提炼实体的相关属性信息。比如某家公司的法人,董事长,总经理,经营业务等。
3. 知识融合
通过知识抽取,实现了从非结构化数据,半结构化数据,结构化数据获取实体、关系和实体属性的目标。但是,这些结果中不可避免会包含一定的错误信息和冗余信息,实体之间的关系也缺乏一定的逻辑性和层次性,所以就必须对这些信息进行融合。
知识融合包含两部分内容:实体链接和知识合并。通过知识融合可以消除实体的概念歧义,清理掉冗余和错误的信息。从而提高知识图谱的质量。
4. 知识加工
通过知识抽取、知识融合等操作可以得到一知识的基本事实表达。然而这些并不能达到我们想要的可视化,层次化,结构化的知识体系。所以还需要进行的知识加工。主要包括三方面内容:本体构建、知识推理和质量评估。其中,本体构建是对概念进行规范,知识推理是从已有的实体关系出发,利用计算机技术来建立实体间的新关联,从而拓展和丰富知识网络。
5. 质量评估和知识更新
质量评估就是对最后结果进行评估,将合格的结果放到知识图谱数据库中。根据不同领域的知识图谱,所用的评估方法也不相同。知识并不是一成不变的,所以对那些经过评估已经过时的信息,就有必要进行知识更新。知识更新的方式可以采用全面更新和增量更新。
6. 知识图谱可视化
经过上面一系列操作,就已经构建好知识图谱的整体框架了,最后所需的就是利用可视化技术将知识图谱可视化展现出来。目前已经成熟的数据可视化技术有d3js和nodejs等,通过这些技术可以以相当直观的方式展现用户想要的结果,通过一定的设定还可以与用户进行交互。
知识图谱可视化构建工具
主要介绍一些主流的知识图谱可视化构建工具,通过开发机构,支持格式,有无手册/帮助文档,是否开源四个方面进行比较,主要介绍下面这11种软件,即:Pajek、 Citespace、UCINET、 Bibexcel、 Gephi、 VOSviewer、VantagePoint、 Network WorkbenchTool、 Sci2Tool、 In-SPIRE、 SciMAT
| 名称 | 开发机构 | 支持格式 | 有无手册/帮助文档 | 是否开源 |
|---|---|---|---|---|
| Pajek | Ljubljana 大学(斯洛文尼亚) | 自身的I-mode 和2-mode ,UCINET 的DL 格式 genealogical 的GED 格式, MAC (Mac Molecule) 和MOL 格式文件 | 有 | 否 |
| Citespace | Drexel 大学(美国) | WOS 中的TXT 格式,用软件转化了的CSSCI 格式 | 有 | 是 |
| UCINET | Analytic Technologies | 矩阵格式 | 有 | 否 |
| Bibexcel | Umea 大学(Sweden) | WOS 中的TXT 格式,用软件转化了的CSSCI 格式 | 有 | 否 |
| Gephi | 瑞典Umea大学 | GEXF(推荐格式),GDF,GraphML,Pajek NET,DOT,CSV,UCINET 的 DL,Tulip TLP,Netdraw 的VNA,Spreadsheet(Excel) | 有 | 是 |
| VOSviewer | Leiden 大学(荷兰)CWTS 研究机构 | WOS 中的TXT 格式 | 有 | 否 |
| Vantage Point | Search Technology | 从EXCEL, ACCESS, XML 导入的文档格式 | 有 | 否 |
| Network Workbench Tool | Indiana 大学(美国) | WOS 中的TXT,bibtext 格式,graphml,.xml,Pajek .NET ,Pajek .Matrix (.mat),NWB (.nwb),TreeML (.xml),Edgelist (.edge), csv[ | 有 | 是 |
| Sci2 Tool | Indiana 大学(美国) | WOS 中的TXT,bibtext 格式,graphml,.xml,Pajek .NET ,Pajek .Matrix (.mat),NWB (.nwb),TreeML (.xml),Edgelist (.edge), csv等 | 有 | 是 |
| In-PIRE | 西北太平洋国家实验室 | excel, word, html, msclipboard, XML, pdf, DBF, SQLscript, sylk, dif ( 以ASCII 方式存储图形), CSV 等 | 有 | 否 |
| SciMAT | Granada 大学(西班牙) | WOS 中的TXT 格式和RIS 格式 | 有 | 是 |
知识图谱可视化应用领域
搜索引擎
知识图谱是Google为了构建下一代只能化搜索引擎而提出来的,所以知识图谱的应用比较广泛的领域之一就是搜索领域。Google在提出这一概念之后,便尝试利用此技术将用户想要了解的知识用知识图谱的形式来展现出来,以便提高用户体验。国内著名搜索引擎公司如百度,搜狗也相继致力于此技术的研究。从展现的结果而言,他就像是从互联网上挖出各种相关知识碎片,直接以图谱的形式展现出来,省去了用户从结果中检索,分析和整理的时间。因为经过相关研究发现,人们对图的理解能力要高出普通文本很多倍,所以,某方面而言,这种知识图谱的形式可以极大地节约了用户时间,提高了搜索引擎的效率。
知识问答
在知识问答领域,知识图谱也得到了广泛的应用,相对来说是一种比较高级的应用方式。问答系统中,不仅要识别用户提问的问题,还要精确匹配知识库中的相关答案,最后再以直观的方式展现出来。比较知名的应用比如国外苹果公司的智能语音助手Siri,为用户提供一些基本的日常解答,介绍等服务。国内小米公司的语音助手小爱同学等。
社交网络
国外著名社交网站Facebook 很早就将知识图谱应用到他们的系统中。Facebook通过知识图谱技术,将与用户相关性较高的其他用户推荐给该用户。这里的相关性比如相同的兴趣爱好,照片,地点,相关的用户,共同关注的话题等。
其他还有利用知识图谱来管理人际关系的应用,比如国外的领英,国内的脉脉。这类应用都是通过知识图谱来帮助人将认识的人或者有可能认识的人组成一个人脉关系网,从而更好地管理和利用自己的人脉资源。
垂直行业
知识图谱可以很好地表达实体之间的关系,这个关系可以是具有同样属性的是实体,也可以是上下位的实体关系。所以如果将知识图谱应用到电商领域的的推荐系统的话,推荐系统可以根据你的兴趣爱好推荐相关联的内容。比如,你买了电脑,那么它可能会给你推荐键盘,鼠标等。一般推荐可以分为上下位关联商品推荐和组合属性商品推荐。
结语
知识图谱可视化应用广泛,被大量用于金融、医疗、地理、电商等,并发挥了巨大的作用。通过知识图谱可视化应用,用户可以在最短的时间内了解某项知识,获取到精确的信息。
知识图谱可以说是一个新兴的概念,自2012年Google提出以来只有不到8年的时间,但是知识图谱却涉及了当下很多人工智能领域的研究热点,比如信息检索、自然语言处理、深度学习。知识图谱正在逐渐受到业界越来越多人的关注。
就目前来说,知识图谱还属于成长阶段,仍然存在着许多挑战和难题没有解决。比如实时知识获取,长尾知识获取,主观知识获取等。如何更加精确理解用户的表达,用户的情感和偏好,如何更好地展示结果,跨语言检索等都有待研究。