python实现广义线性模型
广义线性模型()
核心就是最小二乘法,最小二乘法简而言之就是求较小值,在极小值的时候值最小,一阶导数为0.

import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
def main():
# 加载 diabetes 数据集
diabetes = datasets.load_diabetes()
# 仅使用第一个特征
diabetes_X = diabetes.data[:, np.newaxis, 2]
# 把数据划分成训练集和测试集x
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# 把目标值划分成对应的训练集和测试集y
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# 实例化一个 线性回归类的模型
regr = linear_model.LinearRegression()
# 在训练集上训练模型
regr.fit(diabetes_X_train, diabetes_y_train)
# 在测试集上进行预测
diabetes_y_pred = regr.predict(diabetes_X_test)
# 线性模型的系数
print('Coefficients: \n', regr.coef_)
# 均方误差
print("Mean squared error: %.2f"
% mean_squared_error(diabetes_y_test, diabetes_y_pred))
# 解释方差: 1 代表完美预测
print('Variance score: %.2f' % r2_score(diabetes_y_test, diabetes_y_pred))
# 绘制输出结果
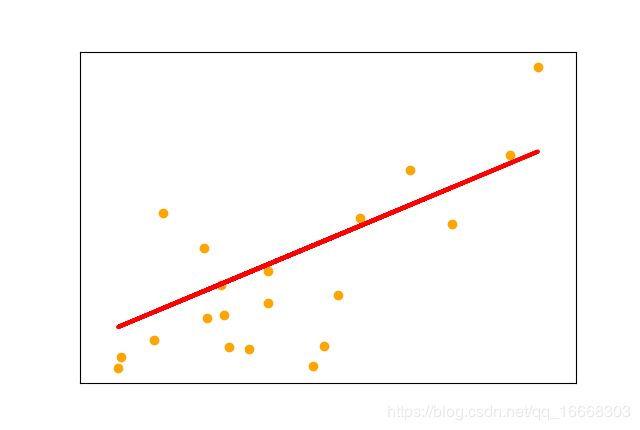
plt.scatter(diabetes_X_test, diabetes_y_test, color='orange')
plt.plot(diabetes_X_test, diabetes_y_pred, color='red', linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
if __name__=='__main__':
main()
运行结果