格雷码+相移法的捕获图像解码详解与实现(C++)
DLP将格雷码图案投射到物体上,利用相机捕获被深度调制后的格雷码图案。
相机拍摄的是 u,v 两个方向的系列照片,其中投射图案 u,v 方向均为9级格雷码图案,如下图:
 相机拍摄系列照片
相机拍摄系列照片
解码原理:
格雷码向二进制码转换
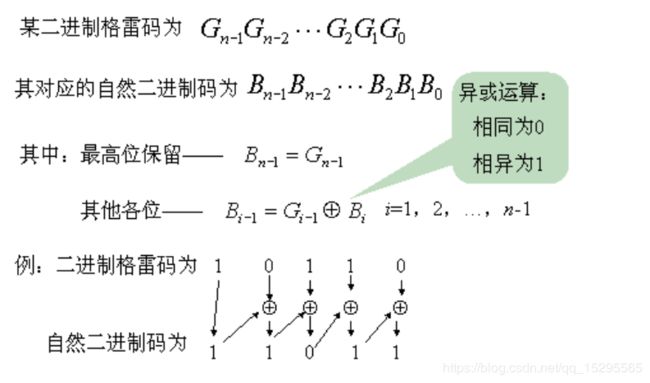
根据图示例子可知:
格雷码向二进制码转换时:
(1)保留二进制码的最高位(也就是二进制码最左边的一位)为格雷码的最高位(第1位);
(2)第2位为二进制的第2位与格雷码的第1位的异或,第3位为二进制的第3位与格雷码的第2位的异或,依次类推直到
格雷码的最后1位为二进制的最后1位与格雷码的倒数第2位的异或。
根据二进制格雷码转换成自然二进制码的法则,可以得到以下的三种代码方式:
static unsigned int GraytoDecimal(unsigned int x)
{
unsigned int y = x;
while(x>>=1)
y ^= x;
return y;
}
static unsigned int GraytoDecimal(unsigned int x)
{
x^=x>>16;
x^=x>>8;
x^=x>>4;
x^=X>>2;
x^=x^1;
return x;
}
static unsigned int GraytoDecimal(unsigned int x)
{
int i;
for(i=0;(1<>(1< 拍摄格雷码图案的解码
如果待测物体上被投影条纹覆盖的区域上有一点 P(实际物体上的点),所对应的拍摄照片上的点的坐标为 Pc(uc,vc),并假设 P 点接收来自投影仪的光是由投影仪图案上的点 Pp(up.vp) 所投射出来的,则解码过程主要分为如下两步:
(1)对拍摄的系列照片通过阈值处理进行二值化,如下图所示,然后对 Pc 点在两个系列每一级的照片中进行黑白判定,黑为0值,白为1值,并按照对应投射图案的先后顺序组合得到两组格雷码,其中 u 方向得到 Cu 值,v 方向得到 Cv 值。
(2)由于投影图案上的每一个像素点与 Cu 和 Cv 值有一一对应,则由 Pc 点确定的 Cu 值和 Cv 值,便得出其对应在投影图案上的 Pp 点,将 Pc 点的 Cu 和 Cv 值分别先转换为二进制数,再转换为十进制数,便是 Pp 点在投影图案上的像素坐标 (up,vp)。解码过程如下图示:

(3)由 P 点对应在照片和投影图案上的两个像素坐标得到 P 点的三维坐标需要将系统的标定结果带入计算,如下三维坐标求解示意图。
 三维坐标求解示意图
三维坐标求解示意图
编解码是成对出现的,知道怎么编码才会在解码的时候更加自如,也理解的更透彻。
编码的博文和代码实现我在前面的博文中已经写过:
结构光之格雷码编码加相移算法详解与实现(多种编码程序)
代码详解:
下面是针对解码的程序作出详解,代码如下:
int decodeGrayCodes(int proj_width, int proj_height,
IplImage**& gray_codes,
IplImage*& decoded_cols,
IplImage*& decoded_rows,
IplImage*& mask,
int& n_cols, int& n_rows,
int& col_shift, int& row_shift,
int sl_thresh){
// Extract width and height of images. 由相机拍摄的第一张图像,获取其高和宽
int cam_width = gray_codes[0]->width;
int cam_height = gray_codes[0]->height;
// Allocate temporary variables.
IplImage* gray_1 = cvCreateImage(cvSize(cam_width, cam_height), IPL_DEPTH_8U, 1); //格雷码图1
IplImage* gray_2 = cvCreateImage(cvSize(cam_width, cam_height), IPL_DEPTH_8U, 1);
IplImage* bit_plane_1 = cvCreateImage(cvSize(cam_width, cam_height), IPL_DEPTH_8U, 1);
IplImage* bit_plane_2 = cvCreateImage(cvSize(cam_width, cam_height), IPL_DEPTH_8U, 1); //位平面
IplImage* temp = cvCreateImage(cvSize(cam_width, cam_height), IPL_DEPTH_8U, 1); //图像的临时存储变量
// Initialize image mask (indicates reconstructed pixels). 初始化图像的掩码
cvSet(mask, cvScalar(0)); //对mask图像中的像素设置值为 0
// Decode Gray codes for projector columns. 为投影仪的列解码格雷码
cvZero(decoded_cols); //先初始化为零矩阵
for(int i=0; i0)
cvXor(bit_plane_1, bit_plane_2, bit_plane_1); //矩阵进行异或操作
else
cvCopyImage(bit_plane_2, bit_plane_1); //bit_plane_2复制到了bit_plane_1,cvCopyImage使用时目标矩阵必须提前分配内存
cvAddS(decoded_cols, cvScalar(pow(2.0,n_cols-i-1)), decoded_cols, bit_plane_1); //图像加常量
}
cvSubS(decoded_cols, cvScalar(col_shift), decoded_cols); //矩阵和值做减法 decoded_cols = decoded_cols - cvScalar(col_shift)
// Decode Gray codes for projector rows.
cvZero(decoded_rows);
for(int i=0; i0)
cvXor(bit_plane_1, bit_plane_2, bit_plane_1);
else
cvCopyImage(bit_plane_2, bit_plane_1);
cvAddS(decoded_rows, cvScalar(pow(2.0,n_rows-i-1)), decoded_rows, bit_plane_1);
}
cvSubS(decoded_rows, cvScalar(row_shift), decoded_rows);
// Eliminate invalid column/row estimates.
// Note: This will exclude pixels if either the column or row is missing or erroneous.
cvCmpS(decoded_cols, proj_width-1, temp, CV_CMP_LE);
cvAnd(temp, mask, mask);
cvCmpS(decoded_cols, 0, temp, CV_CMP_GE);
cvAnd(temp, mask, mask);
cvCmpS(decoded_rows, proj_height-1, temp, CV_CMP_LE);
cvAnd(temp, mask, mask);
cvCmpS(decoded_rows, 0, temp, CV_CMP_GE);
cvAnd(temp, mask, mask);
cvNot(mask, temp);
cvSet(decoded_cols, cvScalar(NULL), temp);
cvSet(decoded_rows, cvScalar(NULL), temp);
// Free allocated resources.
cvReleaseImage(&gray_1);
cvReleaseImage(&gray_2);
cvReleaseImage(&bit_plane_1);
cvReleaseImage(&bit_plane_2);
cvReleaseImage(&temp);
// Return without errors.
return 0;
}
这里用到了拍摄的42张图像来进行解码,生成的时候是横向10张,纵向10张,全白一张,这里为什么是42张图像?原因是在投射的时候将生成的图像进行了取反,同时便生成了42张图像,为什么要有这种操作呢?
可以参考这篇文章:Robust Pixel Classification for 3D Modeling with Structured Light
这种方法被称为 Robust pixel classification.

具体可以参考我的另一篇博文: 详解结构光中的Robust pixel classification
这里可以用一张图像来进行分类,却使用了两张图案(编码图像和它的反码图案)来分类,主要是为了提高它的稳健性。
每个单张图的分类均遵循单模式的分类规则,两张图是单图案分类规则的组合扩展。单一图案的分类规则是这样的:

简单说就是:
在所有情况下,在相机像素处测量的总辐射亮度是直接成分和全局组成部分的总和:![]()
对于两张图像而言,分类规则是这样的:

程序如下:
//robust pixel classfy
unsigned short sl::get_robust_bit(unsigned value1, unsigned value2, unsigned Ld, unsigned Lg, unsigned m)
{
if (Ld < m) //ld——d
{
return BIT_UNCERTAIN;
}
if (Ld>Lg)
{
return (value1>value2 ? 1 : 0);
}
if (value1<=Ld && value2>=Lg)
{
return 0;
}
if (value1>=Lg && value2<=Ld)
{
return 1;
}
return BIT_UNCERTAIN;
}value1和value2分别为逐像素遍历图像1和图像2(1的反码图像)的灰度值,m为阈值,Ld为直接分量,Lg为全局分量。

下面是Ld和Lg的计算方法。

如果场景点位于阴影的本影内,则由于源而没有直接贡献,因此在b = 0.设Lmax和Lmin是在捕获的视频中的场景点处观察到的最大和最小亮度。
通过上式可直接进行分类,然后将分类后的格雷码通过常规方法转化为二进制码即可。