RocketMQ原理学习--RocketMQ整体架构窥探
RocketMQ总体架构图:
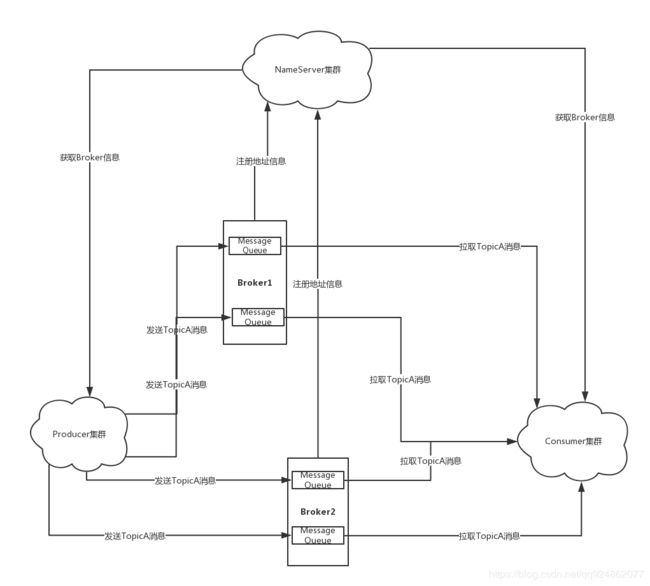 RocketMQ简单架构
RocketMQ简单架构
角色简介:
1、Name Server:简单可以理解为注册中心,Broker相关信息会注册到Name Server集群中,维护Broker及Broker中相关Topic信息,这样生产者和消费者就可以从Name Server中定时(30秒)获取相关Broker信息。
2、Broker:集群最核心模块,主要负责Topic消息存储、消费者的消费位点管理(消费进度)。
3、Producer: 消息生产者,每个生产者都有一个ID(编号),多个生产者实例可以共用同一个ID。同一个ID下所有实例组成一个生产者集群。
4、Consumer: 消息消费者,每个订阅者也有一个ID(编号),多个消费者实例可以共用同一个ID。同一个ID下所有实例组成一个消费者集群。
Name Server
Namesrv用于存储Topic、Broker关系信息,功能简单,稳定性高。多个Namesrv之间相互没有通信,单台Namesrv宕机不影响其他Namesrv与集群;即使整个Namesrv集群宕机,已经正常工作的Producer,Consumer,Broker仍然能正常工作,但新起的Producer, Consumer,Broker就无法工作。
Namesrv压力不会太大,平时主要开销是在维持心跳和提供Topic-Broker的关系数据。但有一点需要注意,Broker向Namesr发心跳时,会带上当前自己所负责的所有Topic信息,如果Topic个数太多(万级别),会导致一次心跳中,就Topic的数据就几十M,网络情况差的话,网络传输失败,心跳失败,导致Namesrv误认为Broker心跳失败。
Broker
1、高并发读写服务
Broker的高并发读写主要是依靠以下两点:
消息顺序写:所有Topic数据同时只会写一个文件,一个文件满1G,再写新文件,真正的顺序写盘,使得发消息TPS大幅提高。
消息随机读:RocketMQ尽可能让读命中系统pagecache,因为操作系统访问pagecache时,即使只访问1K的消息,系统也会提前预读出更多的数据,在下次读时就可能命中pagecache,减少IO操作。
2、负载均衡与动态伸缩
负载均衡:在Broker上一个Topic会对应几个MessageQueue(默认每个Broker上会创建4个MessageQueue),生产者在发送消息时默认采用轮询方式将消息依次发送到各个MessageQueue中。
动态伸缩能力:消息会发送到不同Broker的同一个Topic的MessageQueue中,因此可以进行Broker的动态修改。
3、高可用&高可靠
高可用:集群部署时一般都为主备,备机实时从主机同步消息,如果其中一个主机宕机,备机提供消费服务,但不提供写服务。
高可靠:所有发往broker的消息,有同步刷盘和异步刷盘机制;同步刷盘时,消息写入物理文件才会返回成功,异步刷盘时,只有机器宕机,才会产生消息丢失,broker挂掉可能会发生,但是机器宕机崩溃是很少发生的,除非突然断电
4、Broker与Namesrv的心跳机制
单个Broker跟所有Namesrv保持心跳请求,心跳间隔为30秒,心跳请求中包括当前Broker所有的Topic信息。Namesrv会反查Broer的心跳信息,如果某个Broker在2分钟之内都没有心跳,则认为该Broker下线,调整Topic跟Broker的对应关系。但此时Namesrv不会主动通知Producer、Consumer有Broker宕机。
消费者
消费者启动时需要指定Namesrv地址,与其中一个Namesrv建立长连接。消费者每隔30秒从nameserver获取所有topic的最新队列情况,这意味着某个broker如果宕机,客户端最多要30秒才能感知。连接建立后,从namesrv中获取当前消费Topic所涉及的Broker,直连Broker。
Consumer跟Broker是长连接,会每隔30秒发心跳信息到Broker。Broker端每10秒检查一次当前存活的Consumer,若发现某个Consumer 2分钟内没有心跳,就断开与该Consumer的连接,并且向该消费组的其他实例发送通知,触发该消费者集群的负载均衡。
消费者端的负载均衡
先讨论消费者的消费模式,消费者有两种模式消费:集群消费,广播消费。
广播消费:每个消费者消费Topic下的所有队列。
集群消费:一个topic可以由同一个ID下所有消费者分担消费。具体例子:假如TopicA有6个队列,某个消费者ID起了2个消费者实例,那么每个消费者负责消费3个队列。如果再增加一个消费者ID相同消费者实例,即当前共有3个消费者同时消费6个队列,那每个消费者负责2个队列的消费。
消费者端的负载均衡,就是集群消费模式下,同一个ID的所有消费者实例平均消费该Topic的所有队列。
目前RocketMQ提供了消费者两种获取消息的方式:Pull和Push(实际都是Consumer拉取消息)
Pull模式:Pull方式里,取消息的过程需要用户自己写,首先通过打算消费的Topic拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每个MessageQueue批量取消息,一次取完后,记录该队列下一次要取的开始offset,直到取完了,再换另一个MessageQueue。
Push模式:Push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
生产者(Producer)
Producer启动时,也需要指定Namesrv的地址,从Namesrv集群中选一台建立长连接。如果该Namesrv宕机,会自动连其他Namesrv。直到有可用的Namesrv为止。
生产者每30秒从Namesrv获取Topic跟Broker的映射关系,更新到本地内存中。再跟Topic涉及的所有Broker建立长连接,每隔30秒发一次心跳。在Broker端也会每10秒扫描一次当前注册的Producer,如果发现某个Producer超过2分钟都没有发心跳,则断开连接。
生产者端的负载均衡
1、生产者发送时,会自动轮询当前所有可发送的broker中的MessageQueue,一条消息发送成功,下次换另外一个broker发送,以达到消息平均落到所有的broker上。
2、由于生产者默认的负载均衡策略是轮询,如果想要修改这种策略可以实现MessageQueueSelector接口,例如顺序消息的实现就可以依赖MessageQueueSelector来实现。
这里需要注意一点:假如某个Broker宕机,意味生产者最长需要30秒才能感知到。在这期间会向宕机的Broker发送消息。当一条消息发送到某个Broker失败后,会往该broker自动再重发2次,假如还是发送失败,则抛出发送失败异常。业务捕获异常,重新发送即可。客户端里会自动轮询另外一个Broker重新发送,这个对于用户是透明的。
参考:
https://blog.csdn.net/yhl_jxy/article/details/77512226
https://blog.csdn.net/javahongxi/article/details/72956608